L3-Process
연세대학교 차호정 교수님의 운영체제 강의를 듣고 작성한 강의록
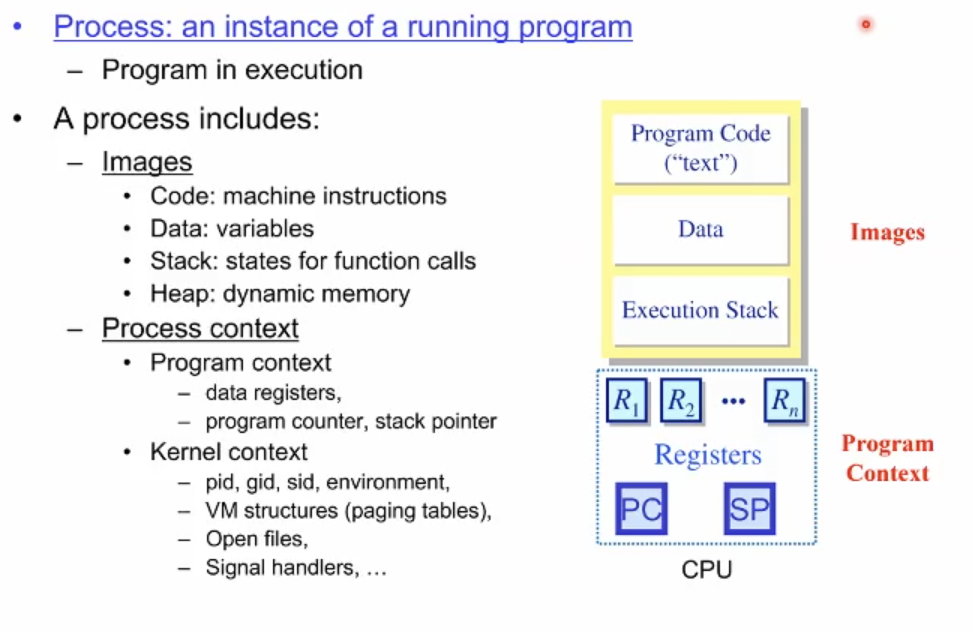
프로세스라는 것은 실행중인 프로그램의 인스턴스(사례,경우)이다. 즉 수행중인 프로그램이 프로세스다.
그렇다면 프로그램이란 것은? Passive한 개념 코드
내가 짠 hello.c라는 코드는 소스프로그램이라고 부른다. gcc로 컴파일하면 a.out이라는 프로그램이 나오는데 이것은 binary executable 프로그램이다. 프로그램이라는 것은 하드디스크, 메모리에 저장이 가능하다. 이모든 것이 바로 다 일종의 passive 한 객체이고 이를 프로그램이라고 칭한다.
헌데 프로세스라는 것은 살아있는 주체이다. 다시말하면 수행중인 프로그램. 프로그램이 살아있다는 것은 코드가 메인 메모리에 올라와서 cpu가 제어할 수 있는 일종의 형태, 대상이 되어야한다. 폰 노이만 컨셉에 따라, 우리가 짠 코드는 항상 램에 stored되어있으며 CPU는 한번에 하나씩 가져와서 처리하고 결과를 저장한다. (물론 그 전에는 하드 스토리지에 있을 것이다)
프로그램은 하드 디스크에 있으며 생명력이 없다. 우리의 OS 운영체제가 램에 프로그램을 올려 cPU가 일을 처리할 수 있도록 처리해준다.
|| 프로세스란 || 램에 존재하는 프로그램의 이미지의 모습과 os가 인지하는 추가적인 정보를 합쳐서 개념적으로 프로세스라고 한다.
프로그램의 이미지 + 프로세스 컨텍스트(이미지를 컨트롤하기 위한 추가적인 메타데이터들)
좀더 테크니컬하게 들어가보자.
프로세스는 크게 1. Image 2. Context로 구성되어 있다. 이것이 운영체제 관점에서의 프로세스의 정의다.
-
이미지
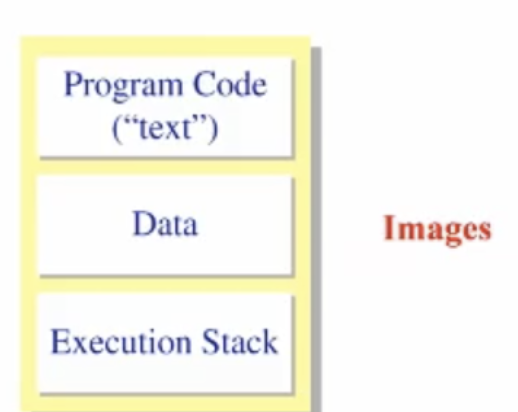
우리가 짠 코드가 컴파일 과정을 거치게 되면 위의 형태로 바뀌게 된다.
코드 : 컴파일된 코드, 명령어 집합
데이터: 메인 함수 밖에 글로벌 자료구조를 정의한 것을 모아서 데이터 이미지, 공간을 만든다.
-
-
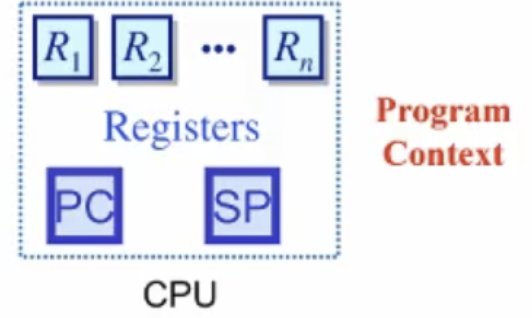
데이터 레지스터, 프로그램 카운터, 스택 포인터(stack의 top을 가리키는 포인터)
-
Kernel Context(위 슬라이드에는 그림이 없음) PID, GID, SID environment, VM structures, Open files 등등
-
프로세스 Layout
Process Layout - 이미지
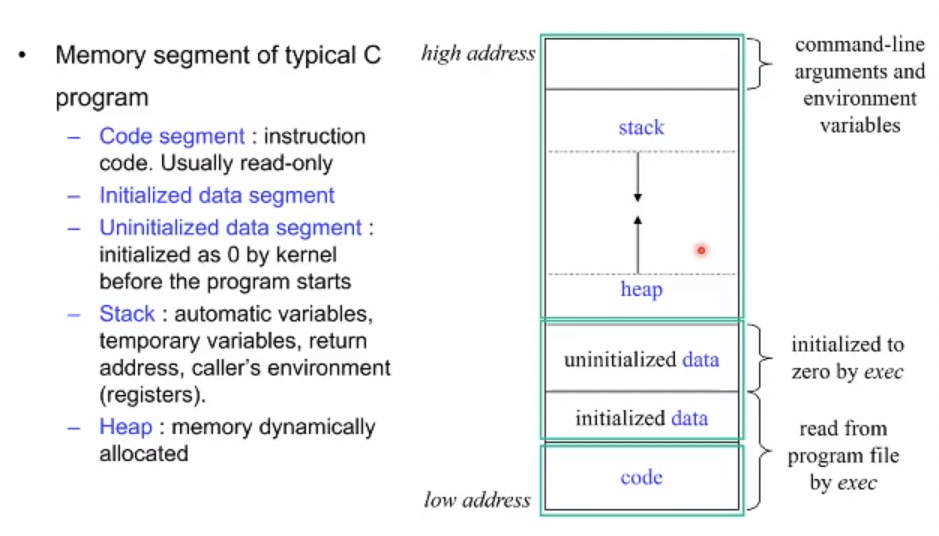
프로세스의 이미지는 아래의 모든 것들을 가지고 있어야 한다. 우리가 짠 코드가 이러한 이미지로 만들어져서 램에 올라가 돌아가게 된다.
Code Segment : 내가 작성한 파일이 컴파일이 되면 Code로 바뀌게 된다.
Global Data Structure: 우리가 Declare한 자료구조
구체적인 예시를 살펴보자
내가 짠 코드가 어떻게 내부적으로 구성되고 수행될까?
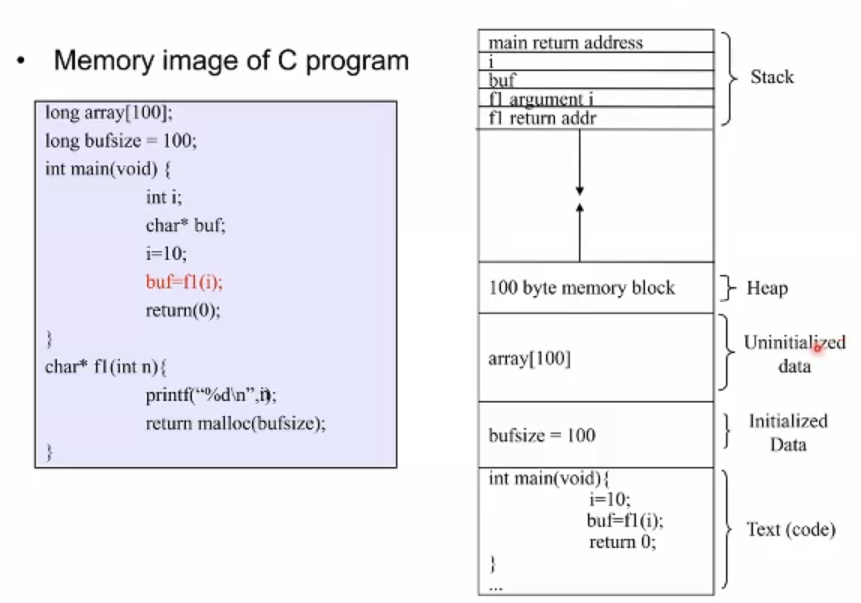
위 코드는 메인 함수, 메인함수가 호출하는 f1이라는 함수(서브루틴)가 있다. Array 와 BufSize라는 전역변수가 있다. 그리고 그 내부적으로는 i, buf, n등 로컬 변수가 존재한다.
컴파일러는 이 코드를 실행 가능한 binary 파일, 즉 프로세스 이미지로 바꾸게 된다. 그것이 바로 오른쪽의 그림이다.
- 가장 아래부터 살펴보면 Code 가 위치한다. (실제로는 binary의 형태이지만 그림에서는 고수준 언어로 묘사)
- 그 위로 두 개 영역이 존재하는데 전역변수의 공간이다. 선언이 된 변수인 bufsize, 그리고 선언이 안된 array가 존재한다.
- 그 다음은 충분한 크기의 빈 메모리 공간이다(스택과 힙 영역)
또 봐야할 것이 프로세스의 이미지가 linear한 주소를 가지고 있다는 점이다. 그림에서는 위가 high, 아래가 low를 의미하고 있다. 32비트 아키텍쳐에서 프로세스가 지원할 수 있는 주소의 최대값은 2^32, 즉 4G이다. 즉 아키텍쳐에 따라서 프로세스가 정의할 수 있는 주소 공간의 범위가 달라지게 된다.
정리하면, 프로세스의 Linear Address는 CPU 아키텍쳐에 따라 달라진다. 우리가 으레 말하는 컴퓨터 스펙의 램 사이즈는 Physical Memory, Physical Address이다.
→ 그렇다면, physical memory의 용량과 실제 프로세스가 가질 수 있는 주소 공간 범위가 다르다는 것은 무슨 얘기인가? 만일 physical memory 가 1G이고 32비트 아키텍쳐라면, 어떻게 최대 4G의 주소공간을 가지는 프로세스 이미지를 실행시킬 수 있을까? 이것을 가능하게 하는 것이 virtual memory라는 기술이다. Linear Address를 Physical Memory로 Translate하는 기술이다.
우선은 이정도까지만 Linear Address내용은 넘어가자.
다시 돌아가서, Linear Address는 CPU가 Program Counter로 Address할 수 있는 주소공간, 범위이다. 즉 CPU가 이 프로세스 이미지를 실행시킬 때 Program Counter가 Linear Address 의 제한된 공간을 왔다 갔다 하면서 그 위치의 값을 불러오거나 변경하거나 등을 하며 프로세스를 수행하는 것이다.
맨 처음에 프로그램 카운터는 main함수의 첫 줄, i = 10; 에서 시작할 것이다. 로컬 변수인 i를 선언하는 코드이며 이 i라는 변수는 바로 스택에 저장되게된다. 전역변수 위로 존재하는 빈 메모리 공간의 맨 위부터 할당된 공간까지를 stack이라고 한다. 스택에 저장된 값들을 CPU가 불러오거나 삭제하거나 변경하기 위해 존재하는 Pointer가 바로 Stack Pointer이다.
서브루틴인 f1이 시작되면 f1의 파라미터, 리턴 값은 어떻게 전달될까? 이것도 역시 스택으로 전달된다. 파라미터를 전달할 함수는 스택에 넣고 전달받아 수행할 함수는 스택에서 가져오는 것이다. 즉 스택을 매개체로 해서 파라미터를 패싱한다.
또한 서브루틴의 시작점과 반환 후 돌아갈 메인 루틴의 PC 주소 공간 역시 스택에 저장되어 관리된다.
이러한 스택은 Execution Stack, Runtime Stack이라고도 불린다.
f1의 코드에서 malloc으로 100 바이트의 주소공간을 할당받는다. 이 공간 역시 수행되는 프로세스에게 할당된 주소공간 내에서 이루어져야한다. 이러한 공간을 HEAP이라 한다. 힙은 global datastructure의 공간이 끝난 시점에서 시작해서 위로 점점 자라간다. ++ 뿐만 아니라, 우리가 코드에 사용하는 라이브러리 코드들도 이 스택과 힙 형역 사이 어딘가에 링크가되어 박혀있다.
정리하면, 완벽히 독자적으로 돌 수 있게 모든 필요한 요소들은 전부 이 이미지에 존재한다.
Process Control Structure ( Descriptor)
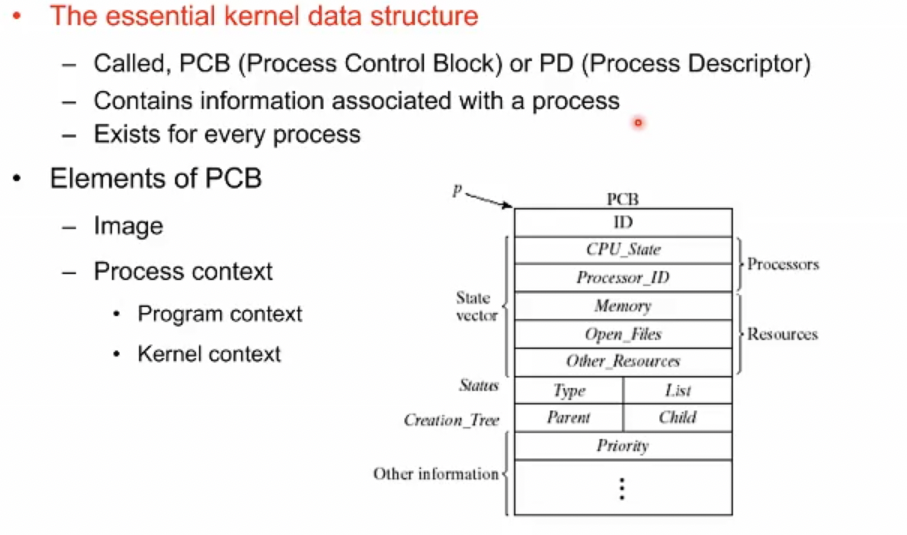
운영체제는 모든 프로세스를 관리할 수 있어야한다. 따라서 모든 프로세스는 운영체제의 관리를 위한 메타 정보가 담긴 Descriptor라는 자료구조를 갖는다. 이 메타정보의 내용은 OS가 관리해야하는 Context를 담고 있다.
Process Control Block이라고도 불린다. 이 PCB에 모든 정보를 가진다. 프로세스의 주인, 어떤 우선순위 스케줄링, 등등
예시) 리눅스 운영체제가 어떻게 개념적인 PCB를 코드로 구현하고 있는가
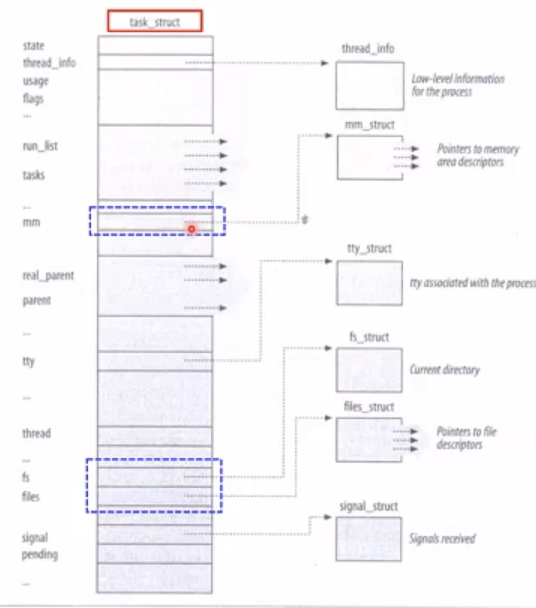
리눅스의 자료구조 중 task_struct라는 자료구조가 있다. 약 640라인으로 길며 C언어의 구조체 타입으로 정의된다.
앞서 프로세스를 정의할때 설명한 세가지 구성성분- 이미지, Program Context, Kernel Context를 한번 이 구조체 정의 코드에서 실제로 살펴보자.

mm_struct : process Image에 해당하는 자료구조이다.

Thread 자료구조 → 프로그램 컨텍스트이다. (멀티스레드의 스레드와는 다른 개념) 이 자료구조는 아키텍쳐 specific한 내용을 담고 있다. 하드웨어에 특화된 아키텍트와 관련된 정보를 담고 있다. (레지스터, pc, sc 등등)
질문) PCB 안에 왜 이런 아키텍쳐 specific한 내용의 자료구조가 있어야할까?(왜 프로그램 컨텍스트가 필요하냐) → 시스템에 프로세스는 하나만 도는게 아니다. 멀티 프로세싱을 하고 time sharing을 해야하고 커널 모드로 들어가야하기도 하고 등등 여러가지 프로세스가 수행되는 과정속에서 내 프로세스가 끝날때 까지 한번에 처음부터 끝까지 완벽하게 돌순 없다. 그 이야기는 내 프로세스가 돌아가다가 멈췄을 때 지금까지 수행했던 정보들을 저장해야한다는 소리이다. 그렇기 위해 이 프로그램 컨텍스트를 저장한다.

커널컨텍스트는 어디에?
앞서 위 두 슬라이드의 두개의 파란 박스를 제외한 모든 변수 및 구조체들이 바로 커널 컨텍스트다.
→리눅스는 프로세스를 이 task_struct라는 것을 통해 프로세스를 구현한다
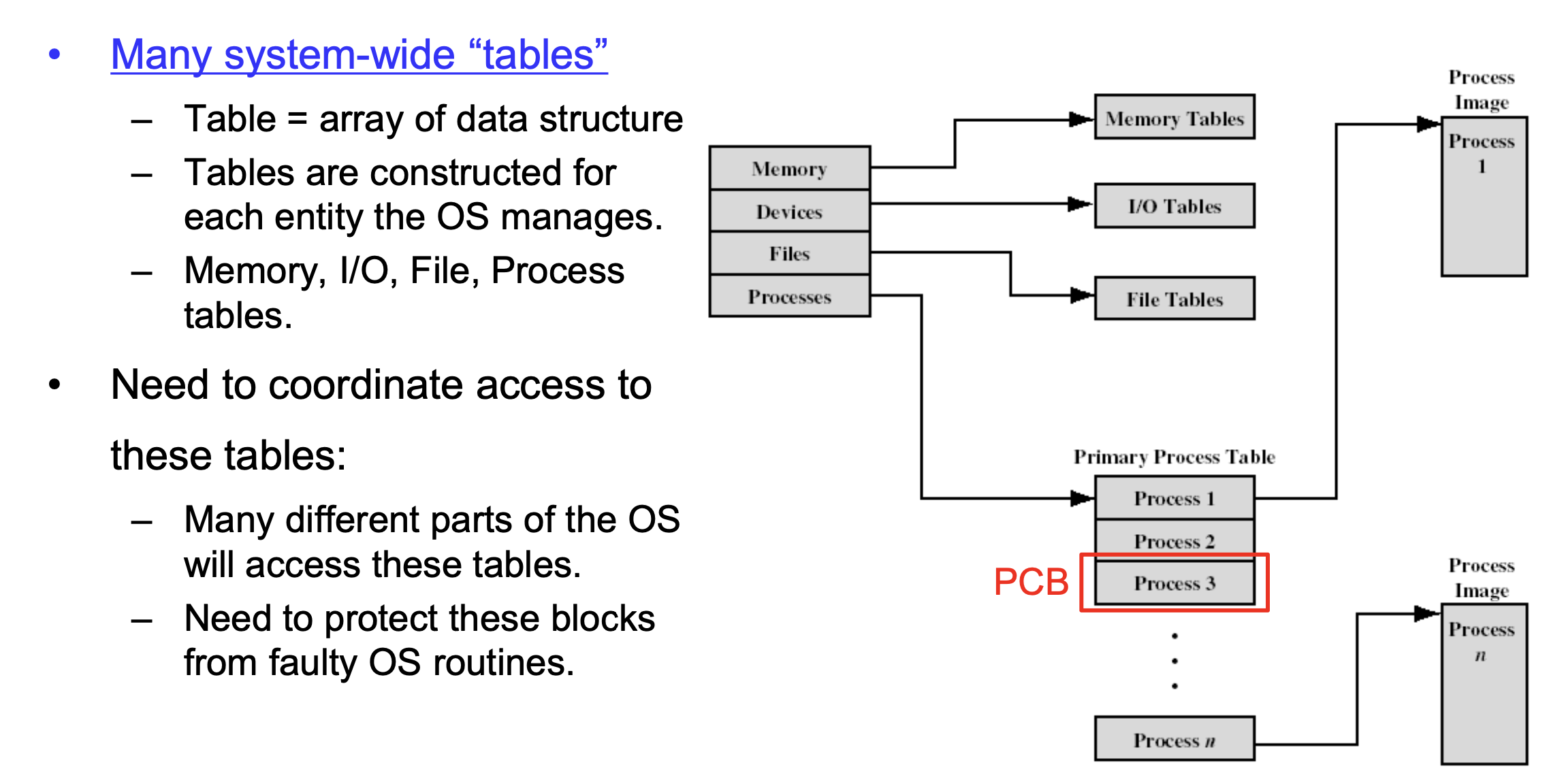
PCB처럼 운영체제는 많은 다른 자료구조를 지닌다. 메모리, IO, File 등등 많은 자료구조가 있다. 운영체제는 엄청나게 많은 테이블(자료구조)의 조합이며 모두 엮여있다.

코딩이란 무엇일까? 자료구조를 선언하고 자료구조를 계속 Update하는 것이다. 우리들의 코드가 바로 이것을 수행하게 한다. 자료를 계속 바꿔서 원하는 형태의 출력을 만든다. 프로그램 설계시 가장 먼저 고민해야할 것이 바로 자료구조를 어떻게 정의하고 사용할까 이다. 실제 코드는 자료구조의 내용을 바꾸는 것이다. 우리의 control flow가 우리가 선언한 자룍구조의 값을 바꾸는 것이다. 이것이 바로 stored program concept이라는 폰노이만 아키텍쳐의 컨셉과 일맥상통하는 이야기이다. 모든 것이 메모리에, 데이터로 존재하고 CPU가 읽어와서 수행하고 리턴한다.
Process State : generic five-state model
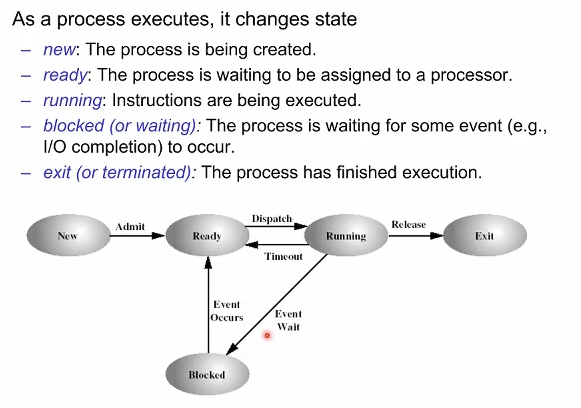
프로그램이 프로세스화 되어 실행되면 os는 여러가지 프로세스를 핸들링한다. 하나의 프로세스 관점에서 어떠한 상태변화가 있을까? 처음에 생성되어 종료될때까지 위 그림의 state들을 거쳐간다.
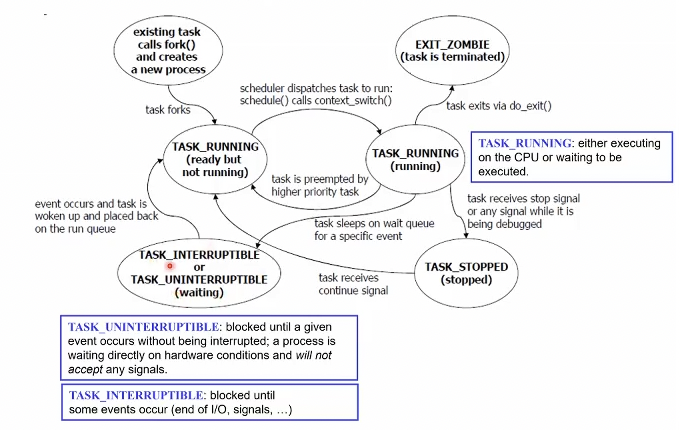
리눅스에서 정의하는 Task(프로세스)의 State들이다.
Proces State Management
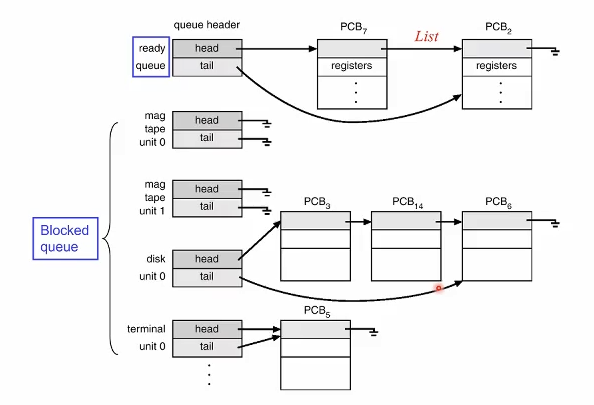
운영체제가 어떻게 프로세스들을 관리하는가
위 의 박스들이 전부 PCB를 의미한다. 맨 위가 ready queue, 밑으로는 blocked queue라고 이해하자. ready 상태의 프로세스들은 모두 ready queue에 있다 스케줄러는 위 레디큐 에있는 프로세스중 하나를 골라 CPU를 점유시키게 한다.
Process Switching

프로세스 스위칭과 모드 스위칭의 차이, 프로세스간 전환은 언제 일어나는가, 운영체제는 멀티프로세싱을 어떻게 구현해내는가
프로세스 스위칭이란 현재 돌고 있는 CPU의 Owner 프로세스를 다른 프로세스로 바꾸는 것.
모드 스위칭이란 CPU에 있는 두 가지 모드인 유저모드와 커널모드간의 전환.
전환의 한 예로 time interrupt가 있다.
CPU에게 PI chip이 주기적으로 Time Interrupt를 발생시킨다. 보통 1ms에 한번씩 interrupt 발생시킨다.(이걸 tick rate이라고 한다) 이 time interrupt가 발생하면 CPU는 유저모드에서 커널모드로 전환하여 time interrupt를 핸들하고 다시 유저모드로 돌아가 작업을 재개한다.

듀얼 모드 오퍼레이션
커널 코드가 실행되는 것이 커널 모드 오퍼레이션, 유저 코드가 실행되는 것이 유저 모드 오퍼레이션이라고 한다.
모드 오퍼레이션을 나눔으로써 유저 코드 실행과 커널코드 실행을 완벽히 분리했다. 즉 유저모드에서만 유저코드가 동작하고, 커널모드에서만 커널 코드가 동작하는 원리이다.
모드 스위칭도 결코 간단한 작업이 아니다. 현재 작동하고 있는 프로세스의 프로그램 컨텍스트를 저장하고, 커널모드로 가서 커널의 코드를 동작시킨다.

모드 스위칭이 발생하는 세가지 상황이 있다.
- Interrupt
- System Call
- Exception
프로세스 스위칭은 모드스위칭에 의해 MAY Occur이다. 즉 모드 스위치에 비해 덜 빈번하게 발생한다.

즉 Interrupt가 반드시 프로세스 스위칭을 발생시키는것은 아니다.
하지만 프로세스 스위치가 일어나려면 반드시 모드스위칭이 선행되어야한다.

모드스위칭도 간단치 않은데 프로세스 스위칭은 정말 운영체제 입장에서 골치아픈 작업이다 PCB 포인터 업데이트, state 바꾸고, 가상메모리 올리고 등등. 오버헤드가 매우 크다.
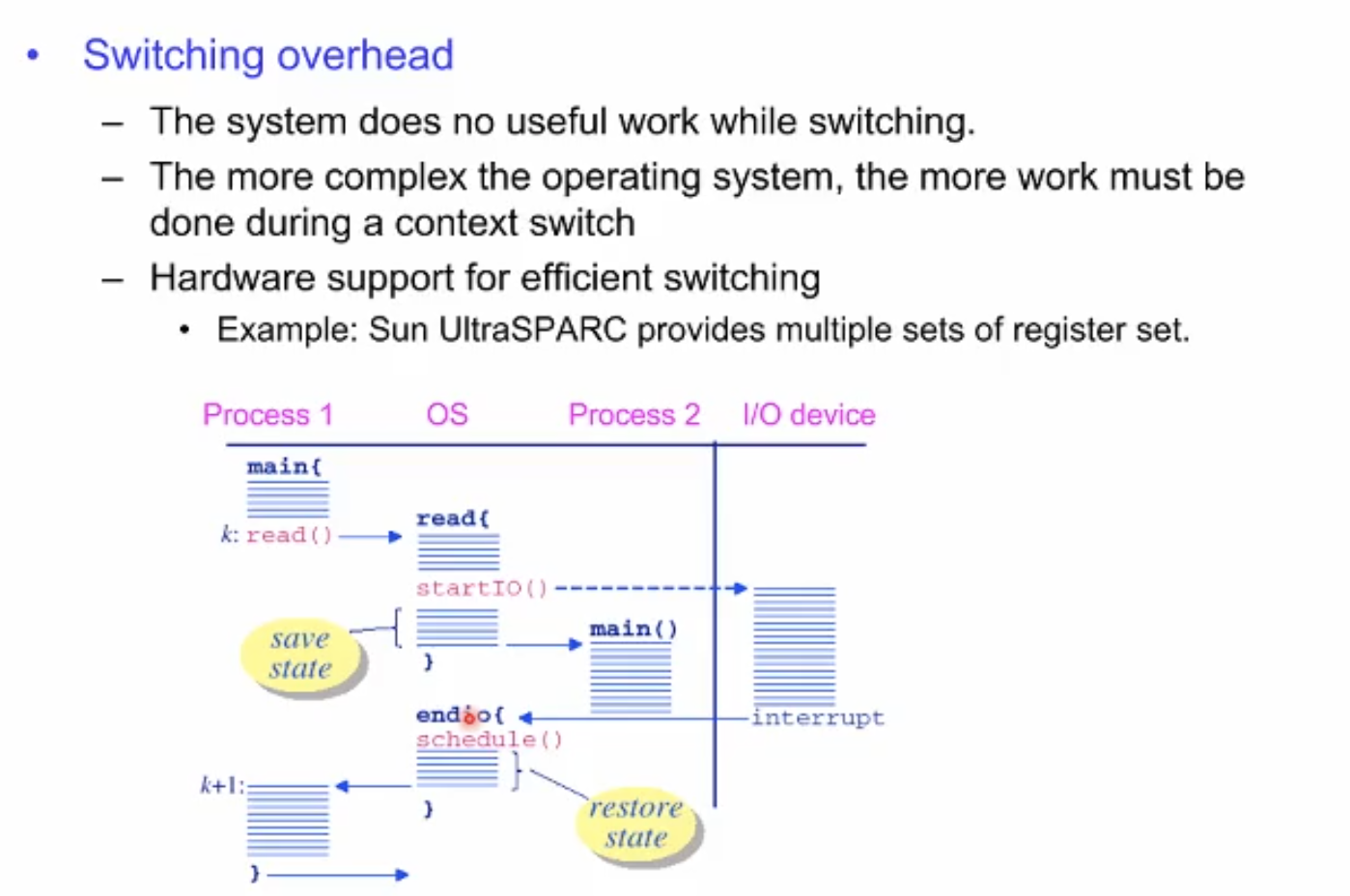
Linux와 x86 아키텍쳐 환경을 예시로 설명

언제 커널모드가 실행되느냐
- 유저 모드의 프로세스가 시스템 콜을 호출했을 때
- CPU가 Exception을 발생시켰을때
- 주변장치(I/O)나 다른 interrupt 가 발생했을때, Interrupt handler를 커널 모드에서 동작시킬때
- 커널 스레드가 실행될때(지금은 몰라도 됨)
System Call
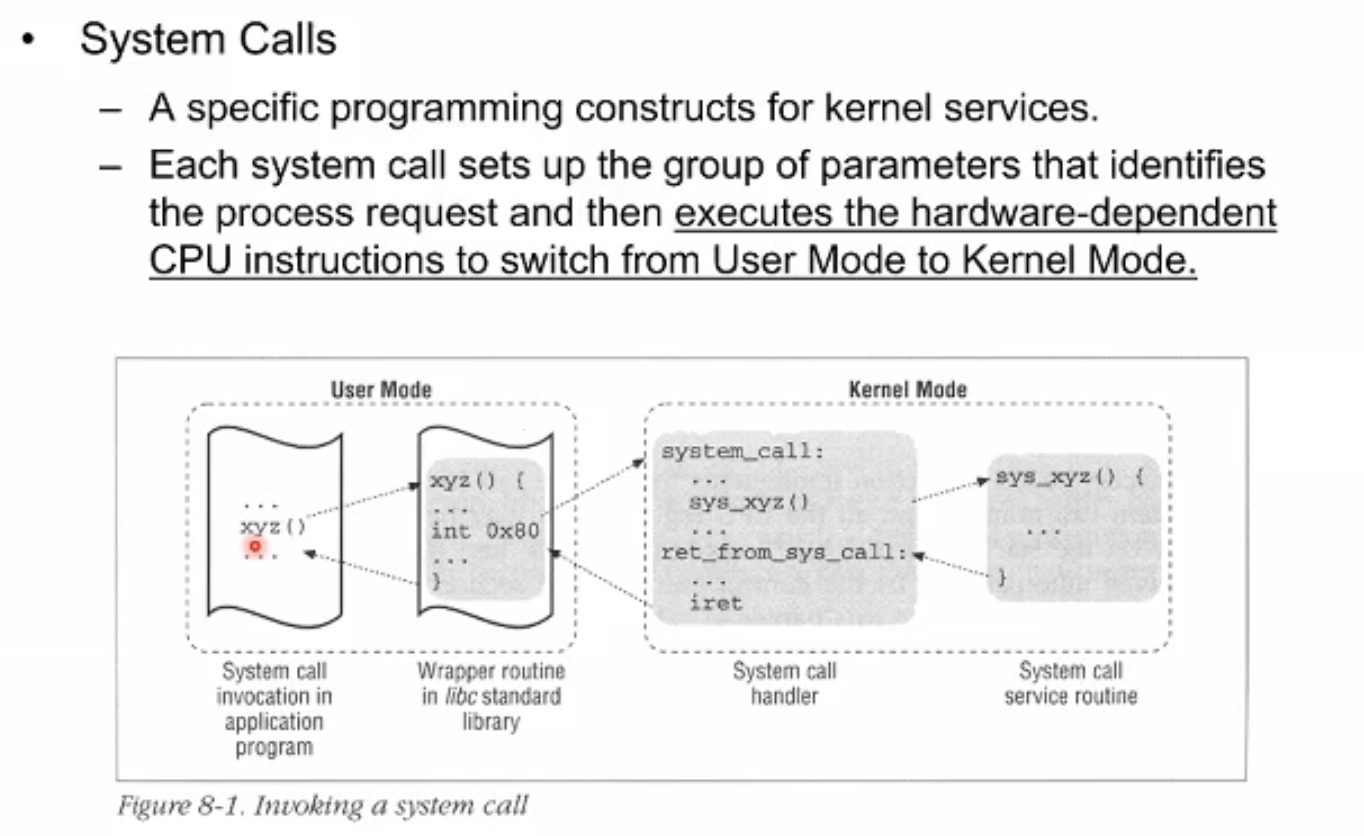
시스템 콜 함수부분에 도달하는 그 즉시 CPU가 커널모드로 건너가서 시스템 콜 핸들러를 동작시킨다. 이후 시스템 콜의 로직에 관한 구현 코드를 수행하고 그결과를 다시 유저모드로 돌아가 반환하게 된다.
Mode switching
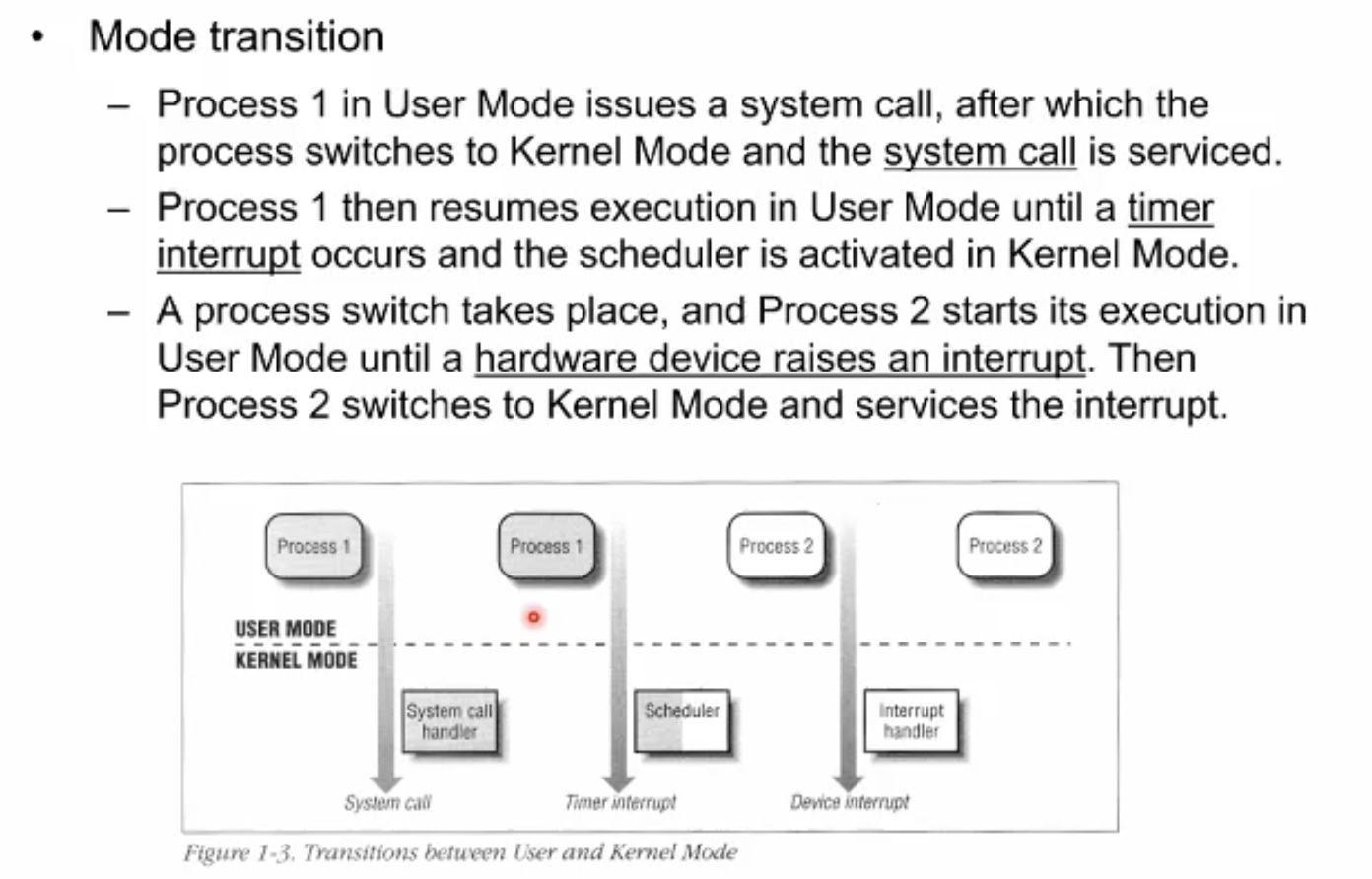
Process 1이 유저모드에서 돌고 있다가 시스템 콜을 하면 커널 모드로 넘어가 시스템 콜 핸들러를 수행하고 다시 유저모드로 돌아간다.
그러다가 time interrupt가 발생해 다시 커널모드로 가서 Timer Interrupt handler를 수행하게 된다. 이때 interrupt handler가 보니까 스케쥴러로부터 할당받은 프로세스의 시간이 전부 소진되었음을 확인한다.
커널모드에서 Timer interupt가 프로세스 1의 상태를 ready로 바꾸고 스케쥴러를 호출해 process1을 레디 큐에, 그리고 다음 우선순위인 프로세스 2를 CPU에게 할당시켜주게끔 하고 다시 유저모드로 돌아가 프로세스2를 수행한다.
이번에는 device interrupt가 돌아온다 예를 들어 네트워크 장비에서 패킷을 받았다 치자. 그러면 CPU는 다시 Interrupt handler에 의해 interrupt를 받게 되고 커널모드로 가서 interrupt핸들러를 동작해 처리하고 다시 유저모드로 가서 프로세스 2를 수행한다.
모드스위치는 매우 많이 발생하고 그들중 어떨 때는 프로세스 스위칭도 발생한다.
Execution of the Operating System

→ 지금까지 프로세스의 정의에 대해 개념적으로 살펴봤다. 중간중간 운영체제에 대해서도 언급이 되었다. 그렇다면 운영체제는 프로세스인가? 운영체제의 커널 코드는 어디서 실행되는 것인가? 모드스위칭을 한다는데 커널모드를 수행한다는 것은 커널 프로세스를 실행시키는 것인가? 우리의 유저 프로세스와 커널 프로세스가 어떻게 전환되고 실행되는가?
운영체제도 우리의 유저 프로세스와 마찬가지로 CPU에 의해 실행되는 프로그램이다. OS 코드도 컴파일러를 거쳐 실행가능한 프로그램 파일로 변환된다. 운영체제의 구현은 어떤 식으로 이루어지는 것인가?
크게 두가지 APPROACH가 있다. 운영체제의 구현 방법론.
- Execution within User Process 유저 코드 안에서 운영체제를 실행
- Execution outside User Process (Proces-based Operating System) 유저 코드 밖에서 운영체제 실행
Execution Within User Process
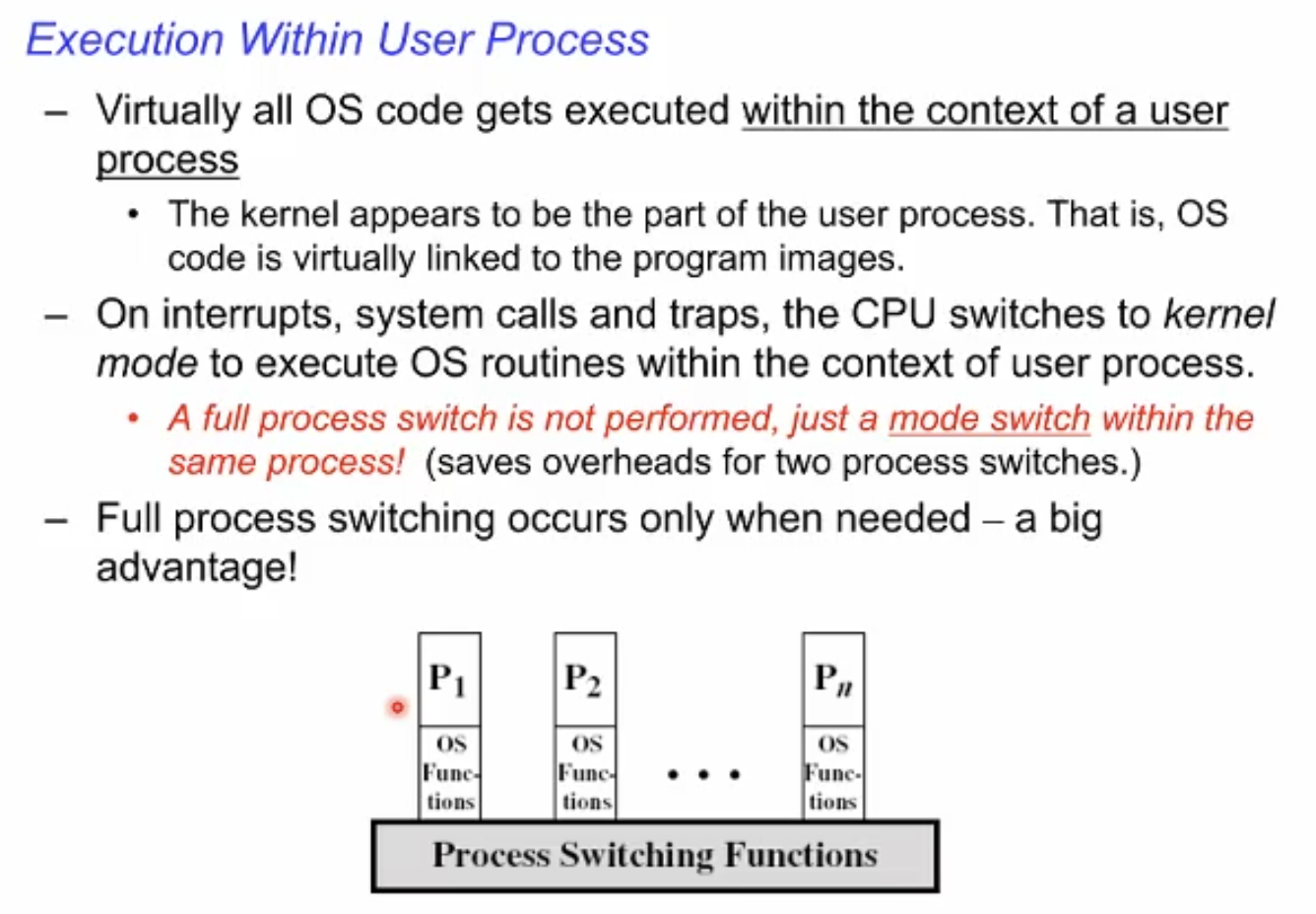
운영체제는 유저코드 안에서 돈다. 즉 유저 프로세스의 context안에서 돈다
유저 프로세스의 일부처럼 보인다. 실제로는 우리의 프로그램 이미지와 엮여있다.
모드스위칭이 발생했을 때 CPU는 커널모드로 전환하게 되는데 이때 다른 프로세스로 옮겨가는 것이 아니라 실행중인 유저 프로세스의 이미지 내에서의 전환으로 이루어진다.
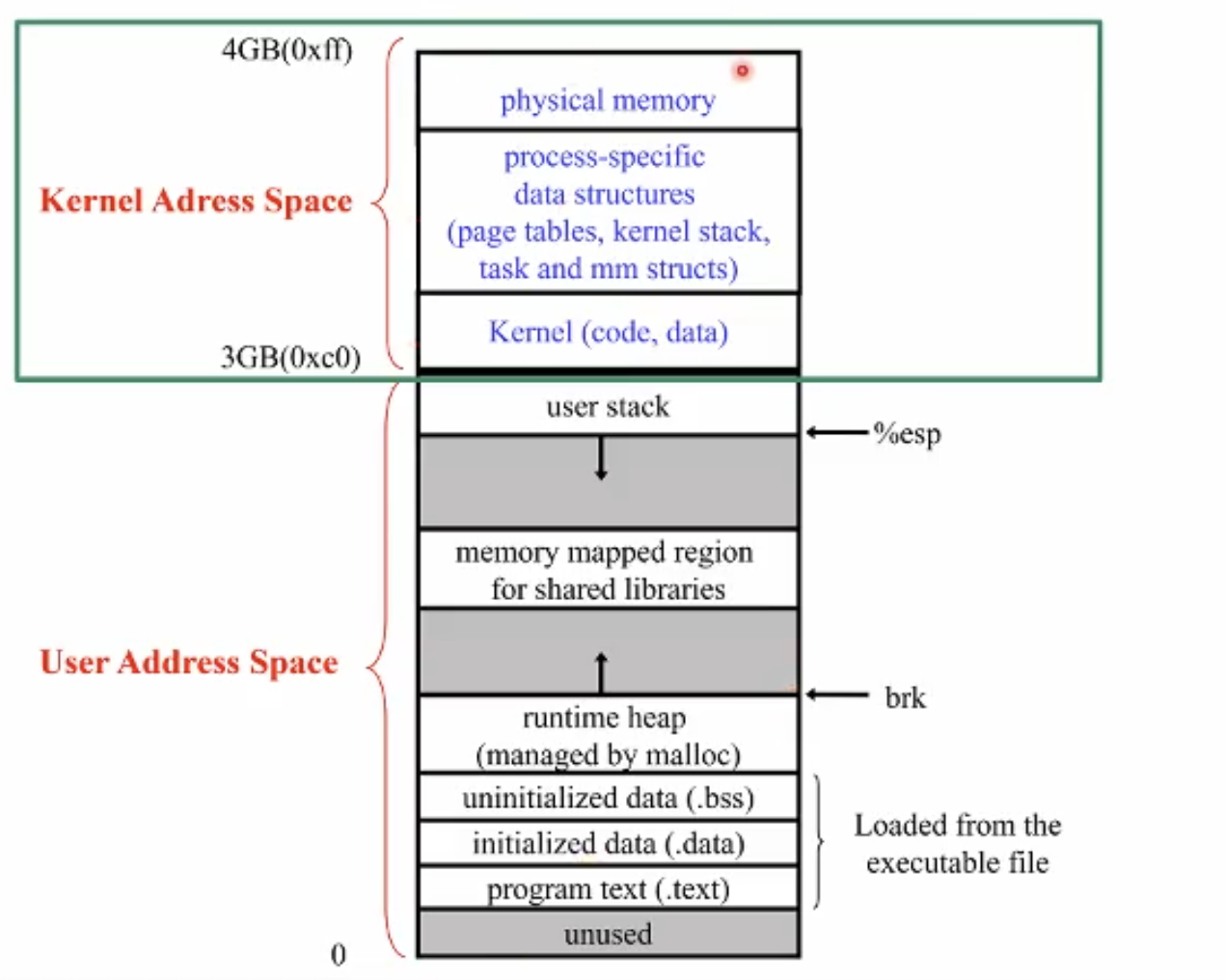
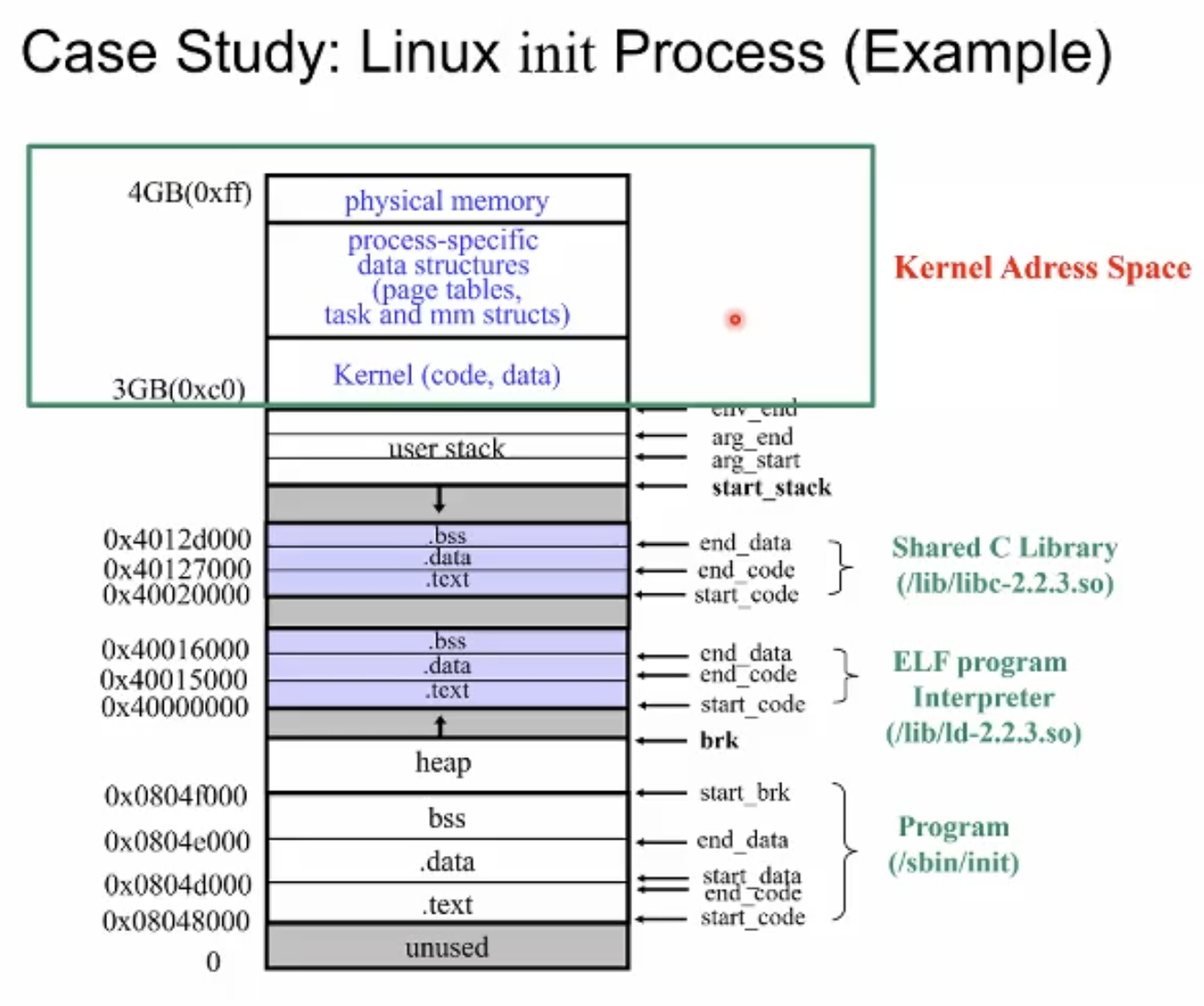
리눅스를 예시로 살펴보자 (32비트 아키텍쳐)
위가 일반적인 리눅스의 PCB 자료구조의 mm_struct, 즉 프로세스 이미지의 개념도이다. CPU의 프로그램 카운터는 0~ 4G까지 왔다갔다 할 수 있다. 즉 4G가 Linear Address공간이다.
전체 프로세스의 Linear Address공간을 두 부분, 1:3으로 쪼갠다. 아래 부분을 user Address Space, 윗 부분을 Kernel Address Space라고 부른다.
윗 부분이 바로 커널이 사용하는 주소공간이다. 상위 1G 공간은 커널이 독점에서 사용한다 . 즉 커널이 유저 프로세스의 부분처럼 보이는 것이다.
운영체제의 코드가 유저 프로세스 안에 도는 방법론은 이러한 형태로 프로세스 이미지를 구성한다.
만일 위 프로세스가 시스템 콜 등을 이유로 커널모드로 모드스위칭을 해야한다면 CPU는 그저 간단히 PC를 Linear Address의 상위 커널 주소 공간으로, 다시말해 관련된 interrupt handler, system call handler에 관여된 부분으로 점프시키기만 하는 것이다. 이후 유저 모드로 다시 모드 스위칭 할때도 단순히 아래 부분의 메모리 공간으로 이동시키면 된다.
만일 안부족하게 총 4G씩 쓰고 싶다면 운영체제의 코드자체도 또다른 온전한 4G의 프로세스 이미지로 만들어주면 된다. 이후 프로세스들을 병렬로 돌리면 된다. 장점은 4기가를 전부 다 쓸 수 있는 것이지만 그에 비해 모드스위칭의 오버헤드로부터 오는 성능저하가 너무 어마어마하다. 모드 스위칭을 하려면 프로세스 스위칭을 해야하는 꼴인 것이다.
주소공간을 조금 포기하는 대신, 모드스위칭을 빠르게 하는것이 훨씬 이득이다.
또다른 이슈: 왜 그러면 3:1로 쪼갤까? 몇십년간 이렇게 하는 데에는 이유가 있다. 검증된 비율. 필요에 의하면 상황에 맞게 조정할수도 있다. 커널도 1G면 충분히 가능하다. (윈도우는 1:1 비율이더라, 리눅스가 최적화가 좋다는 말이 이뜻인가?)
프로세스간 스위치는 어떻게 발생하는가? 시나리오
- Time interrupt 도달시 커널 모드로 가서 프로세스의 Time slice를 체크, given time을 전부 소진함을 확인
- 프로세스 스위칭을 위해 현재 프로세스의 state를 정리 및 저장해 scheduler를 콜해 ready state로, 다음 우선순위 프로세스를 선정
- 다음순위 프로세스에게 CPU할당
예시그림
Processed-based Operating System (Execution outside of user process)
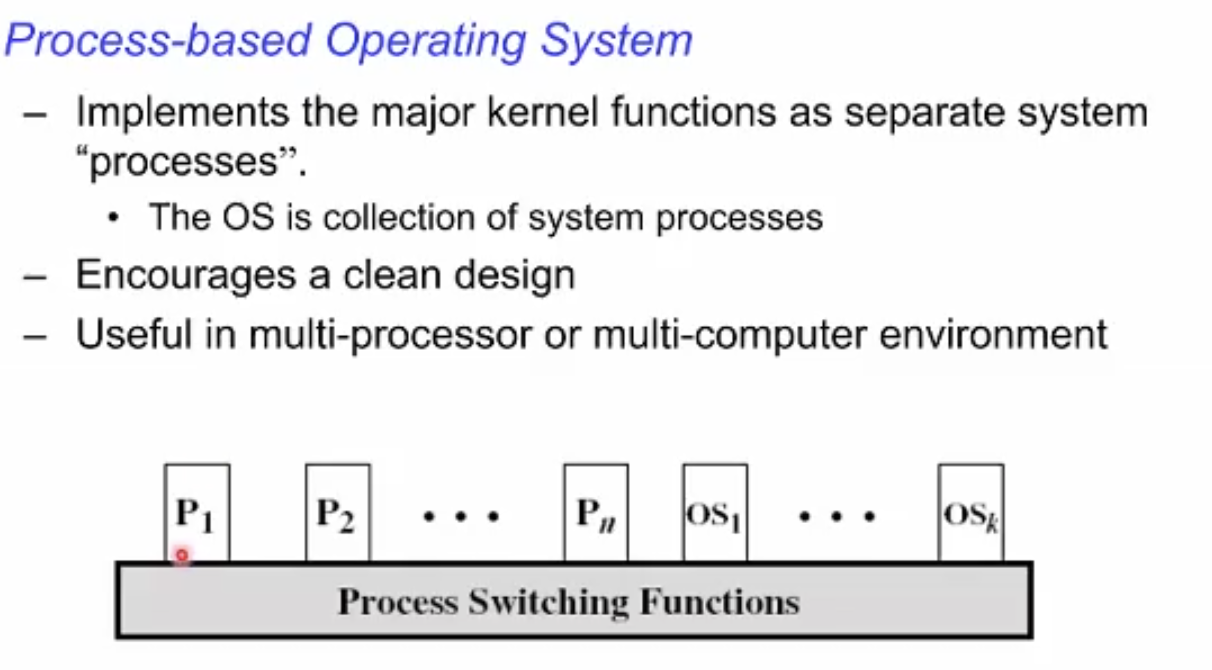
이 방법을 따르면 OS 자체가 하나의 프로세스로 돌게 된다. 전체 N + K 의 프로세스 (n=유저프로세스, k=커널프로세스)
장점: 4G 전체 주소공간을 사용할 수 있고, 운영체제를 여러개의 모듈로 나눠서 깔끔한 개념적 구현이 가능하다. 만일 아키텍쳐가 여러개의 CPU를 지닌 병렬 컴퓨터라면 동시에 여러 프로세스가 여러개의 CPU에 돌 수 있기 때문에 그러한 병렬 상황에서 성능 효율이 좋아진다.
단점: 모드스위치를 프로세스간 스위치로 구현을 해야한다. 매우 빈번히 일어나는 모드 스위치 작업을 매우 오버헤드가 큰 작업으로 수행해야한다는 치명적인 단점.
프로세스의 생성 : 운영체제 관점에서

프로세스가 어떻게 만들어지는가? 위의 요소들이 필요하고 만들어진다.
프로세스의 생성: 유저 관점에서

유저 관점에서 프로세스를 만들고 핸들링하는 기법들에 대해 살펴보자
총론적으로 얘기하면 프로세스를 만든다는 것은 결국 시스템의 리소스를 사용한다는 것이다. 이 리소스를 쓰고 확보하는 과정에서 내가 만들 프로세스와 다른 프로세스간의 관계도 형성해야한다. 부모 자식 프로세스 관점에서 자식 프로세스를 생성할때 리소스들을 복제를 할지, 새로운 리소스를 확보하여 대체할지. 수행 동기화의 문제 - 두 프로세스간 병렬적으로 수행되어야하나, 동기화가 필요한가, 자식 프로세스가 끝날때까지 대기해야하는가, 등등 여러가지 문제가 있다
이러한 이슈들과 관련된 개념들을 살펴보고 해결, 조율할수 있는 기법들을 예를 통해 알아보자.
Process Hierarchy
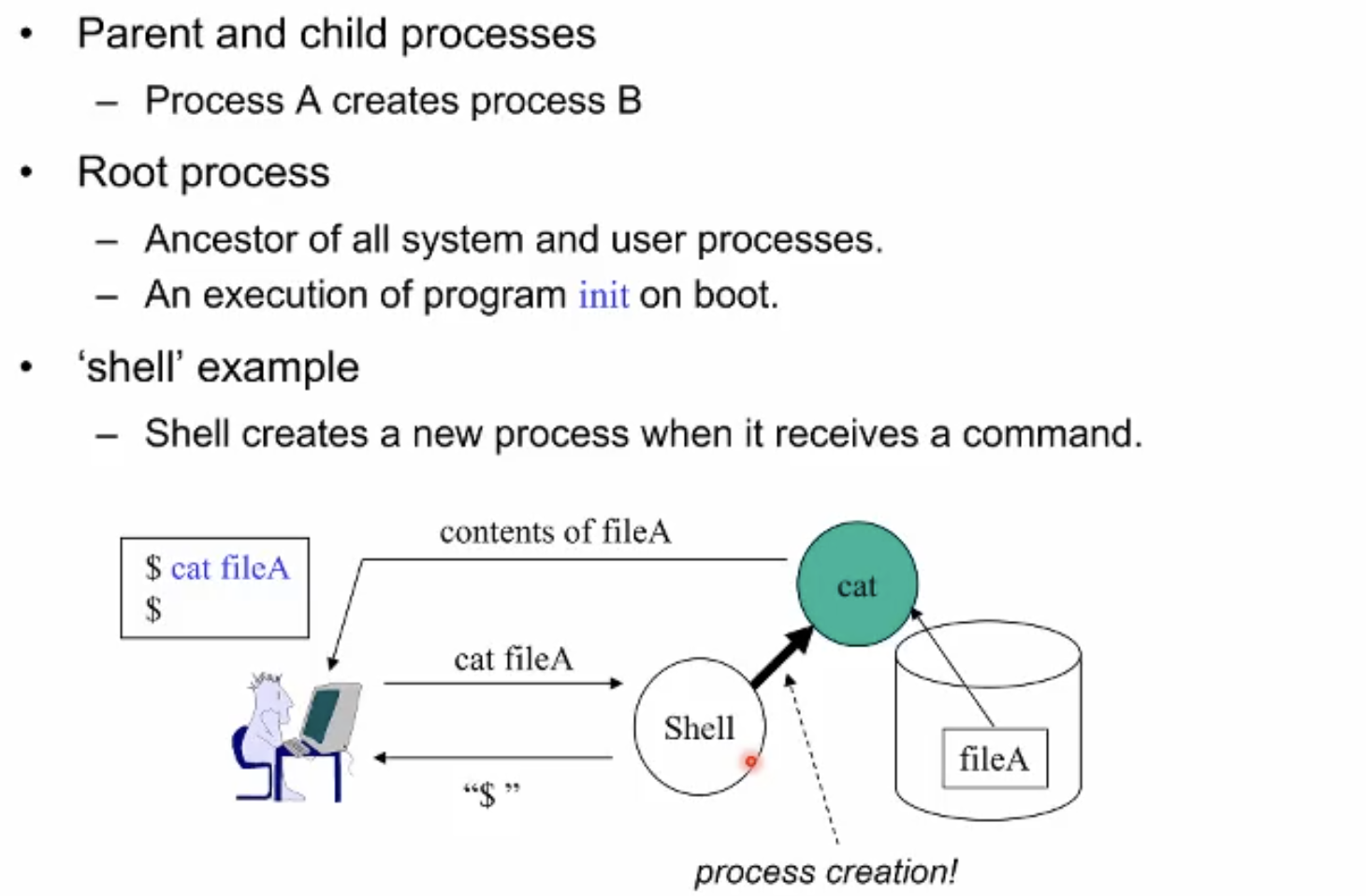
프로세스간에는 부모 자식 관계가 존재한다. 프로세스를 생성하기 위해서는 결국 프로세스가 실행되어야한다. 결국 거슬러 올라가다 보면 시스템의 첫 프로세스, 모든 프로세스의 조상인 root process가 존재한다. 리눅스 기준으로는 init 프로그램이 바로 root 프로세스이다.
| 만일 부모 프로세스가 종료되었을 시, child process 는 자신의 종료 시그널을 보낼 부모가 없어진다. 이때 init process가 대신 받아준다 |
예를 들어 우리가 쉘 창에 cat fileA를 타이핑 했다고 가정하자
그 순간 시스템상에서 쉘 프로세스가 자신과 똑같은 프로세스를 자식프로세스로 복제생성한다. 복제된 프로세스는 이후 cat이라는 프로그램 파일 내용으로 내부가 치환되며 필요한 데이터들도 들어가게 된다.
이러한 일련의 복제-치환 과정으로 프로세스를 생성해낸다.
이 과정이 몇십년간 이어진 유닉스 운영체제에서 프로세스를 만들어내는 과정이다.
프로세스 관련된 시스템 콜 함수들(유닉스계열)

시스템 콜은 프로그래머관점에서 프로세스를 만들고 관리하기 위한 첫번째 수단이다.
시스템 콜은 프로세스 뿐만 아니라 약 300여개가 있다. 커널 서비스를 위해 제공되는 기능으로 다양한 커널 서비스들을 활용할 줄 알아야 아주 고급기능을 하는 프로그램을 짤 수 있다.
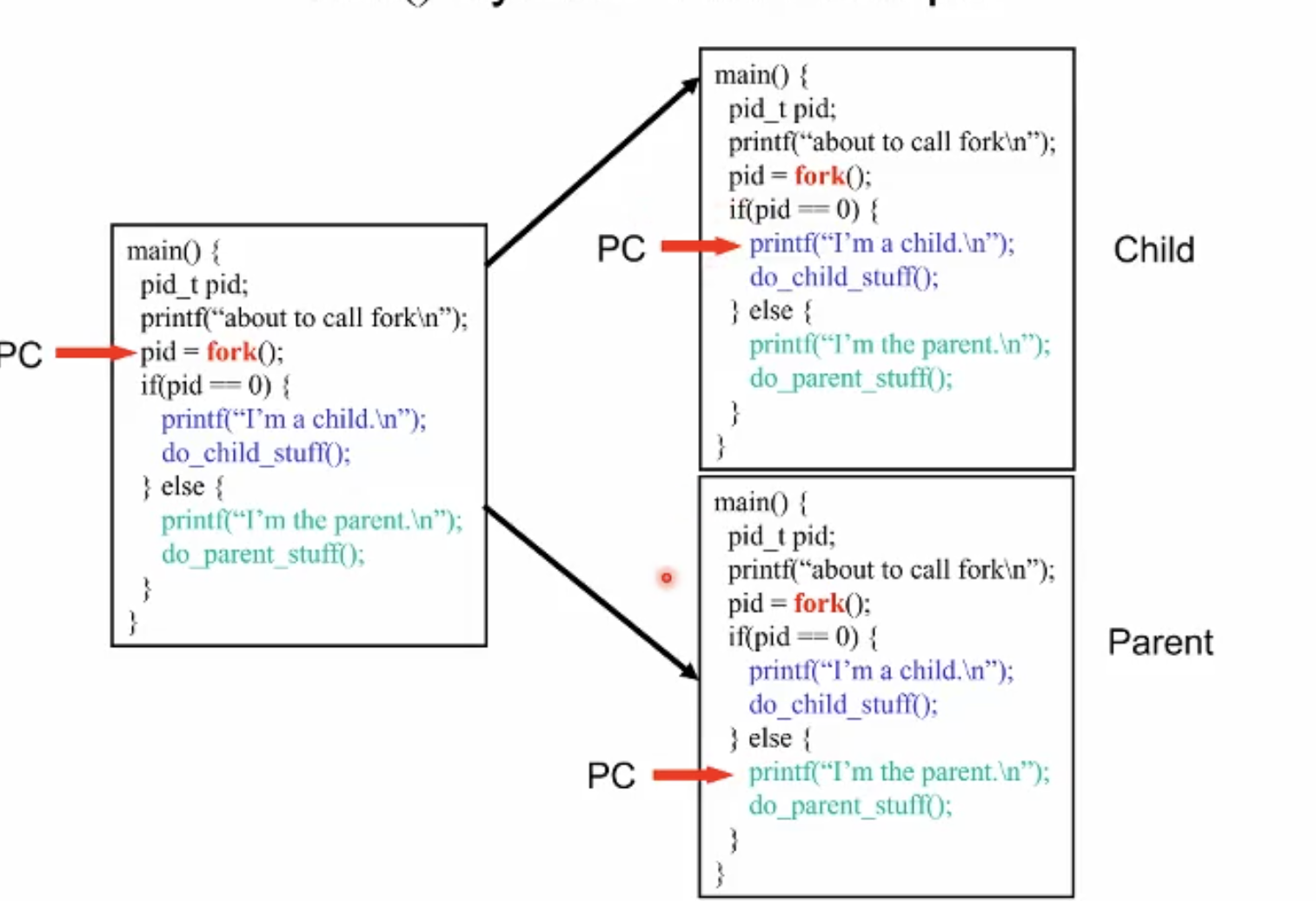
- Fork

PID를 제외한 모든 이미지를 복제.
코드예시 pid 가 0이면 child임을 이용해서 코드상에서 분기.
- Exec() 계열

새로운 프로그램을 수행하게 함. exec을 실행한 프로세스는 완전히 프로세스 이미지가 새로운 것으로 바뀌어버린다.
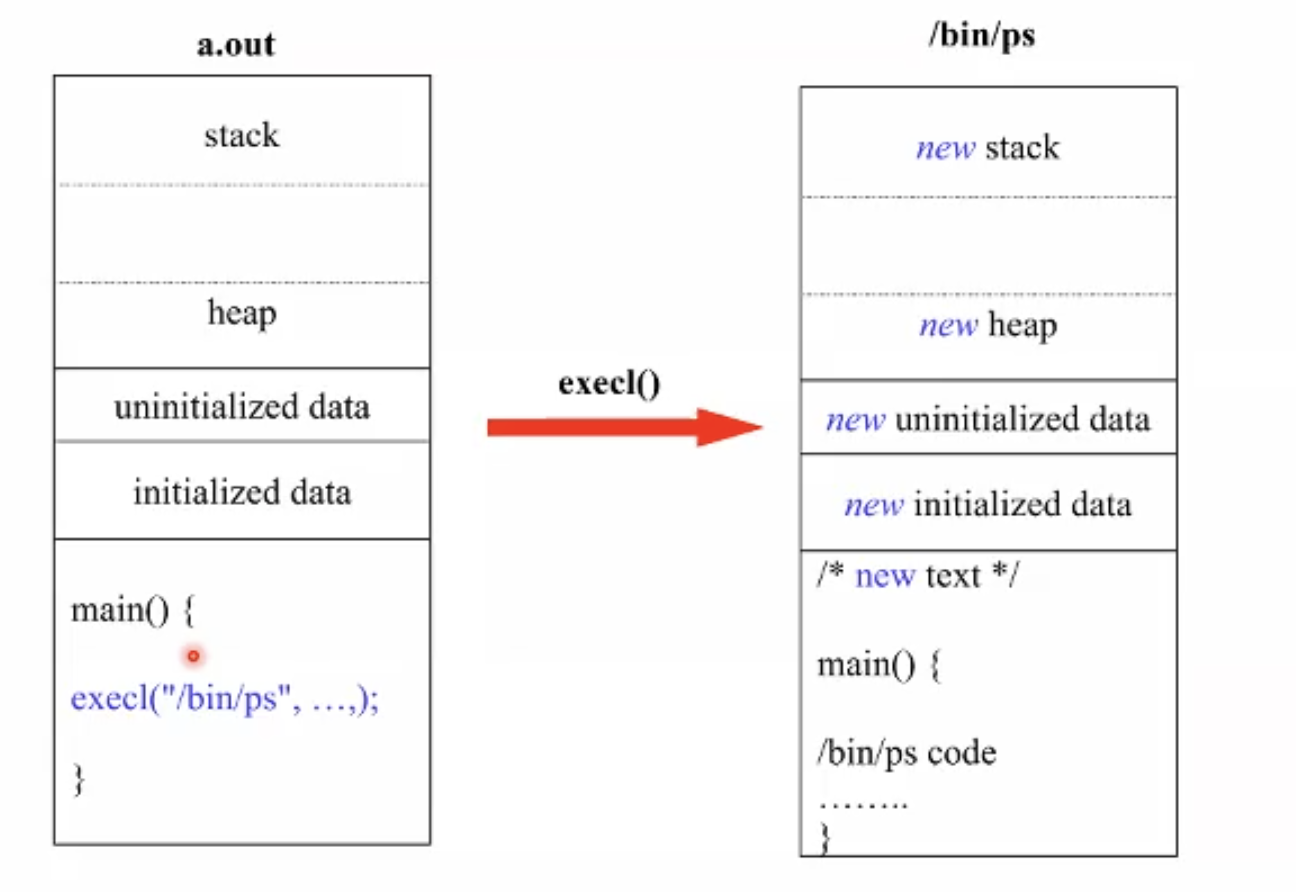
해당 프로세스에 대한 pid만 같고 안에만 다 바뀌는 것.
- fork + exec
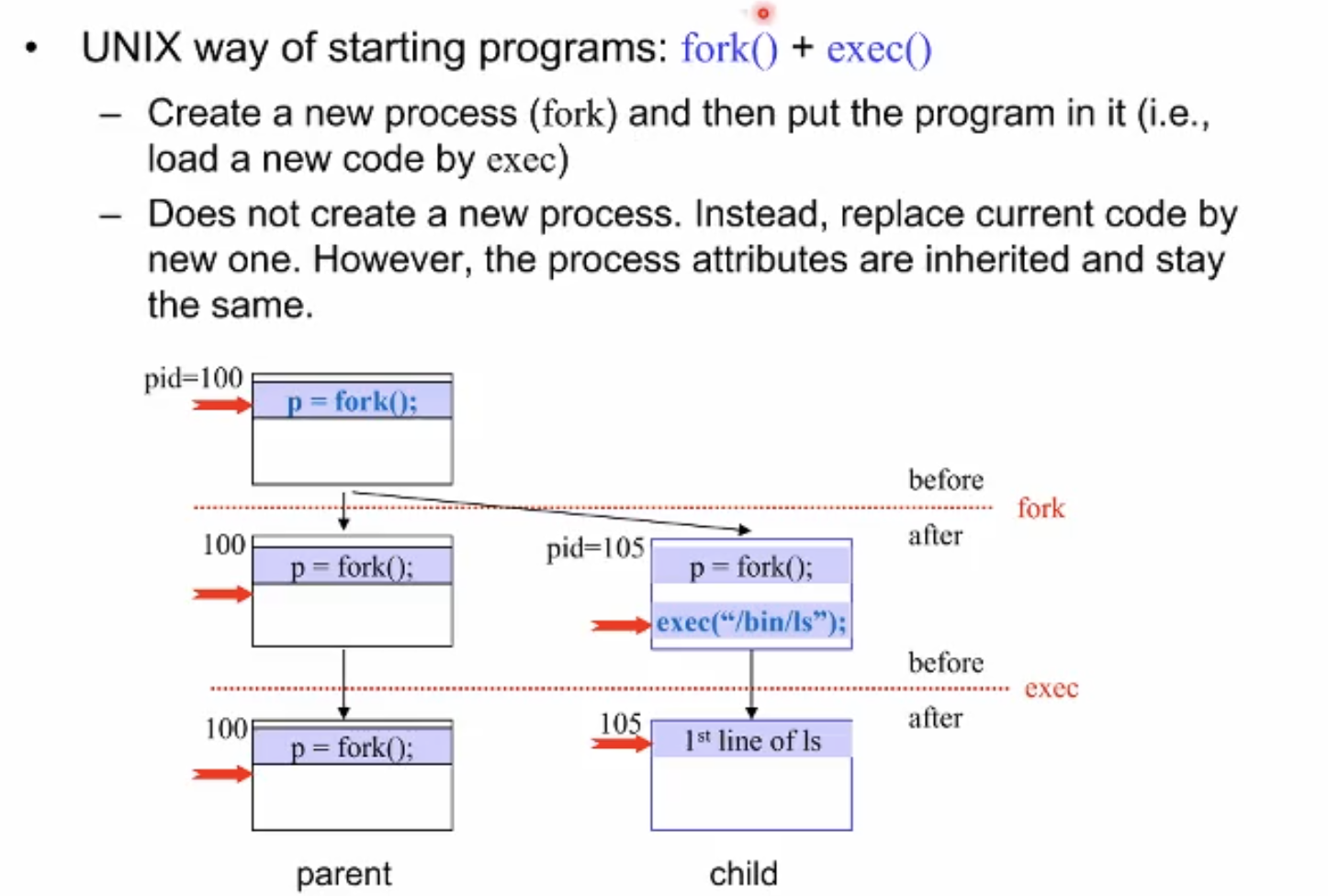
fork + exec 조합으로 완전히 다른 프로세스를 만들어낼 수 있다

우리가 사용하는 쉘도 같은 과정을 통해서 우리의 명령들을 실행시킨다.
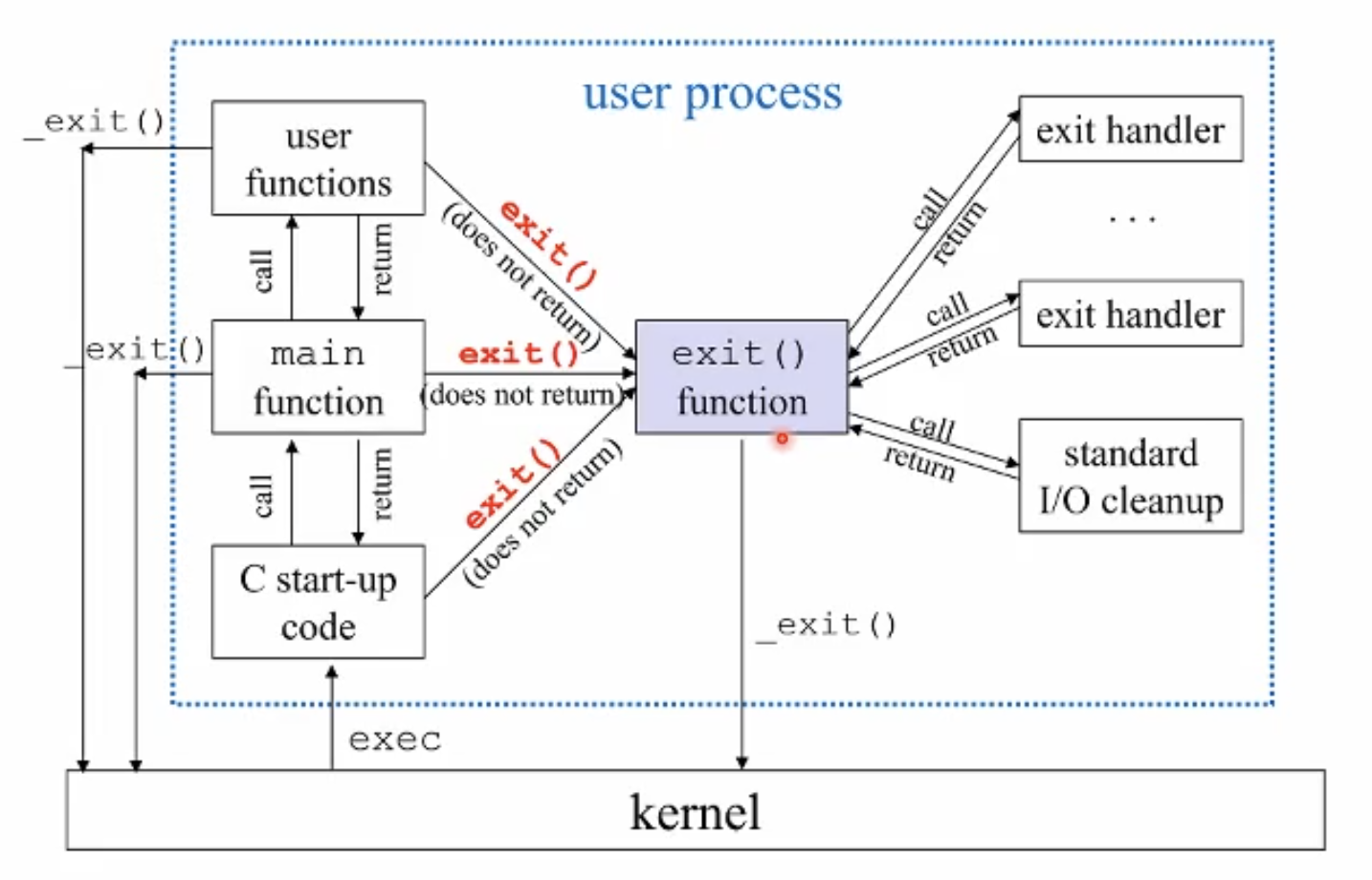
- exit()

fork의 반대개념. 프로세스를 terminate시키는 명령어
두가지 형태로 쓰인다. code상에서 명시적으로 쓸 수 있다. 그 시점에 종료.
다른 한가지는 main 함수가 끝나면 자동으로 호출된다.
- wait()
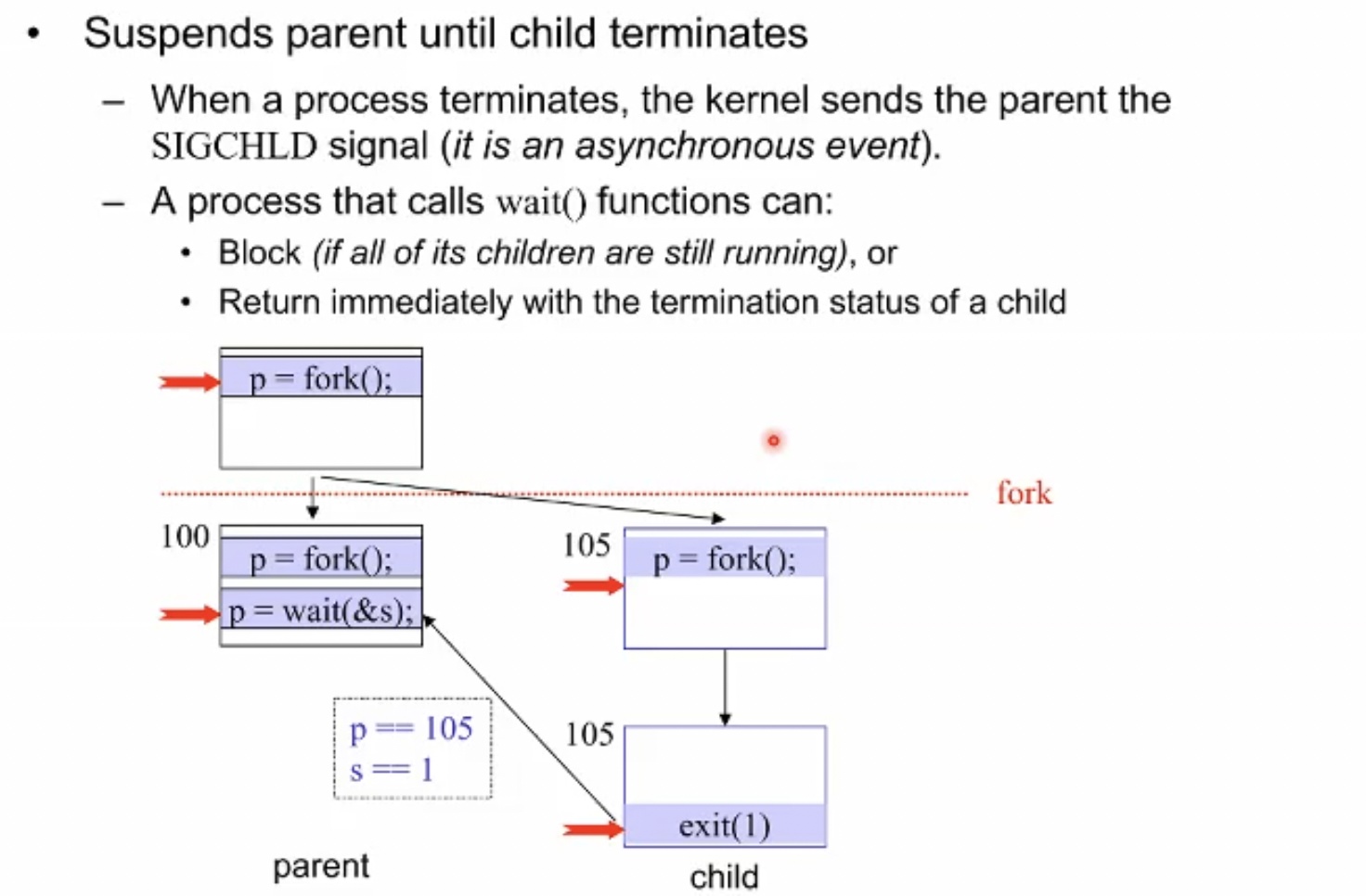
parent child간의 동기화를 위해 쓰인다.
child process 가 exit()에 의해 끝나메 되면 커널이 parent process에게 시그널을 보내게 된다.
wait()을 쓴 프로세스는 이 시그널을 받기 전까지 block state가 된다.
Cooperating Process

멀티프로세싱을 한다면, 여러 프로세스간, 통신이 되어야하고 동기화가 되어야한다.
병렬처리, 분산처리 이슈등 여러가지 이슈가 많은데 개념적으로 두가지 접근법이 있다.
- 컴파일러와 프로그래밍 언어 관점에서 이런 부분을 타이트하게 제어하기(By Application)
- 제네릭한 운영체제가 제공하는 프로세스간 통신하는 기법을 활용하기(By System)
Process coordination by Applications
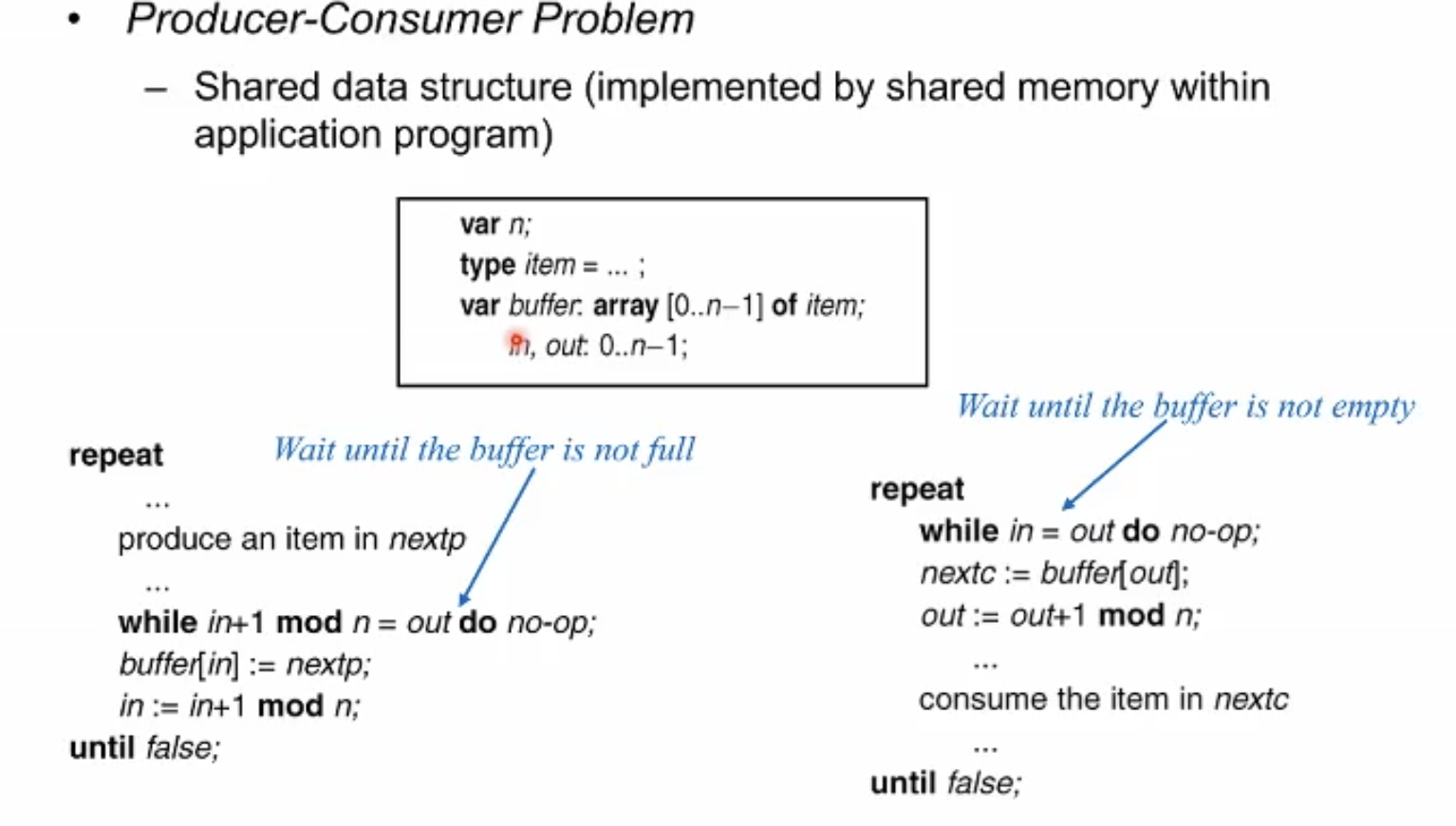
producer consumer 문제: 프로듀서는 계속 데이터를 만들어내고 컨슈머는 계속 데이터를 사용한다. 문제는 둘 이 함께 작업해야댄다는 점이다. 프로듀서가 빨라서도, 컨슈머가 빨라서도 안된다.
대표적인 프로그래밍 관점에서의 해결책은 버퍼를 두는 것이다. 버퍼는 스피드가 다른 두 프로세스를 완충시켜주는 자료구조 역할을 해준다. 이 버퍼를 두 프로세스간 공유하는 자료구조로 정의를 해 두고, 프로듀서는 테일을, 컨슈머는 헤드를 관장하게 한다. 헤드와 테일이 같다면 비었다는 것을 의미하고 테일이 꽉 찼다면 프로듀서는 꽉 찼음을 인지하고 생산을 중단하게 한다.
대략적으로 이러한 방법으로 프로듀서 컨슈머 문제를 해결하게 한다.
InterProcess Communication
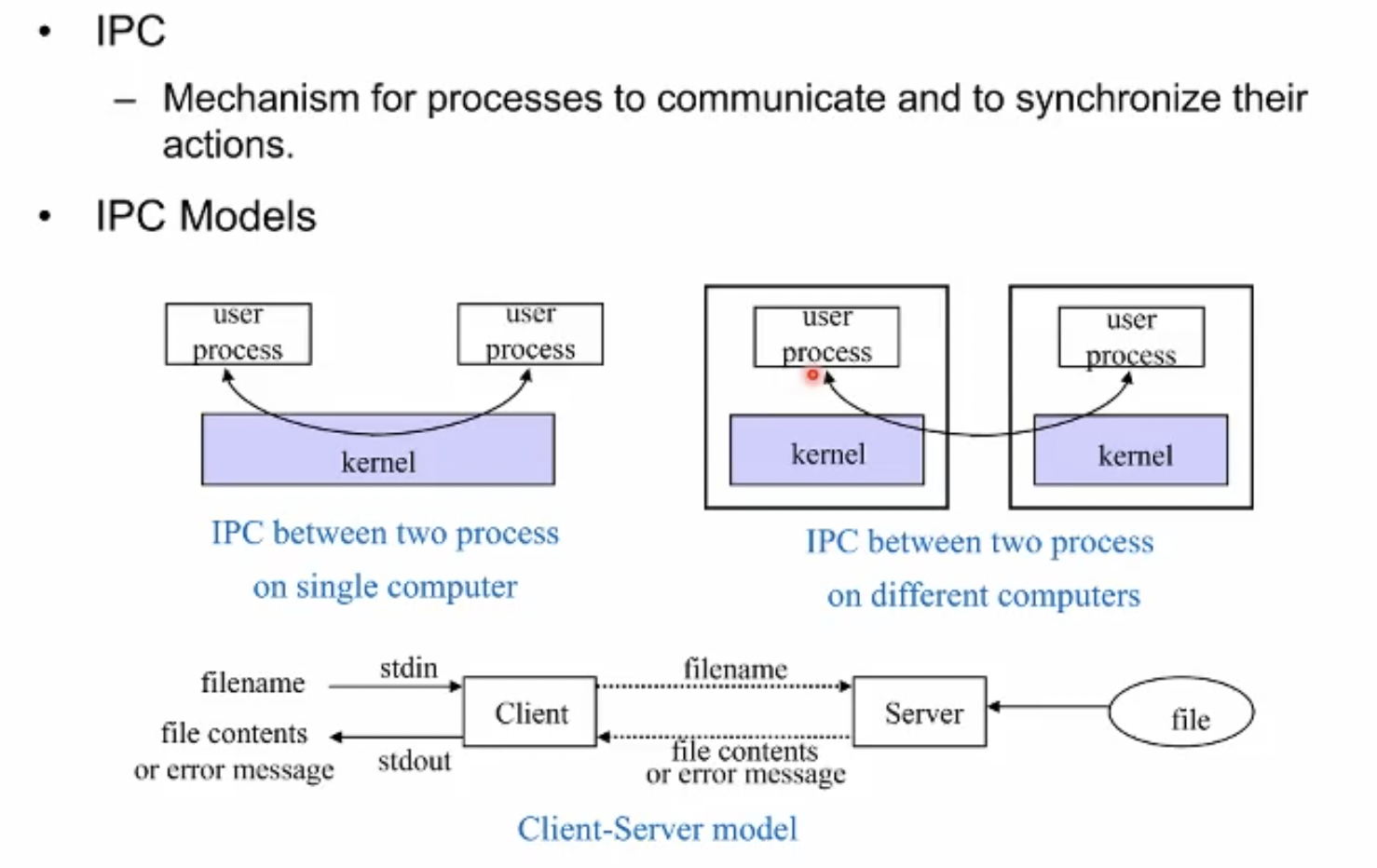
system level에서 지원하는 방법. 운영체제가 제공하는 프로세스간 동기화의 primitive를 써서 해결할 수 있다.
이러한 것을 통칭으로 IPC라 한다. Interprocess communication. 두개의 프로세스간 커뮤니케이션과 동기화를 다루게 하는 시스템이 제공하는 기법이다.
IPC mechanism에 관한 여러가지 고민과 연구가 있었다. 이런것들을 IPC 모델이라고 한다.여러가지 모델이 존재한다.
커널을 통해서 또다른 프로세스간에 데이터를 주고받고 동기화하는 것이 가장 상식적이고 직관적인 방법일 것이다. 더불어 한 컴퓨터 내의 프로세스들간 뿐만 아니라 네트워크 상에서 다른 호스트들의 프로세스들간 커뮤니케이션도 제공되어야 할 것이다.
유닉스 IPC의 종류

맨 처음 네트워크 형성이 잘 안될 때 나온 기법이 Basic IPC이다. 간단한 형태로, Pipe, Fifo등이 있으며 단일 컴퓨터 내에서의 coordination을 위한 기법이다.
고급 IPC
크게 두가지 맥락이 있다. Unix System V, BSD Unix 이 두 진영에서 각각 다른 기법들을 선보였다 결론부터 얘기하면 시스템 V 계열은 아무도 안쓰고 있다. 결국 이 세상에 남은 것은 소켓 방식이다.
Basic IPC - 파이프 기법
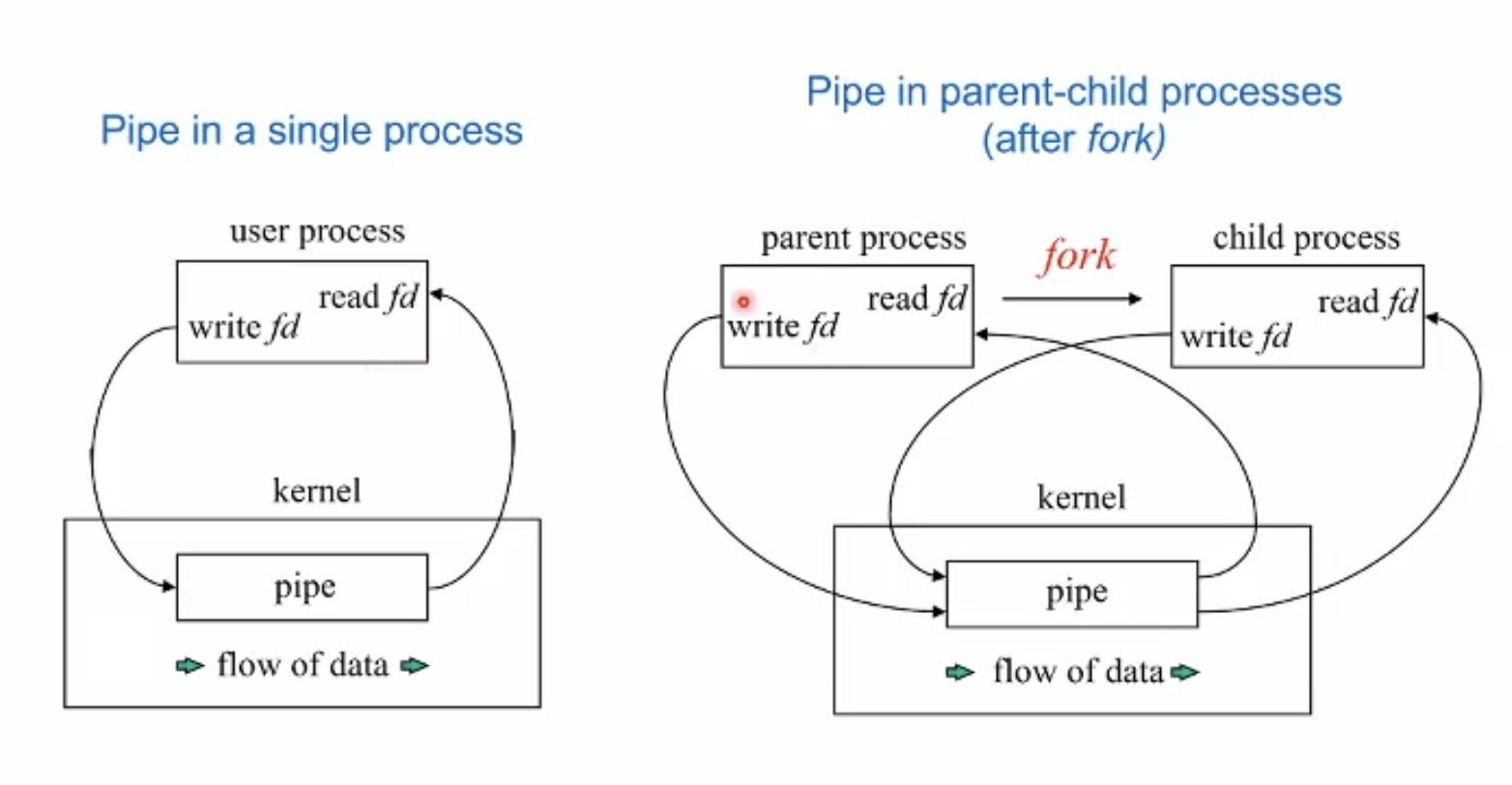
파이프 기법… 과제 때 이거한다고 개고생했다. 아주 원시적인 방법의 IPC
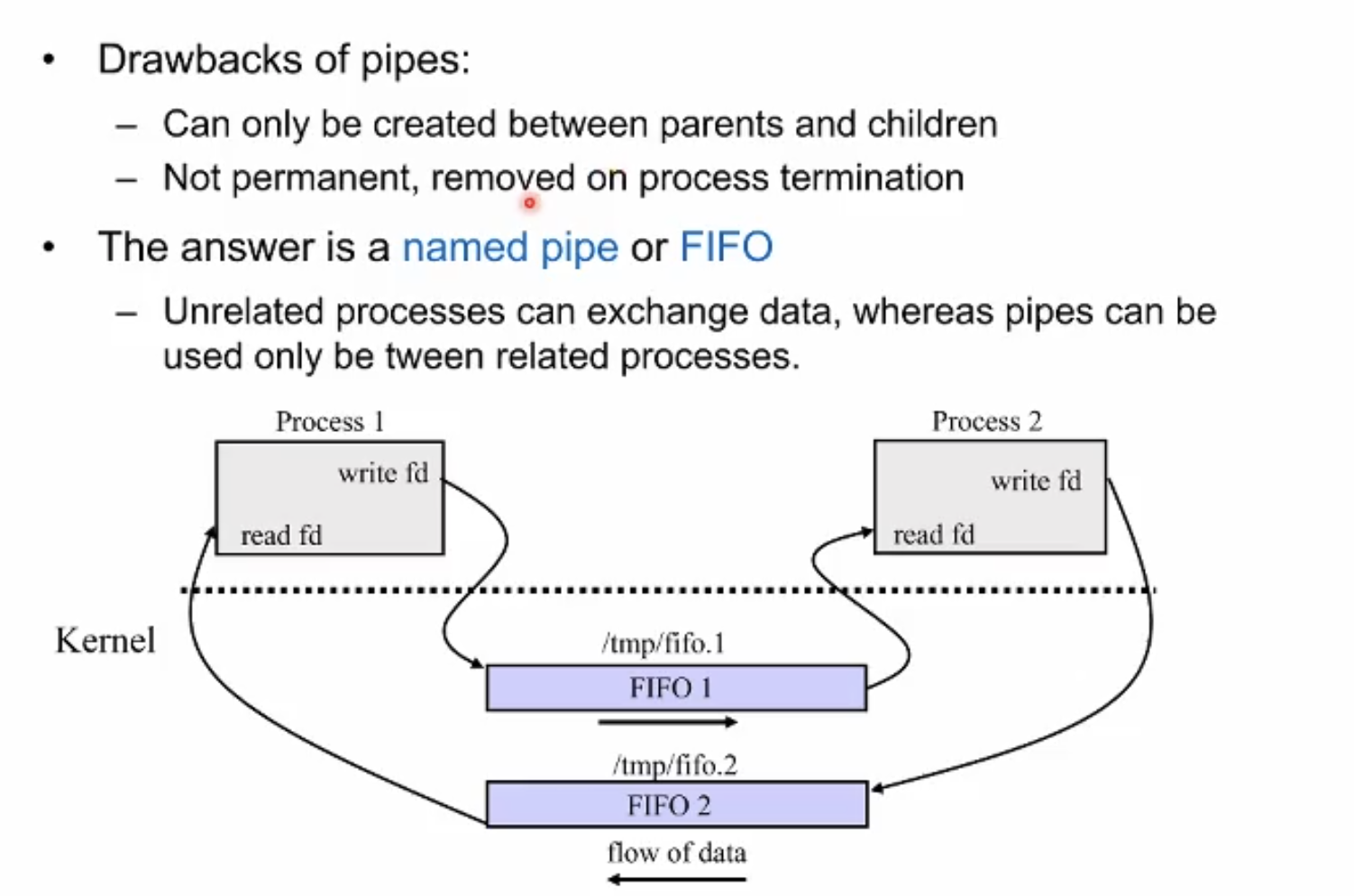
단점이 더많음. 일단 부모 자식 관계의 프로세스간만 사용 가능하며 이 파이프라는게 커널상에서 영구히 존재하지 않다. 그래서 커널에 파이프를 상주시키는 것으로 발전함. 즉 파이프에 이름을 부여하여 열어두어 임의의 프로세스가 임의의 프로세스에게 주고받을 수 있게끔 발전했다
System V IPC

시스템 V 진영에서 선보인 IPC primitive들 이런게 있다 정도만 이해하자.
버클리 유닉스 계열의 IPC - > SOCKET
Client Server IPC

이 기법이 등장한 배경이 90년대에 컴퓨터의 하드웨어와 통신, 네트워킹 기술이 어느정도 발달하기 시작했을 무렵이다. 네트워크가 안정이되고 빨라지다 보니 서버-클라이언트 모델이 등장하기 시작했다.
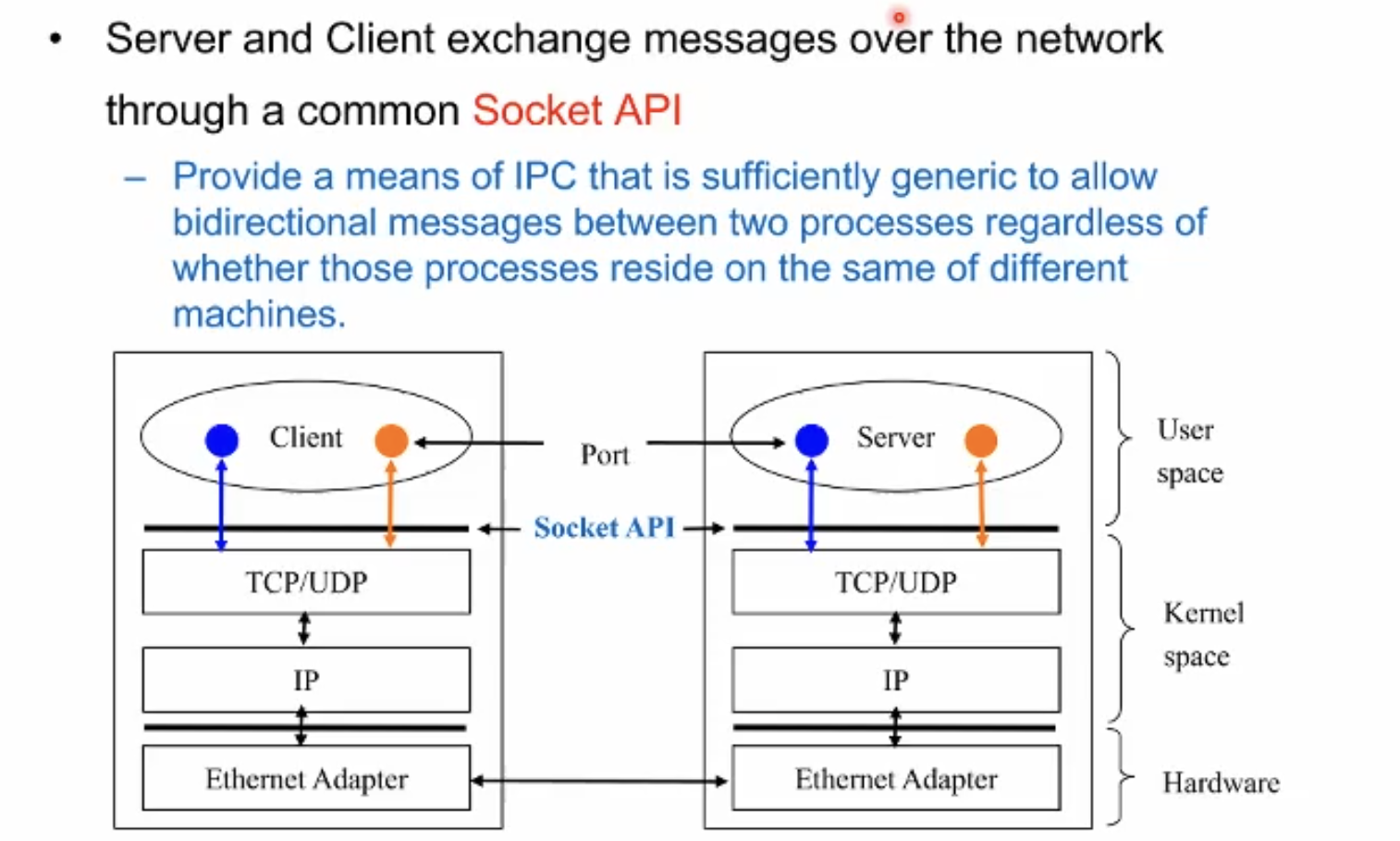
소켓은 두가지 인자가 있다. ip 주소와 port 번호. 오늘날 쓰이는 네트워크 통신의 표준이다.
여담.
인터넷이란? 기술적인 정의
→표준 OSI 7 layer중에 3-network layer 에 Internet protocol을, 4-transport layer에 TCP/UDP를 사용하는 것을 인터넷이라고 한다.
포트 번호와 IP 주소로 프로세스를 특정한다.
초창기에는 버클리 유닉스에서만 사용하다 워낙 잘되니 모든 운영체제들이 사용하게 되었고 오늘날 표준이 되었다.
댓글남기기