L5-Process Scheduling
연세대학교 차호정 교수님의 운영체제 강의를 듣고 작성한 강의록
Basic Concepts in Scheduling
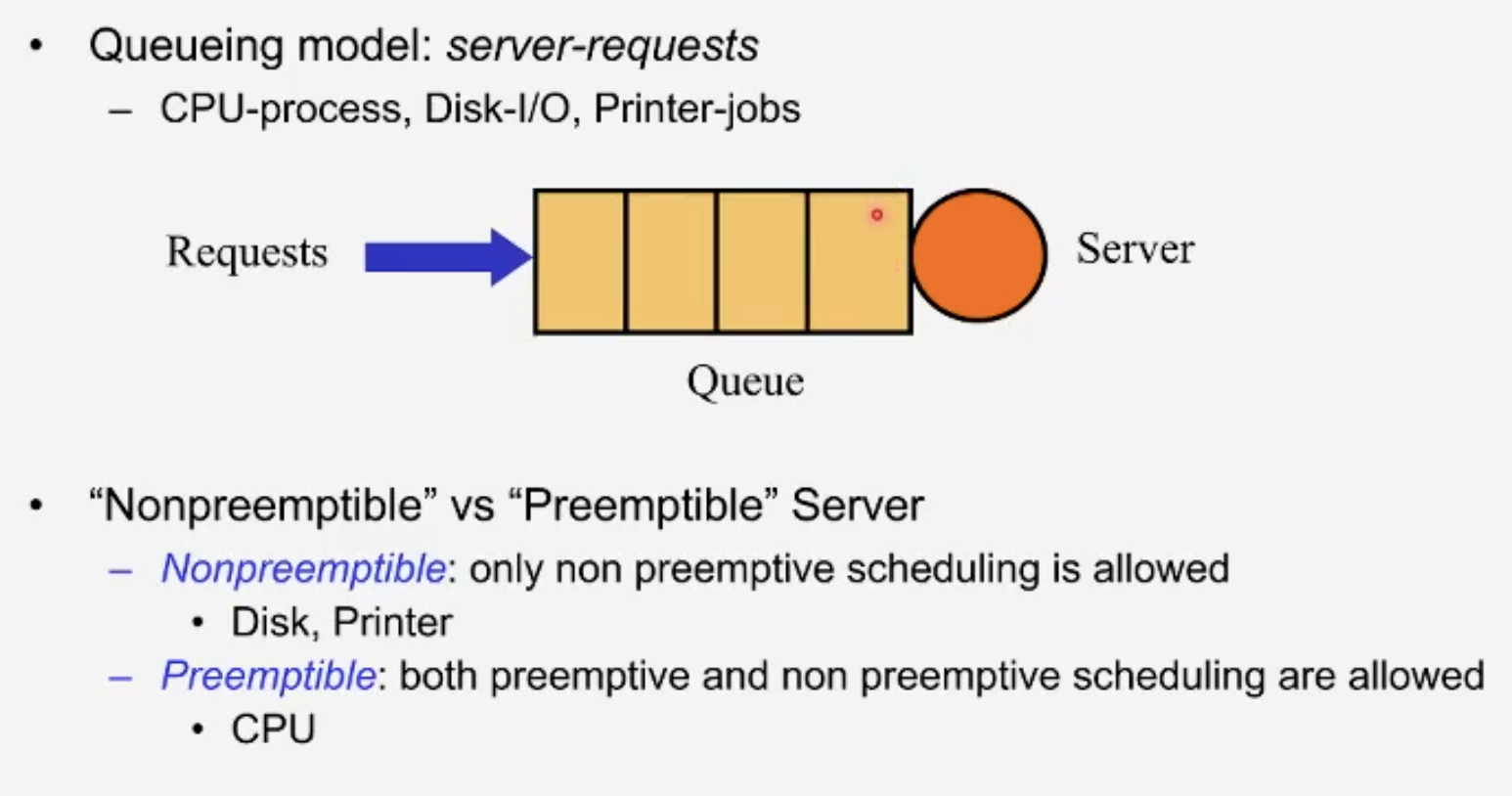
Active한 주체인 서버와 Job들을 지닌 큐, 서버는 큐의 대기중인 job들 중에서 어떤 것을 먼저 수행할지, 어떤 순서로 수행할지 선택해야한다.
Nonpreemtible: 수행 도중 다른 작업에 의해 흐름이 끊기지 않는 것.
Preemtible: 강제로 뺏는 것, 수행 도중 강제로 다른 작업이 끼어들어 뺏는것.
CPU scheduling(Short term Scheduling)
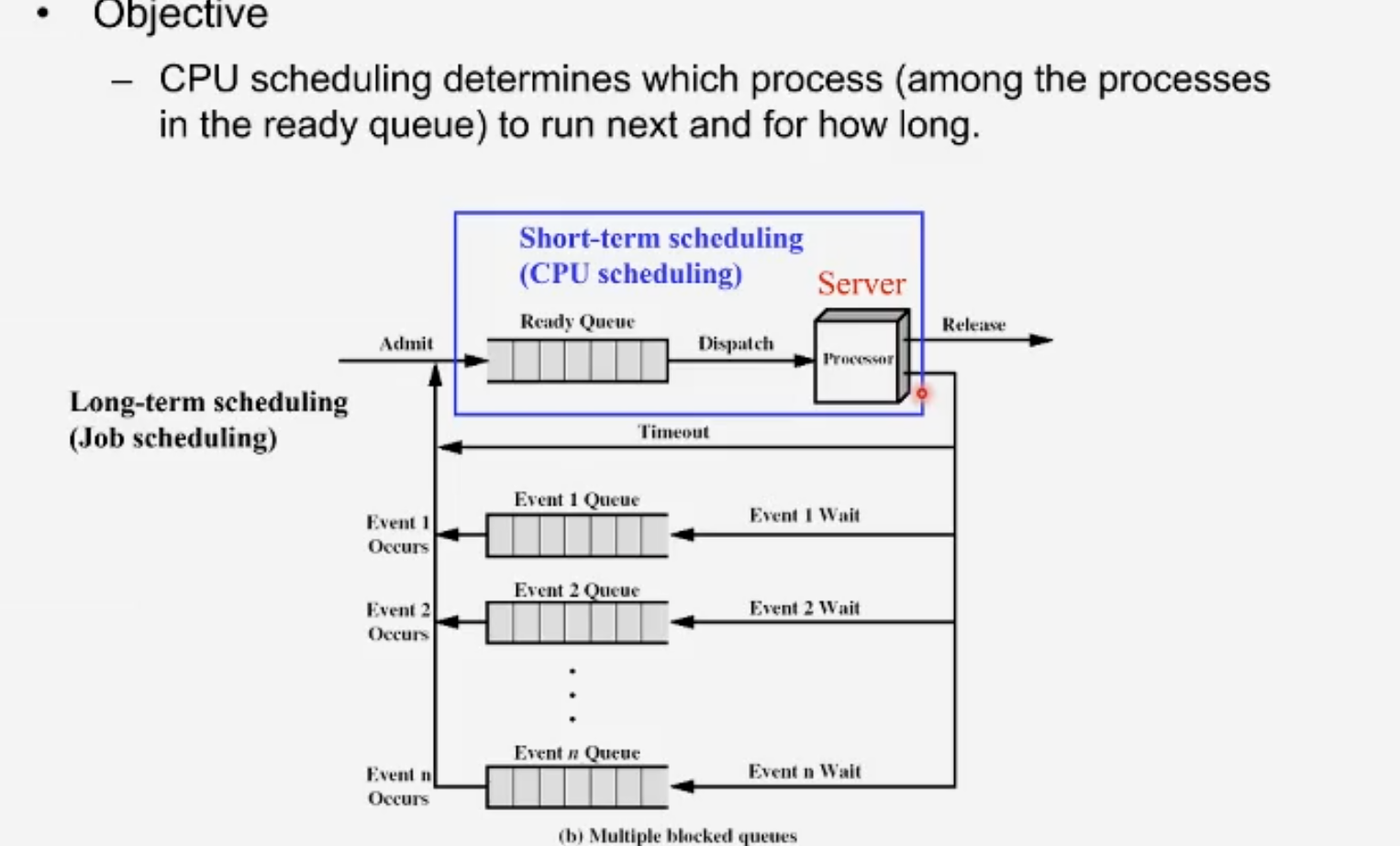
전반적인 시스템의 그림을 서버와 큐로 표시.
CPU scheduling : 서버, 즉 CPU가 큐에서 대기중인 프로세스들을 언제 선택하느냐,+ 무슨 프로세스를 선택하느냐

옛날에는 스케쥴러를 “dispatcher”라고 칭하기도 했다. 프로세스간 스위칭을 수행하는 특수한 커널의 코드를 디스패쳐라고 했다.
오늘날에는 디스패치 기능이 커널 스케쥴링 코드안에 포함되었다.
유저 관점에서 좋은 스케쥴러는 유저 프로세스를 빠르게 처리하는 것이며, 시스템 관점에서는 스위칭을 효율적으로 빨리 하는 것(dispatcher latency: CPU에게 다른 프로세스를 스위치 해줄 때 소요되는 시간)
최적화된 스케줄러를 만드는 것이 쉽지 않다. 4-50년이 지난 오늘날에도 스케줄러 연구가 이루어진다. 왜이리 어려운걸까?
CPU Scheduling Criteria

근본적으로 사용자의 입장과 시스템 개발자의 입장이 다르기 떄문이다. 사용자 입장에서는 단순하게 자신의 프로세스가 빠르게 처리되는 것이 좋고 나쁨의 기준이 된다. 달리 말해, Turnaround time, waiting time, response time이 작은 것이 좋다
반면에 시스템 개발자는 반대이다. 동시에 많은 job을 돌리면서 단일 시간에 많은 task를 처리하고 싶을 것이다. 전체 시스템의 효율성을 극대화 시킬수 있는 스케줄링을 원한다. 즉 Throughput과 CPU의 활용률(utilization)이 높은 것을 원한다.
불행하게도 시스템 개발자의 욕심과, 유저의 욕심이 compromise한다. 두 goal이 conflictg, 상충되므로 이상적인 스케줄러는 존재할 수 없다. 둘 중 하나가 좋아지면 반대편은 나빠진다.
Process Behavior : CPU-bound or I/O- bond
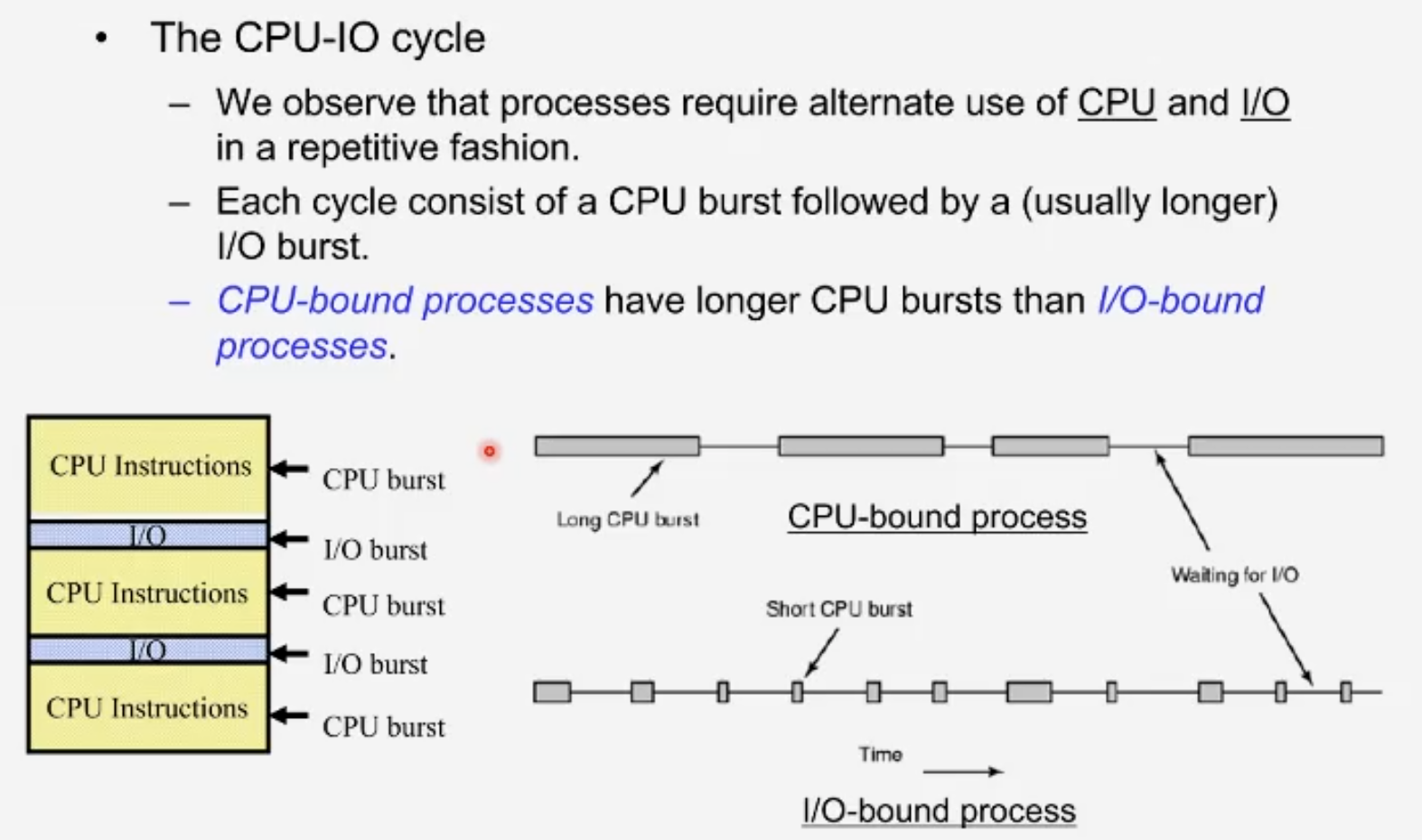
그렇다면 application의 프로세스들의 behaviour을 조사한다면, 조금이라도 어떻게든 두 입장 모두를 만족시킬 수 있는 스케쥴러를 만들 수 있지 않을까라는 생각을 했고 Process의 어떤 특성이 behaviour을 이루는지 조사했다.
- CPU-bound: 프로세스의 작업 흐름이 주로 cpu 리소스를 활용하는 프로세스
- IO-bound: 프로세스의 작업 흐름이 주로 I/O를 쓰는 특성을 갖는 프로세스
우리가 짠 코드가 백 퍼센트 CPU-bound이거나 백 퍼센트 IObound인 것은 없다. 모든 프로세스는 CPU burst와 IO burst을 반복적으로 수행하다 끝나게 된다. 다만, 프로세스는 둘 중 한쪽으로 치우칠수는 있다.
Notion of Priority

프로세스마다 스케줄링을 위한 우선순위를 부여하자. 프로세스는 태어날 떄 부터 우선순위를 부여받고, 스케줄러는 이 우선순위를 참고해 스케줄링을 실시한다.
우선순위는 프로세스들 간 스케줄링을 다이나믹하게 처리할 수 있게 해준다.
하지만, 우선순위가 무조건 장점만 있는 것은 아니다. 우선순위가 낮은 프로세스는 자칫 잘못하면 영영 CPU의 배정을 받지 못할 수 도 있다. 이런 문제를 Starvation이라고 한다.
이런 starvation과 같은 문제를 해결하기 위해 시간이 흐를 수록 해당 프로세스의 우선순위를 높이게 하는 등 여러 방면에서 다각적인 시각으로 스케쥴러를 설계해야 한다.
CPU 스케줄러 설계시 고려할 두가지 인자

Selection Function(which)
레디 큐에 존재하는 프로세스중 다음으로 CPU에게 할당될 프로세스로 어떤 프로세스를 선정할까
Decision mode(When)
어떤 프로세스를 고르는 것도 중요하지만 프로세스 교체를 언제 수행해야하나
-
Nonpreemtive
running process가 끝나거나, Running Process가 I/O block상태로 돌입될 때에만 프로세스 교체 허용
-
Preemtive running process가 끝나거나 I/O block상태로 돌입될 때 뿐만 아니라 time sharing구현시 time out이 발생되거나, 어떤 프로세스가, block상태에서 다시 레디 큐로 돌입하는 상황에서도 프로세스 교체를 허용
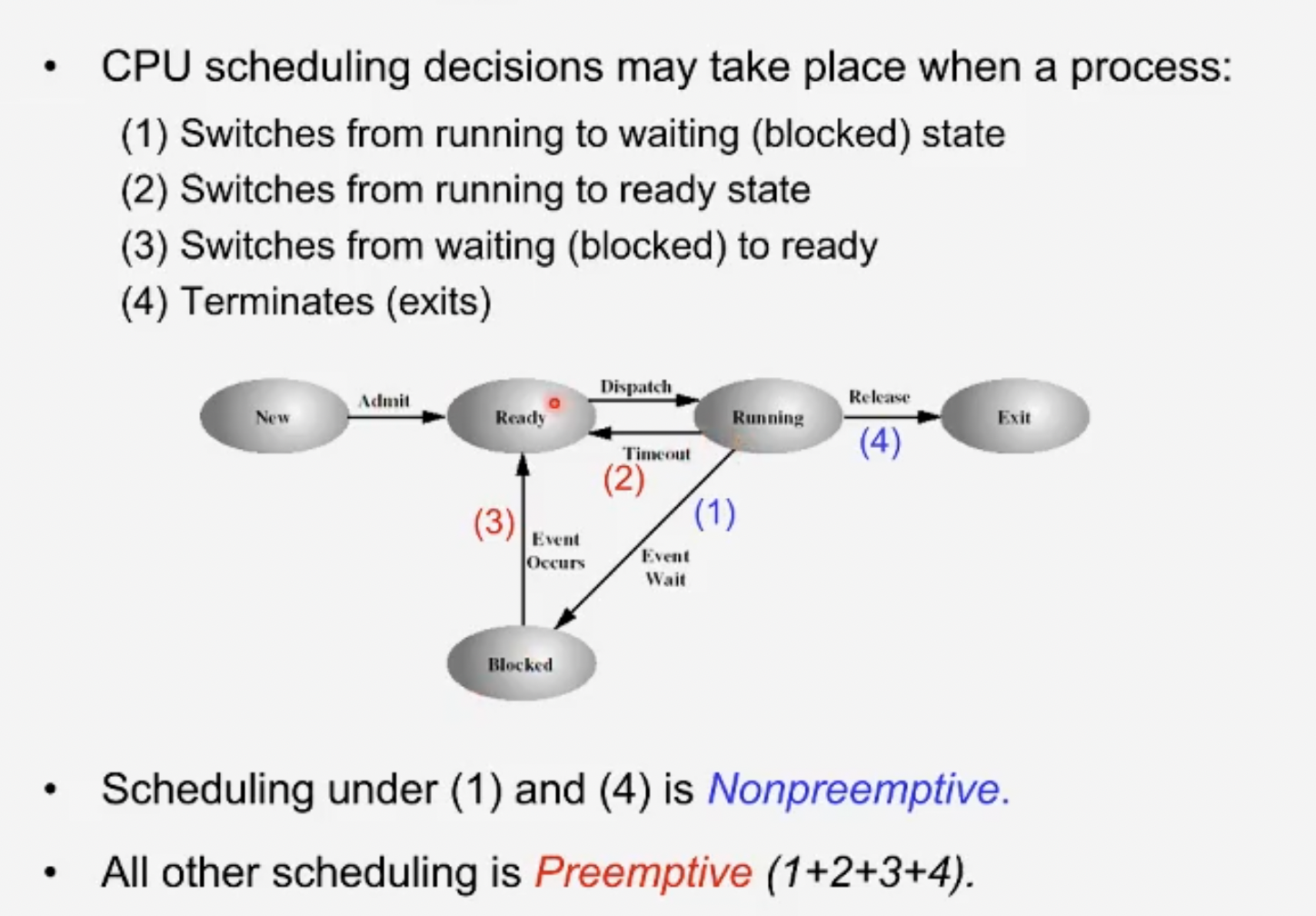
위 그림에서 Running Process를 스위칭 할 떄 1번과 4번일 경우에만 스위칭을 허용하는 스케줄링의 형태를nonpreemtive scheduler라고 한다.
1번,4번에 더해, 2번 3번 상황에서도 프로세스 스위칭을 허용하는 스케줄링의 형태는 Preemtive scheduler라고 한다.
우리가 알고 있는 거의 모든 운영체제는 Preemtive한 스케줄링을 구현하고 있다.
Legacy Schedulers
First-Come First-Served (FCFS) Scheduling

Selection function : 먼저 들어온 순서대로 다음 프로세스를 선정한다.큐에 가장 오랫동안, 가장 앞에 있는 프로세스 선택
Decision Mode: Non-preemtive. 전통적으로 non-preemtive이다. time slice를 구현하지 않는다.running process가 block될때까지 프로세스 교체는 없다
가장 원시적인 형태의 scheduler
문제점:
한 프로세스가 I/O 작업을수행하지 않는다면 이론적으로 무한히 CPU를 점유할 수 있다.
CPU-bound process들 입장에서는 유리한 스케줄러 정책이지만, IO-bound process는 CPU의 점유율이 매우 낮아지므로 불리하다.
전체적으로 user response가 감소한다.
++ 뿐만 아니라 전체 시스템의 효율도 떨어진다. I/O device의 활용율이 떨어지기 때문이다.
예시


프로세스의 실행 순서에 따라, process waiting time의 편차가 매우 크다. 극명한 문제점.
Round Robin

마찬가지로 전통적인 스케줄링 방식
selection function : FIFO
decision mode: preemtive on time quantum
시스템이 부여한 타임 슬라이스 만큼만 프로세스가 CPU를 사용할 수 있다.
단점:
타임 퀀텀의 존재때문에, 프로세스간 스위칭이 더 빈번히 발생해 시스템에 오버헤드가 커진다.
타임 퀀텀의 크기를 얼만큼 부여할지가 또 이슈이다.
타임 퀀텀이 커진다면 프로세스 스위칭으로 인한 시스템 오버헤드는 줄어들겠지만, 너무 커진다면 FIFO(FCFS)와 같아진다. 타임 퀀텀을 너무 작게 부여하면,user response는 좋아지겠지만, 시스템 오버헤드가 커질 것이다.

- Time slice 결정의 방향성(guideline)
timer interrupt handling 시스템의 시간 단위보다는 충분히 커야한다.
평균 CPU bound 프로세스의 시간보다 살짝 큰 형태로 제공하면 좋을 것이다.
⇒ 즉 적당히 커야한다.
++ round robin이 타임 슬라이싱을 사용해 FCFS보다 response time 측면에서 성능 향상이 이루어지긴 하였으나, 아직까지는 여전히 CPU-bound process를 favor하다. 한번에 다 사용하지 않을 뿐이지, CPU-bound 프로세스는 주어진 타임 슬라이스동안 100% CPU를 사용할 확률이 높은 반면, IO-bound는 Time slice를 다 쓰지 못한채 IO로 인한 block을 겪을 확률이 크기 때문이다.
기본적으로 round robin도 cpu-bound job을 favor하는 정책일수 밖에 없다.
예시

Shortest Job First(SJF) Scheduling

Shortest Job Firsts는 IO bound를 favor하는 스케줄링 알고리즘이다.
Selection function: ready queue에 있는 프로세스들을 스캔, 조사한다. 이들 중 수행 시간이 짧은 것을 골라내서 수행하겠다
Decision Mode: 두가지 모두선택이 가능하다,
- Nonpreemtive: 타임 슬라이스도 없이, 한번 할당되면 IO/block되거나, 끝날때가지 교체는 없다.
- Preemtive: 새로운 ready queu의 프로세스가 더 shorter job을 지닌다면 그즉시 실행 프로세스를 교체한다. → 이런 형태를 Shortest-Remaing-Time-First라고 한다. 항상 burst 중 남아있는 것을 기준으로 적은 것을 고르겠다.
IO/bound 프로세스가 반드시 먼저 선택되게 된다.→ IO bound favor scheduler
문제점:
반대로, CPU-bound process는 영영 starve하는 문제가 발생할수도 있다.
각 프로세스들마다의 CPU burst 시간을 알아내기 힘들다.
⇒ SJF 알고리즘은 오직 이론상에서만 존재한다. 현실적으로, 프로세스들의 CPU burst를 정확히 알아낼 수 없기 때문이다. 오직 예측을 할 뿐이다. 이론적으로는 매우 optimal한 알고리즘이다.
예시 Nonpreemtive SJF
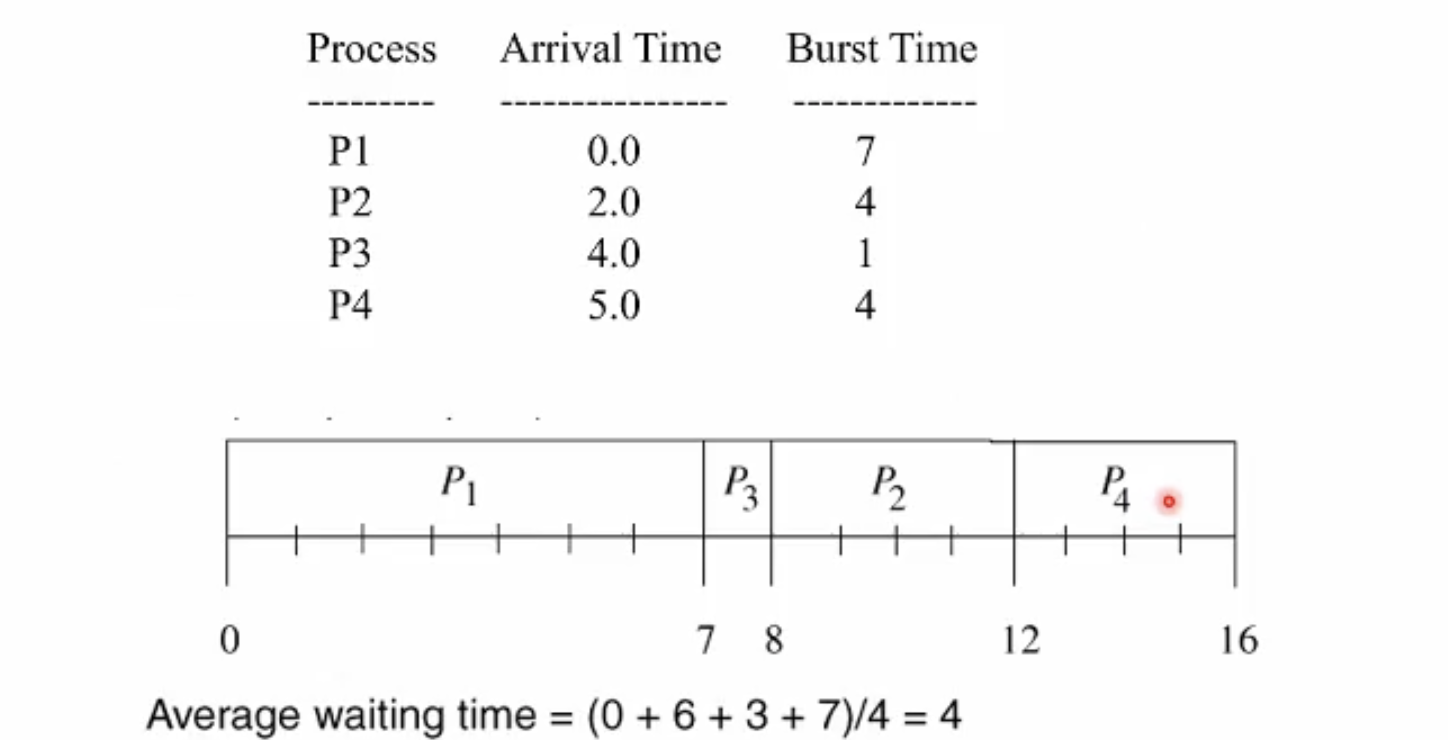
예시 Preemtive SJF
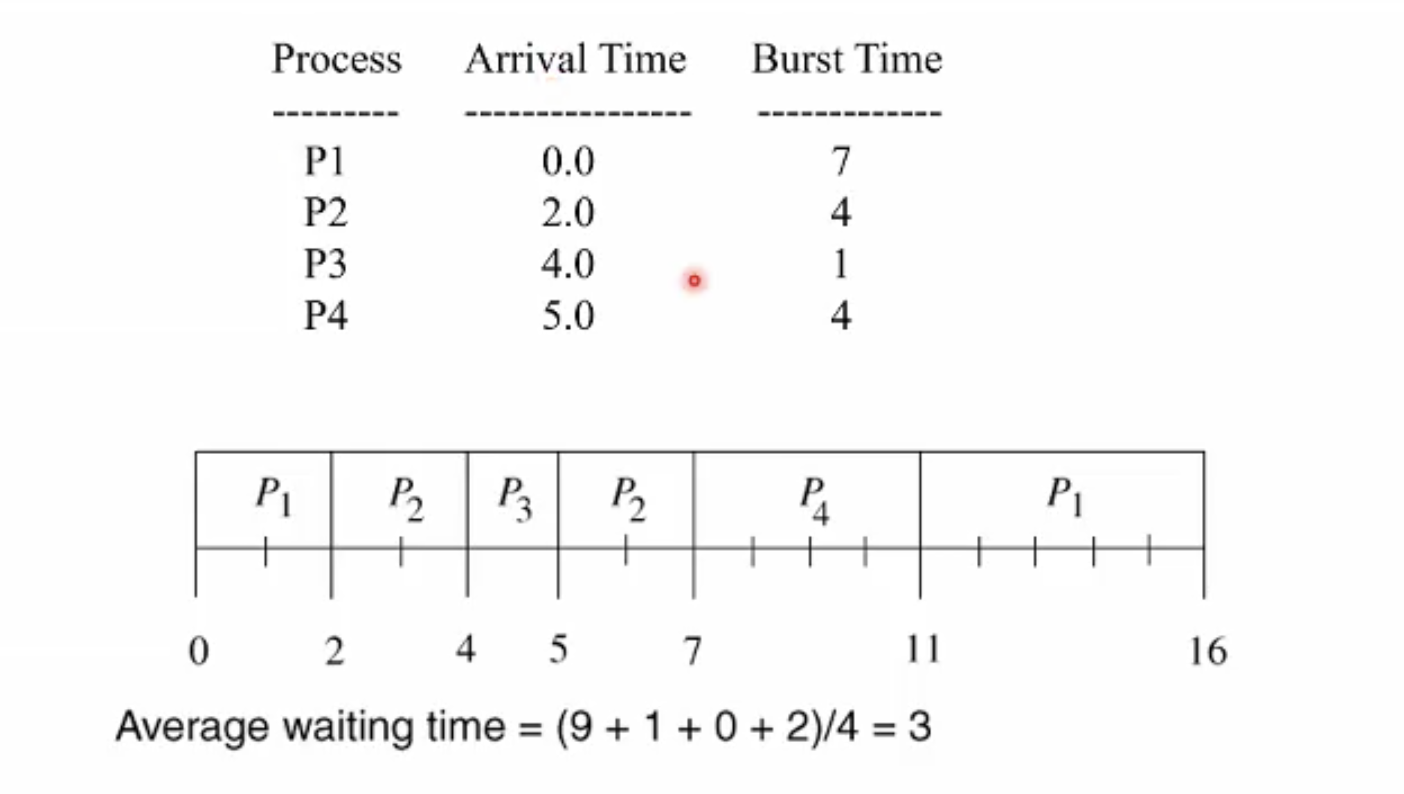
Preemtive의 response time이 non preemtive sjf에 비해 더 적지만 프로세스 스위칭 횟수는 더 많다. 즉 response time과 스위칭 오버헤드 사이에서 trade off가 있다.
Estimating CPU Burst

SJF를 현실적으로 구현하려면 어느 순간에 어떤 프로세스가 얼만크의 CPU burst가 남았는가를 운영체제가 예측해야한다. 현실적으로 완벽한 계산은 불가하므로 타당한 예측을 해내야한다.
어떻게 예측을 할 것인가? →정답은 절대 못구하지만, 어느정도 근거를 가지고 예측할 수는 있다.
어떤 프로세스가 지금까지 수행되어온 과거 history를 보고 예측하자!
모든 프로세스의 과거를 기록해서 그다음을 예측해 보자.
- Simple Averaging
과거 각 프로세스의 cpu burst 기록들의 평균치를 다음 Cpu burst의 예측치로 선정하자. 수식은 위 슬라이드 참조
- Exponential averaging
시간의 흐름에 따라 CPU burst가 다를 수 있는데 이것이 바로 process의 locality(지역성)이다. 시간적/공간적 locality가 존재하기에 process behavior 측면에서 살펴봤을 때 cpu burst의 예측에 가중치를 둬야 한다. 모든 시간대의 cpu burst를 균일하게 취급하는 것은 타당하지 않다.
즉 가장 최근의 cpu burst 패턴이 먼 과거의 cpu burst보다 다음 예측치에 더 근접할것이라고 상식적으로 생각되기에 예측치를 산정할 때 시간의 흐름에 따라 다른 가중치를 부여하자.
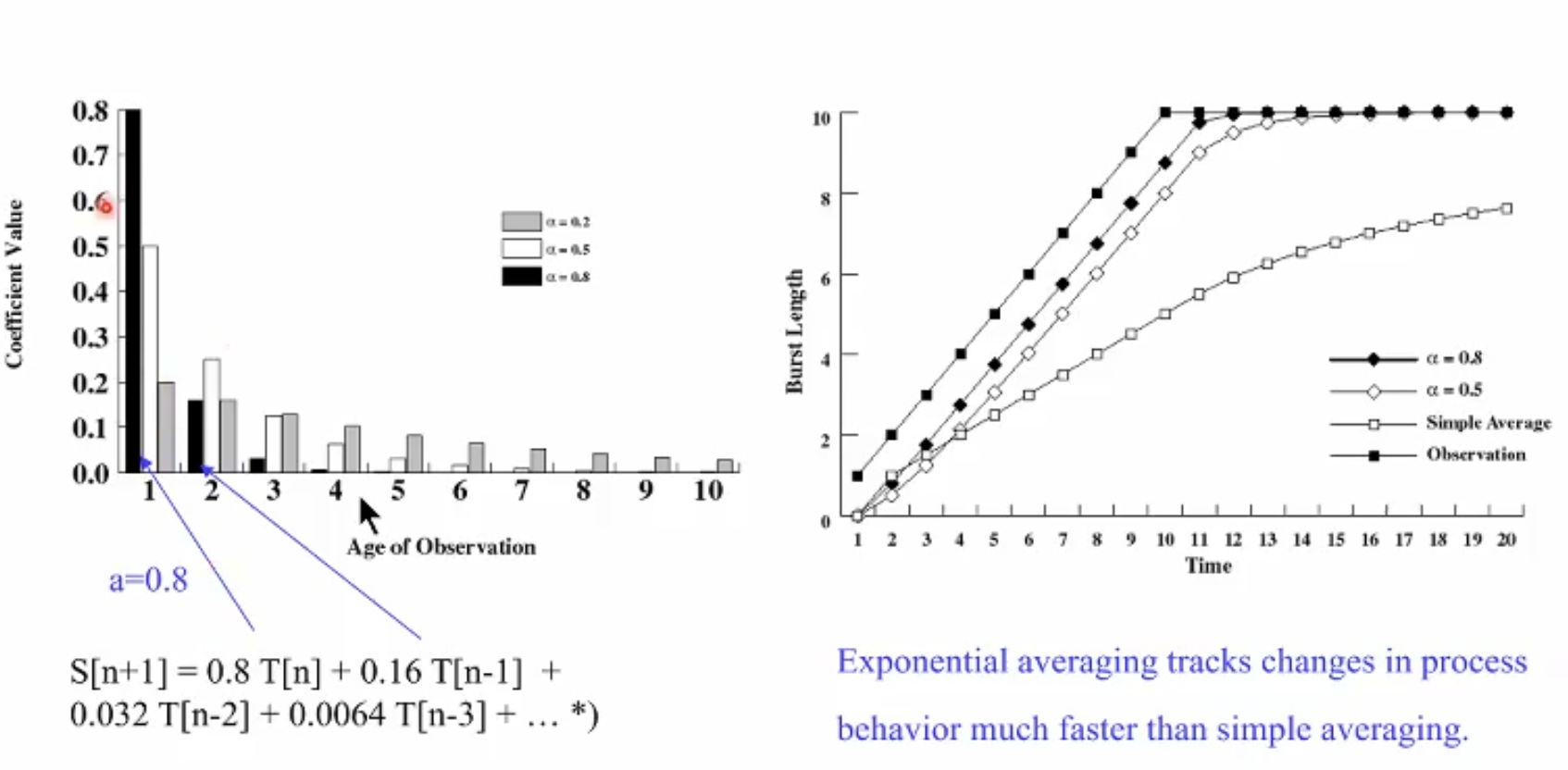
예시를 보면 수식의 알파 값(상수) 에 따라 과거 기록들의 가중치가 다르게 적용되는 것을 볼 수 있다. 알파 값을 조절해서 시스템 개발자가 적절히 sjf 구현을 위한 각 프로세스들의 cpu burst시간을 예측하는 것이다.
Exponential averaging 은 스케줄링 뿐만 아니라 CS의 여러분야에서 널리 사용된다. 현실적으로 우리가 어떤 문제를 해결하기 위해 어떤 행동을 예측해야한다면 과거의 값을 통해 예측값을 산정하는 수 밖에 없다. 스케줄링 뿐만 아니라 널리 사용됨
Multilevel Queue Scheduling
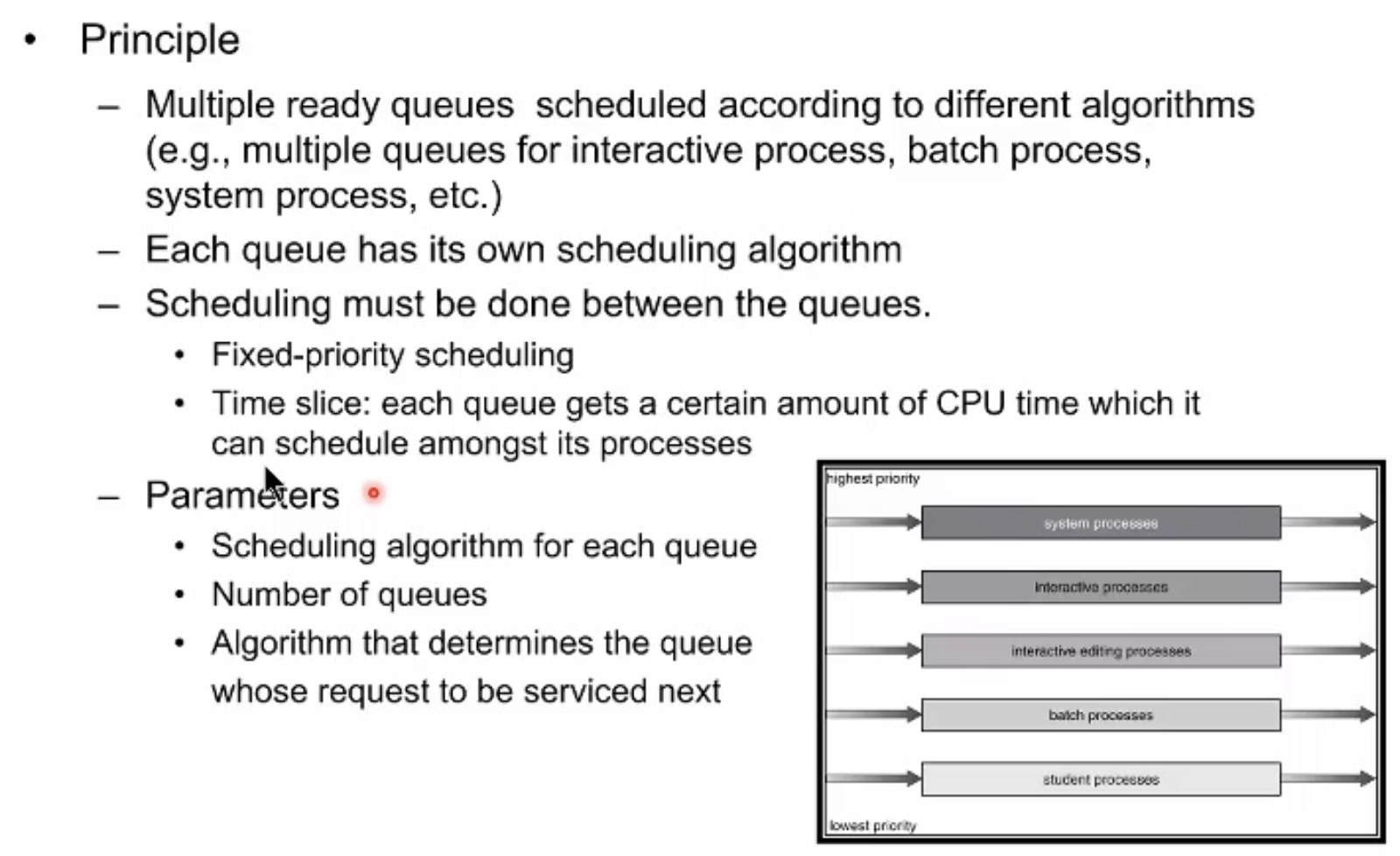
실제 운영체제가 구현하는 스케줄러는 간단치 않다. 운영체제가 복잡해짐에 따라 위에서 살펴보았던 기본 primitive scheduling 형태들을 여러개 조합해서 사용한다.
먼저 스케쥴러의 레디 큐를 여러개 가져간다. 위에서는 하나의 레디 큐에서 설명했지만 multi livel queue에는 여러 우선순위를 가진 여러개의 큐들이 존재한다.여러개의 큐중에 어떤 것을 먼저 수행할지, 우선순위를 어떻게 부여할지 등등 여러가지 제네릭한 사항들을 고려해서 설계된다.
Multilevel Feedback Queue
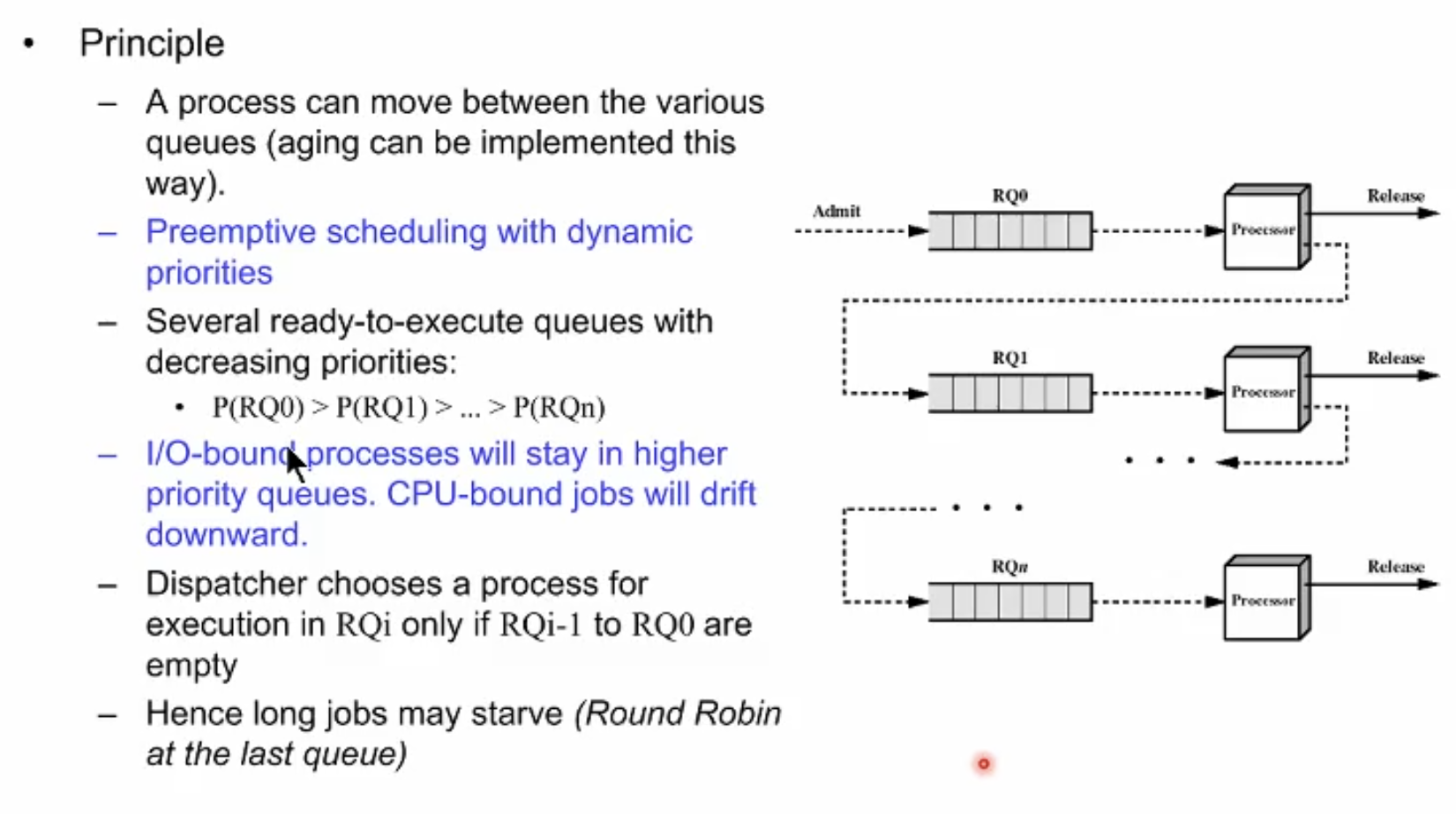
아주 옛날 리눅스 초창기의 스케줄링 방식
앞선 multilevel의 특징은 레벨간의 연결이 존재하지 않았었다. 하지만 여기서는 n개의 큐가 연결되어 있어서 feedback이 된다. 예를 들어 첫번째 프로세스가 CPU를 받은 후 IO block으로 나가게 되면 대기했던 큐가 아니라 한단계 더 낮은 우선순위의 큐에 들어가게 되고 이같은 과정을 반복하는 소위 feedback을 하는 다중 큐 설계이다. 큐마다 우선순위가 존재한다. 한 레벨의 큐의 프로세스를 실행하기 위해서는 더 상위 우선순위 큐들에 대기중인 프로세스가 없어야한다는 조건이 있다.
현실적으로 IO-bound와 CPU-bound process를 잘 balancing해서 스케줄링할 수 있는 기법이다.
보통 첫번 째 큐의 timeslice를 매우 작게 둔다. 즉 매우 짧은 시간 동안 모든 CPU작업을 할 수 있는 IO-bound process는 상위 큐에서 대부분 작업을 마치게 된다.
하위 큐들로 갈 수록 time slice가 길어진다. 즉 cpu를 많이 써야하는 cpu-bound process 들은 상위 큐의 짧은 타임 슬라이스 내에 작업을 다 처리할 수 없으므로 점점 더 하위 우선순위의 큐들로 feedback되게 된다.
가장 하위 순위의 큐에서는 더이상 feedback하며 내려갈 큐가 없으므로, round robin으로 작동하게 된다.
일반적으로 프로세스가 IO interrupt가 된 후 io처리 후에 다시 큐로 들어 올때 원래 위치했던 우선순위에 맞는 큐로 돌아간다고한다.
단점은 극단적인 cpu-bound process들이 starv할 수 있다.
Fair Share Scheduling(FSS)

실제 운영체제에서는 사용자들이 여러명일 수 있다. 실전에서는 여러 사용자들간의 CPU usage를 잘 분배해야한다. 특정 사용자가 독점하면 안된다.
이런 취지에서 나온 스케줄링 알고리즘이 FSS이다. 모든 유저가 공평하게 CPU를 할당받을 수 있게 하는 스케줄링 정책이다. n개 유저가 있고, 유저가 만들 수 있는 프로세스에 제한은 두지 않지만 유저에 속한 모든 프로세스가 수행할 수 있는 타임 슬라이스는 똑같이 줘버린다.
예를 들자면 유저 a가 프로세스를 열개 사용하고 유저 b가 프로세스를 한개 사용할 때, 유저 a 의 프로세스가 10배 더 많더라도 할당된 cpu 할당 시간은 유저 a와 유저 b가 똑같다.
Multiple-Processor Scheduling
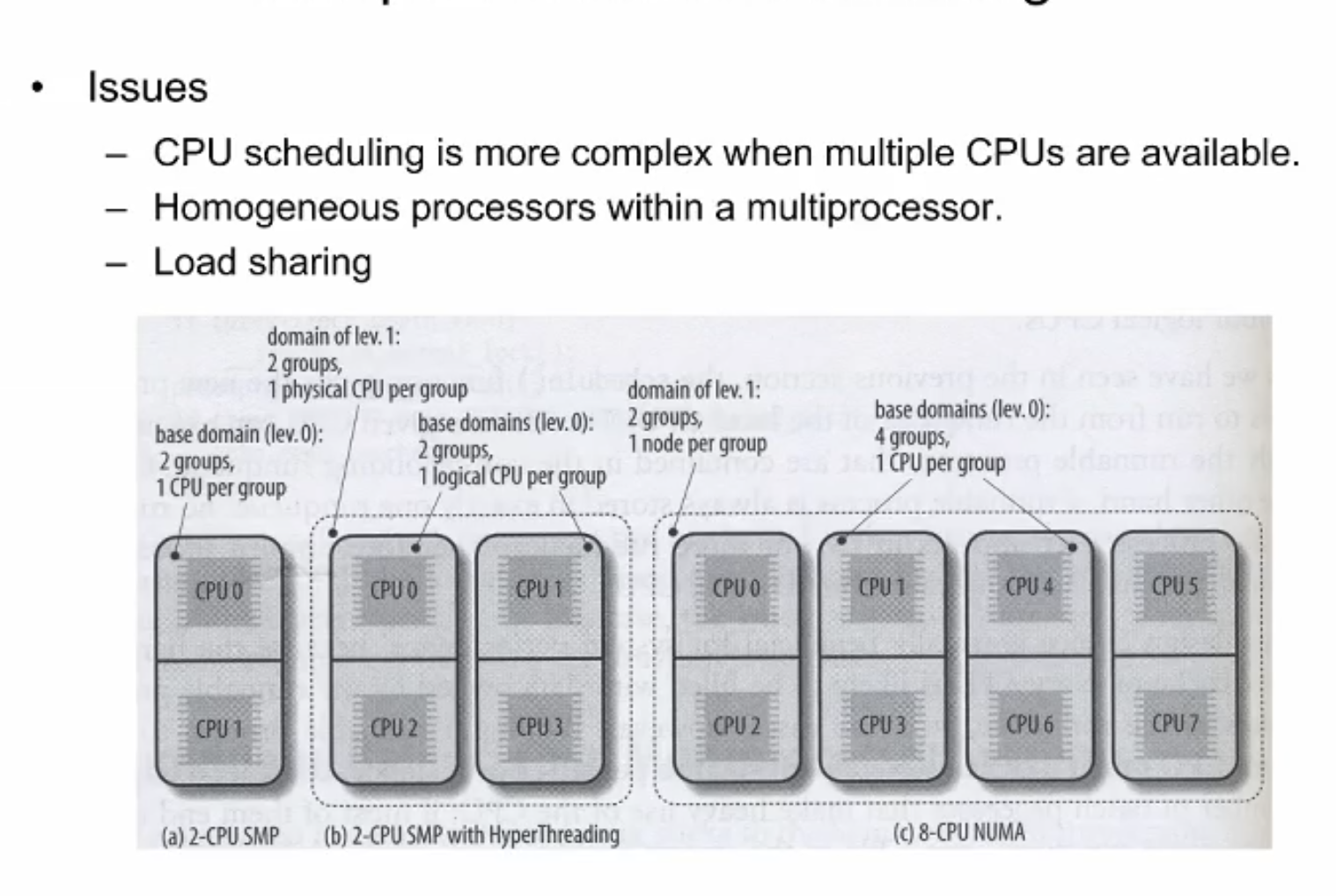
오늘날 대부분의 cpu들은 다중 코어를 지니고 있다. 그중 어떤 코어들은 저전력 코어이며 어떤 코어들은 고전력이지만 상대적으로 빠른 코어들도 있다.
다양한 형태의 병렬 아키텍쳐가 있다. 이러한 측면에서 운영체제는 다시 고민된다. 운영체제가 핸들해야할 수 있는 프로세스가 여러개 있고, 프로세스를 처리할 CPU도 여러개 있는 것이다. 그러면 스케쥴러가 어려워진다. 어떤 프로세스를 어떤 CPU에 할당되어야하는지의 이슈도 발생한다. 우선 모든 CPU코어가 동일하게 쉬지 않고 효율적으로 사용되어야하는 동시에, 기존의 스케줄링 이슈들을 다뤄야하는 것이다.
추가로 모바일 환경에서는 배터리를 사용한다. 스케줄링 + 프로세서에 균등하게, 효율적으로 할당하는 이슈 + 전력 소모 감소의 이슈까지 더해지게 된다.
이러한 문제들을 Load sharing이라고 한다.
유닉스 운영체제의 스케줄링

interactive scheduling : IO-bound process, 유저가 사용하는 프로세스
batch process: CPU-bound process 한번 실행되면 background에서 유저 상호작용 없이 돌아가는 프로세스
전통적으로 유닉스 운영체제는 interactive process를 우선적으로 스케쥴링 대상으로 삼으려는 철학을 펼쳤다.
구현적으로는,
MLFQ를 사용, 큐마다 다른 스케쥴링 알고리즘 적용, preemtive 등등 여러가지 기법들을 조합해서 사용했다. response time을 줄이고 IO-bound process boost를 위한 방법들이다.
Hard Real-Time Scheduling

간혹 이야기가 나오는 시스템이 실시간 시스템이다. 실시간 시스템, real time이라는 것은 각 process를 실행시킬 때 운영체제에게 deadline을 주는 것이다. 반드시 주어진 시간 내에 해당 job을 끝내야하는 시스템인 것이다.
군사시스템, 산업 등 특수분야에 쓰인다.
간단치 않은 과제다. 각 시간 내에 해당 job을 수행할 것을 보장해야 하기 때문이다. 이 학문 분야는 대부분 수학이고 이론적이다. 90년대에 많은 연구가 이루어짐.
이 시스템은 가상메모리도 사용하지 않는다. 페이지 폴트가 발생하면 예상치 못한 시간소요가 발생하므로 예측이 안된다. 따라서 가상메모리가 사용될 수 없는 것이다.
진짜 real time system → hardware time system 도있고
Soft Real-Time Systems

위의 진짜 real time system은 현실적으로 구현에 어려움이 있다.
조금 약한 real time, 진짜 realtime은 아니다.
critical process들의 수행시간을 보장하려고 최대한 노력하는 시스템이다.
하지만 보장이 될수도 안될수도 있다.
위급상황에 대처하기 위해 커널을 preemtable하게 만듬. 얕게 설명하자면, unpreemtible os는 스위치를 아주 안전한 타이밍에서만 수행한다. 하지만 preemtable kernel은 커널모드에서도 꽤 자주 프로세스 스위칭을 하는 것이다.
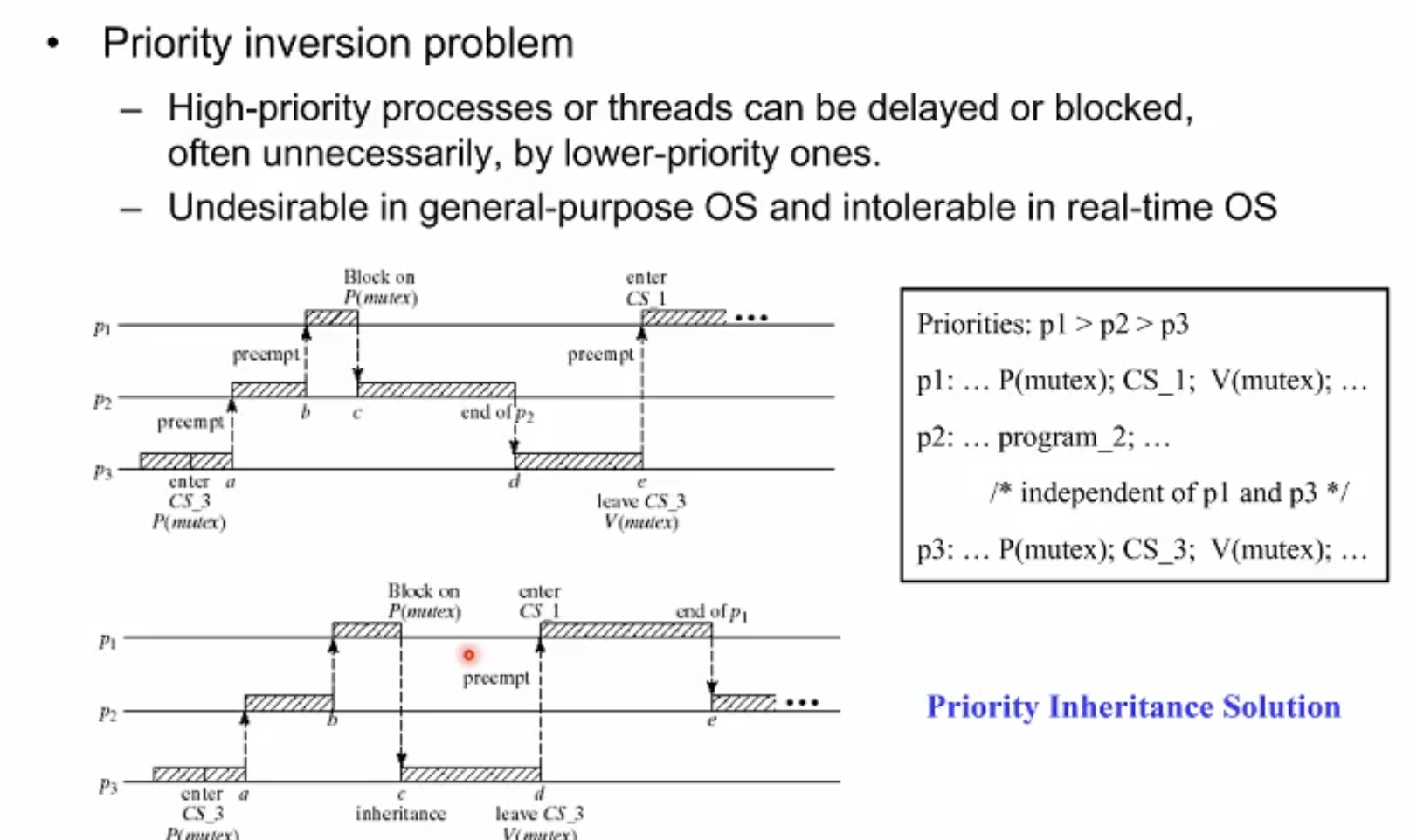
real-time os에서 풀어야하는 대표적인 문제가 있다. 바로 Priority inversion problem이다.
예제를 보면, 세개의 프로세스가 시스템에서 수행되고 있다. p1이 우선순위가 가장 높고 p3가 우선순위가 가장 낮다. 어느 시점에서 p3가 자신의 코드의 특정 영역을 수행하다가, 여러개 프로세스가 공유할 수 있는 글로벌 공간에 접근하고 read write을 수행한다..(기술적으로 critical section이라고 칭한다. 후 강의에서 자세히 설명) 이때 보통 lock을 한다. 락을 건 상태로, p3가 자신의 할당 time을 다 써서 프로세스 스위치가 일어나게 된다.
하필, 이후에 p1이 p3가 락을 걸어놓은 글로벌 공유 공간을 접근해야한다면 어떻게 될까? p1은 우선순위가 가장 높은데도 불구하고 block 상태가 되고 자신보다 한참 낮은 우선순위에 있는 p3가 락을 해제할때 까지 block을 할 수 밖에 없다. 다시말해 p2,p3가 우선순위가 p1보다 낮은데도 불구하고 먼저 수행을 마치게 된다. 때문에 이런 문제를 priority inversion이라고 한다.
이 문제의 해결책 중 하나로 priority inheritance solution가 존재한다.
아까와 같은 상황에서, p1이 공유데이터에 접근할 때 p3에 의한 락이 있다면 p3의 우선순위를 순간적으로 먼저 높여준다(정확히 말하면 p1의 우선순위를 부여받는다). 이러면 p3가 우선적으로 수행되므로 걸었던 락이 p2수행을 기다릴 필요 없이 해제될 것이고, 락이 해제된 이후에는 다시 p1이 작업을 재게하고 이후에 p2가 수행하는 식으로 priority inversion 문제를 해결하게 된다.
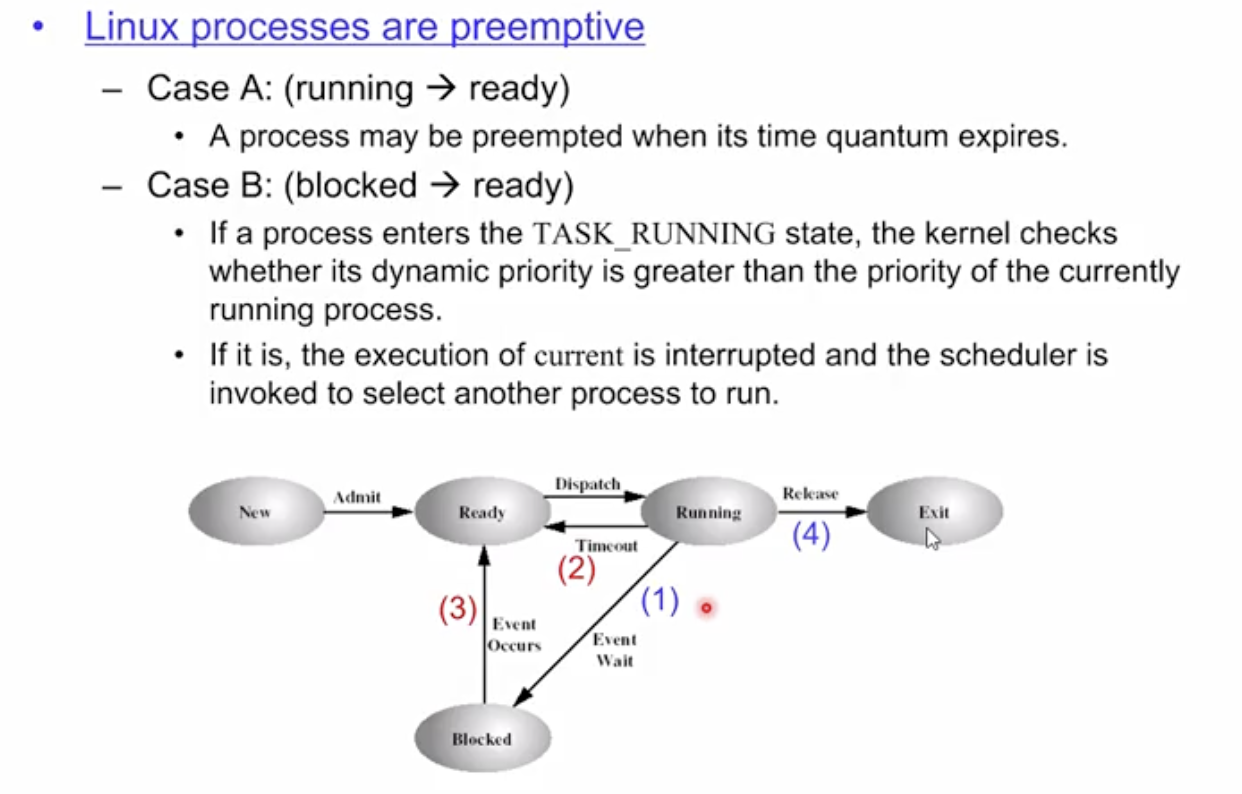
Linux Scheduling

간단하게 리눅스 스케줄러를 살펴보자
리눅스 스케줄러는 버젼별로 여러 개가 존재한다. 크게 3개의 세대로 나눌 수 있다. 최근거는 가장 복잡해서 2세대 스케줄러를 예로 든다.
이것 역시 time sharing이고 preemtive스케줄러이며 dynamic priority, static priority 모두 지원한다.

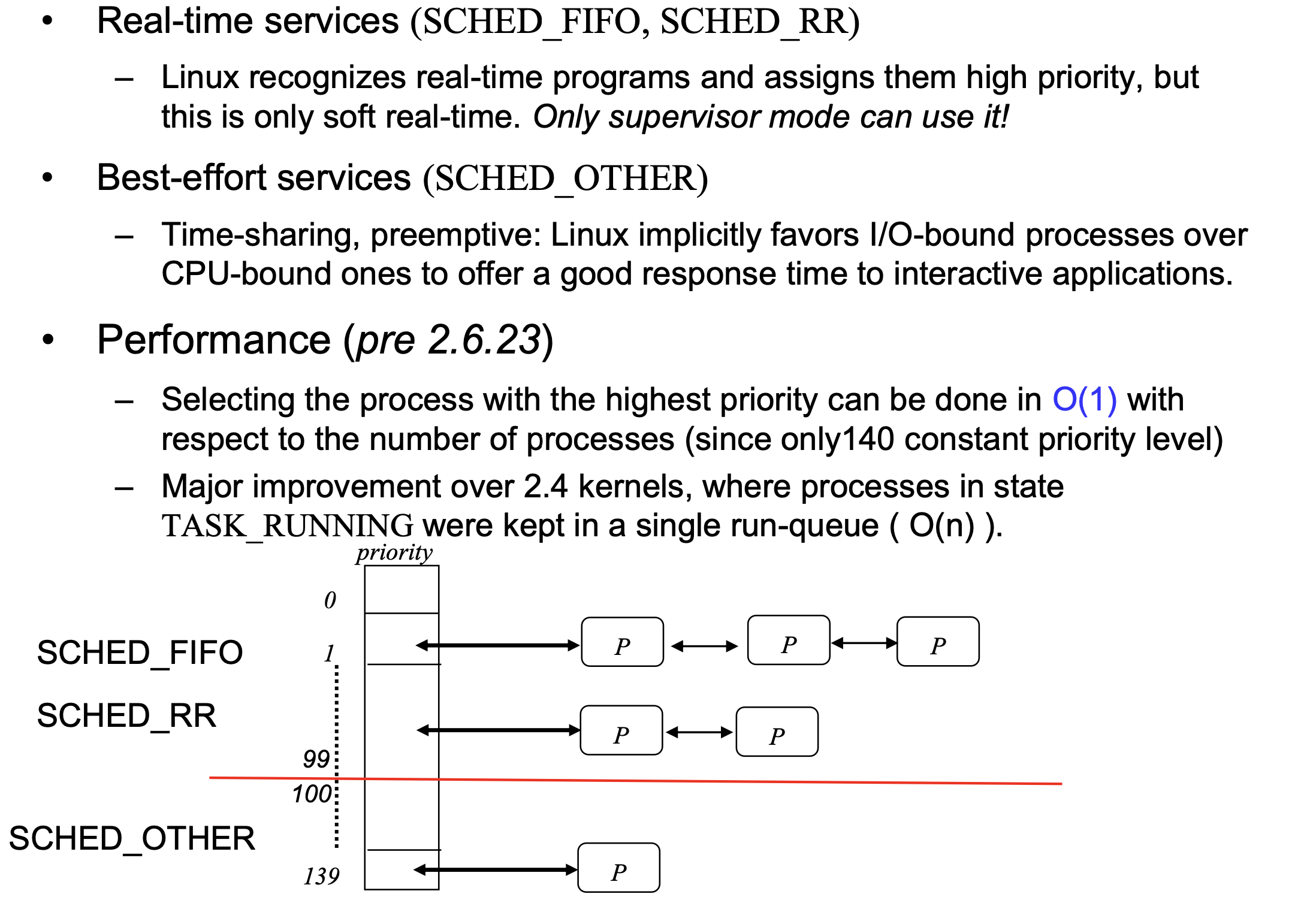

![Untitled](/assets/img/L5-Process%20caf40/Untitled%2032.png{: width=”70%” height=”70%”}{:.aligncenter}
댓글남기기