L6-Process Synchronization
연세대학교 차호정 교수님의 운영체제 강의를 듣고 작성한 강의록
Synchronization

프로세스 동기화가 무엇을 의미하고 동기화를 제공하기 위한 primitive가 어떻고, 역사가 어떠하고 현실에서 어떤 기법들이 쓰이는가
멀티스레딩이란?
두 개 이상의 스레드가 하나의 코드와 데이터와 힙과 라이브러리와 커널 컨텍스트를 공유하는것. 따로 갖는것은 local stack과 program context만 따로 갖는다. 가급적이면 많은 것을 공유하고 total resource를 줄이기도 하고 하나 안의 스레드가 다른 cpu에서 돌 수 있기 때문에 병렬화에 따른 이득을 얻는 두마리 토끼를 얻는 기법.
하지만 문제점도 존재 존재. -> Synchronization의 문제가 존재
예를 들어 공유하는 자원중 하나인 global data영역에 한쪽은 읽기 접근을, 한쪽은 쓰기 접근을 동시에 시도한다면 global 데이터 영역의 내용이 invalid할 가능성이 있다.
Sharing Resources
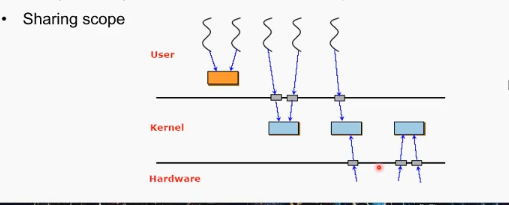
시스템 콜을 하면 모드스위칭이 시작되고 커널에서 시스템 콜에 관한 내용을 수행한다. 이 상황에서 interrupt가 발생한다면? 시스템 콜을 수행하는 와중에도 커널은 interrupt handler를 돌려야한다.하지만 이때, 만일 system call handler와 interrupt handler가 커널의 특정 자료를 공유한다면? 이런 경우에는 글로벌 데이터 영역을 적절히 보호해주지 못한다면 붕괴가 발생하게 된다.
마찬가지로 interrupt handler 두 개 이상이 동시에 발생하고 커널이 동일한 자료구조를 쓰는 경우, 혹은 두개의 유저 스레드가 커널의 자료구조를 동시에 콜하는 경우 등이 있다.
위의 상황 뿐만 아니라 cpu가 여러개 돌아갈 수 있고(병렬 컴퓨팅) 거기서 엄청나게 많은 스레드가 존재하는 경우 등 동기화 문제는 항상 존재함.
Example: Bounded-Buffer
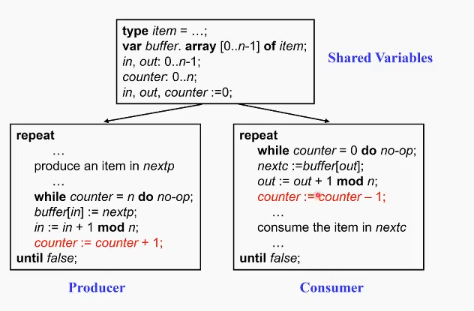
producer-consumer모델
병렬처리에 대한 여러가지 메커니즘을 설명할때 사용하는 단골 예시.
두개의 프로세스가 공유 데이터(shared variables) 를 가진 상황. producer는 뒤에서부터 큐에 데이터를 넣고 컨슈머는 앞에서부터 큐의 데이터를 꺼내온다. 하지만 producer와 consumer는 동일한 속도로 돈다고 보장하지 못한다. 두개 프로세스가 concurrent하게 돌아갈 때 어떻게 crash없이 잘 풀어낼까? 어떻게 하면 공유데이터에 대한 제어를 잘 해낼 수 있을까?
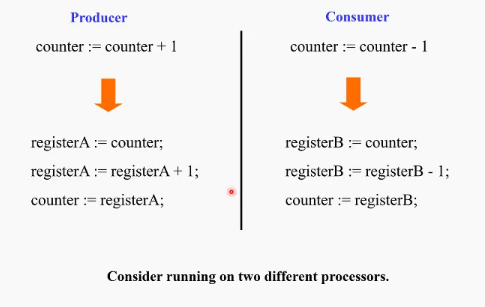
이예시에서 두 producer consumer의 코드가 별개의 cpu에서 거의 동시에 돈다고 가정해보자. 거의 동시에 register A와 register B가 load를 하는 경우가 있을 수 있다. 그렇다면 counter는 +1 된 값과 -1 된 값이 동시에 계산되게 되고 결국 counter에 늦게 저장하는 값이 최종 값으로 저장되어버리는 문제가 발생할 것이다.

동기화 문제란 두 개이상의 프로세스나 스레드가 공유데이터에 대한 동기화를 고려하지 않을 때 발생하는 race condition의 문제임.즉 시간차에 따른 non-deterministic한 결과가 초래되는 문제이다.
Race condition을 피하기 위한 적절한 primitive가 필요
Synchronization Problem

두 개 이상의 동시에 실행되는 프로세스 혹은 스레드가 동기화를 고려하지 않고 공유 자원에 접근하려는 문제.
Race Condition을 초래함.
→ non deterministic, 아주 나쁜 상황. 컴퓨팅은 deterministic한 결과를 내야하지만 그렇지 못하게 된다.
어떻게 하면 race condition을 피할 것인가 적절한 형태의 primitive를 제공해야한다.
Critical Section
critical section: 두 개 이상의 스레드나 프로세스가 공유할 수 있는 코드 영역을 의미한다.
critical section에 대한 데이터만 잘 관리해주면 race condition을 해결 가능.

entry section: 데이터에 접근하기 전에 먼저 이 데이터에 접근한다는 것을 선언하는 영역, 락을 거는 영역
exit section : 접근했던 자원의 독점을 해제, 락을 해제
critical section 제어를 위한 entry section, exit section을 컴파일러든, os든 프로그래머든 잘 정의, 제공해주어야한다. 즉 한 프로세스/스레드가 critical section을 사용 중이라면 다른 process/스레드는 절대 접근 못하게 어떤 방식으로든 구현 해줘야함.
- 크리티컬 섹션이 만족해야하는 세 가지 조건.

- 상호 배제: 크리티컬 섹션을 제공하기 위한 근본적인 요구사항. 누군가가 쓰면 다른 사람들은 못 씀. 가장 기본적인 mandatory solution
- progress: 아무도 크리티컬 섹션을 사용하지 않는다면 다른 쓰길 원하는 프로세스/스레드가 생긴다면 그들에게 할당할 수 있어야한다 .(당연한 것 같지만 사실은 복잡한 문제)
- bounded waiting: 크리티컬 섹션 접근을 위해 기다리기는 기다리되, 기다리는 것에 bound를 주어 starvation을 피해보자.
1번은 필수이며 2번 3번은 구현에 따라 있을수도 없는것도 있음.
Critical Section 해결책에 대한 두가지 분류

-
low level 동기화:
간단히 얘기해서 lock이라고 지칭함. 아주 primitive하고 기본적인 최소한의 semantic. high level primitive에서 기본 단위로, 모듈로 쓰이게 됨.
이론적으로 락 구현도 여러가지 접근법이 있음
- Software-only 만으로, 알고리즘으로 lock을 구현하자는 접근법.
- hardware instruction set으로 lock을 구현하자는 접근법.
- Interrupt를 쓰지말자(커널 의 크리티컬 섹션이 누군가에 의해 쓰이면 interrupt자체를 못하게 cpu가 막아버리자) 는 시스템차원의 접근법
-
High level 동기화:
프로그램 언어, 운영체제적인 해결책, 기능과 자료구조를 제공하기.
7-80년대에 핫한 분야, 동기화 이슈를 다루는 여러 언어가 생기기도 함(concurrent c, concurrent pascal)
Lock(Low level synchromization primitive)

한 프로세스가 공유데이터를 쓰면 다른 프로세스는 기다리게 하는 것.
acquire()/lock(): 쓰는 프로세스는 lock()을 콜하고, 기다리는 프로세스는 acquire()을 함.
release()/unlock():다쓴 프로세스는 unlock을 해주고 release를 해서 다른 프로세스가 쓰게 해줌.
spin lock이라는 것은 한 프로세스가 쓰는 동안 다른 기다리는 프로세스가 spin하면서 계속 다 썻는지 체크한다는 것, 스핀락은 단일 cpu에서 구현하기 쉽진 않다.(동시에 한 프로세스가 사용하고 다른 한 프로세스는 대기하므로 병렬 cpu가 구현에 유리)
어떻게 동시에 두개의 프로세스.스레드가 글로벌 자료구조를 동시에 접근하지 않게 할 것인가.
Lock은 Serialize를 시키는 것. → 순서화 시키기!
Software-only Solution : two-process case
많은 솔루션이 있지만 이해를 위해 간단한 예시를 듬.
두개의 프로세스가 있는 상황. P0, P1
두개의 프로세스가 공유하는 turn이라는 공유 변수를 저장.
turn이 0이면 P0가 쓰고 trun이 1이면 P1이 사용 가능하다는 의미

while문으로 소프트웨어적으로 entry조건,exit 조건 구현. 턴이 자기 차례가 아니라면, 아무 일도 하지않고turn 이 자기 차례라면 크리티컬 섹션에 진입한다. 이후 크리티컬 섹션을 사용한 후에는 turm을 j로 넘겨준다.
이 솔루션이 과연 좋은 think primitive일까?? 좋은 primitive의 세가지 조건, mutual exclusive, progress, bounded waiting 이 세가지 조건을 다 만족하는가? -> Progress 조건을 만족하지 못함.
내가 쓰고 나면 무조건 상대 프로세스에게 턴을 넘겨야 하고 다시 턴을 받아서 써야 하는데, 만일 내가 다 쓰고 넘기려 하는데, 상대방이 계속 도착을 하지 않는 상황, 즉 상대방이 크리티컬 섹션을 사용조차 않하는 상황이 발생한다면 무한히 상대 프로세스가 올때까지 크리티컬 섹션이 비어있음에도 불구하고 계속 기다려야함.
핑퐁과 같다. 내가 상대에게 턴을 넘겨주고 나오면 반드시 상대방이 나에게 턴을 넘겨줘야만 내가 크리티컬 섹션에 진입할 수 있다
즉 progress 조건을 만족하지 못하기에 좋은 해결책은 아니다..
- 두번째 알고리즘

각 프로세스가 bool flag를 가짐. 내가 크리티컬 섹션을 쓰기 전에 깃발을 올림. 만일 그 순간에 이미 다른 프로세스가 깃발을 올리고 있으면 쓰지 않음(no operation는 spinlock을 한다는 의미이다) 나 제외 깃발이 안올라와있으면 크리티컬 섹션 진입. 다 사용한 후에는 깃발을 내림
process마다 로컬 변수를 둬서 진입을 제한. 1번 알고리즘의 progress를 해결하기 위해 나온 알고리즘. 즉 원하는 사람이 비어만 있다면 언제든 진입하여 쓰기 가능
하지만 이것 마저도 progress조건을 맞추지 못할 수 있음. 만일 어느 상황에서 동시에 크리티컬 섹션에 들어가려고 진입 시도, 두 프로세스가 모두 동시에 flag를 올림. 즉 아무도 크리티컬 섹션을 사용하지 않는데도 대기하게됨. 서로 flag가 올라가 있는데 크리티컬 섹션은 아무도 사용하지 않는 그런 상황이 발생할수 있음. 즉 무한히 대기하므로 progress 조건을 만족 못함.
- 3번째 알고리즘 - 피터슨 알고리즘

1번 2번을 섞어 쓰는 알고리즘
똑같이 flag를 둔다. 진입을 위해 플래그를 올리고 이후 턴 값을 상대 값으로 세팅한다. 상대의 Flag도 올라오고 턴 값도 상대의 값이라면 진입을 미루고, 이후 둘중 하나라도 불만족되면 진입을 한다.
2번 알고리즘의 문제해결: 만일 flag가 동시에 올라온다 하더라도 turn은 반드시 하나의 값을 지니므로( i, j) 빨리 들어온 프로세스의 turn값이 입력될 것임. 먼저 수행할 수 있음. 빨리온애가 먼저 하게 되있음.
3가지 조건 모두 만족시킴.

Hardware Atomic Solutions
소프트웨어 솔루션만으로는 한계가 존재, 아키텍처적인 해결책을 만들자

철저하게 mutual exclusion을 instruction level에서 제공하자. 특수한 명령어를 만들어 동기화문제를 해결해보자. 현대의 모든 아키텍쳐에는 이런 mutual exclusion을 볼 수 있는 명령어(instructions set)(test-and-set, swap, xchg) 등이 있음. 이런 명령어를 제공하면 mutual exclusion을 수행함. 다른 조건들,(fairness, progress)등은 만족되지 않음
mutual exculusion을 하드웨어적으로 효율적으로 수행해 보자
예시

위 Test-and-Set은 instruction set level에서 하나의 cpu에서 atomic하게 수행된다. target이라는 변수를 read operation한 후에 target에 True라는 값을 쓴다. 이 두 과정 사이에 어떠한 다른 프로세스도 target 영역에 대한 연산을 수행할 수 없다. 그냥 그렇게 되도록 만든 하드웨어적인 instruction 이다.
실제 프로세스에서 test-and-set을 어떻게 사용하는지 보자.
lock이라는 변수를 처음에 false 으로 둠. 맨 처음 들어온 프로세스 관점에서는 entry section의 while loop의 조건문에서, Test and set 의 첫줄 (Test-and-Set:= target), 즉 read operation으로 false 값을 리턴하게되므로 while문을 스킵하게 된다. 이후 test and set의 둘째 줄에 의해 lock 변수는 True로 설정된다. 그리고 프로세스는 크리티컬 섹션을 사용하게 된다. 이 두 연산은 하드웨어적으로 반드시 atomic하게 수행된다.
다음에 도착하게되는 프로세스들, 똑같이 while문의 조건식인 test-and-set을 수행한다. 이번에는 앞선 크리티컬 섹션을 사용하는 프로세스(위 과정)에 의해 설정된 lock 값인 True를 읽고 계속 다시 True라고 쓰게 된다. 따라서 무한루프에 빠지게 된다. 앞선 크리티컬 섹션 사용 프로세스가 모두 사용 후 lock을 다시 false로 돌려놓은다. 그러면 가장 먼저 while 조건식인 test-and set 함수를 수행하게 되는 프로세스는 lock 값을 false로 읽고 크리티컬 섹션에 진입하게 된다.
mutual exclusin문제는 해결된다.
하지만 starvation문제는 여전히 존재. 뒤에 대기하는 프로세스들 중 운좋게 lock 값이 True로 전환되는 순간 조루프 조건식인 Test-and-set 함수가 수행하는 프로세스가 크리티컬 섹션을 사용하게 되기 때문에 재수가 없다면 어떤 프로세스는 계속 무한히 대기할 수도 있다.

swap 명령어. intel 아키텍쳐에서 제공하는 atomic 해결책이다. 논리적으로 위와 같음. 두 파라미터의 변수 값을 바꾸는 과정을 atomic하게 수행되는 것을 하드웨어적으로 보장한다.
spinlock의 문제

spinlock은 위의 하드웨어적, 혹은 소프트웨어적 해결책만을 사용한 해결방법을 지칭한다. 루프를 통해 스핀처럼 뱅글뱅글 돌면서 access를 기다리게하고 다음 진입을 하게하는, 그런 로직이라 spin이라 부름.
이런 spinlock 해결법은 resource waste의 문제가 존재한다. 다른 것을 수행하지 못하고, 계속 스핀락 상황에서 critical section 을 위한 entry 조건 체크만 하기 때문이다.특히, critical section을 어떤 프로세스가 오래 사용한다면 spin하는 시간이 늘어날 것이며 성능 측면에서 전체적인 낭비가 발생한다. 만일 locking하는 프로세스가 interrupt를 받게 된다면 더 큰 문제임.
Spin Lock 은 이름이 뜻하는대로, 만약 다른 스레드가 lock을 소유하고 있다면 그 lock이 반환될 때까지 계속 확인하며 기다리는 것이다. ”조금만 기다리면 바로 쓸 수 있는데 굳이 컨텍스트 스위칭으로 부하를 줄 필요가 있나?” 라는 컨셉으로 개발된 것으로 크리티컬 섹션에 진입이 불가능할때 컨텍스트 스위칭을 하지 않고 잠시 루프를 돌면서 재시도 하는 것을 말한다. Lock-Unlcok 과정이 아주 짧아서 락하는 경우가 드문 경우(즉; 적절하게 크리티컬 섹션을 사용한 경우) 유용하다. Spin Lock 은 다음과 같은 특성을 갖는다.
- Lock을 얻을 수 없다면, 계속해서 Lock을 확인하며 얻을 때까지 기다린다. 이른바 바쁘게 기다리는 busy wating이다.
- 바쁘게 기다린다는 것은 무한 루프를 돌면서 최대한 다른 스레드에게 CPU를 양보하지 않는 것이다.
- Lock이 곧 사용가능해질 경우 컨택스트 스위치를 줄여 CPU의 부담을 덜어준다. 하지만, 만약 어떤 스레드가 Lock을 오랫동안 유지한다면 오히려 CPU 시간을 많이 소모할 가능성이 있다.
- 하나의 CPU나 하나의 코어만 있는 경우에는 유용하지 않다. 그 이유는 만약 다른 스레드가 Lock을 가지고 있고 그 스레드가 Lock을 풀어 주려면 싱글 CPU 시스템에서는 어차피 컨택스트 스위치가 일어나야 하기 때문이다. 주의할 점 스핀락을 잘못 사용하면 CPU 사용률 100%를 만드는 상황이 발생하므로 주의 해야 한다. 스핀락은 기본적으로 무한 for 루프를 돌면서 lock을 기다리므로 하나의 쓰레드가 lock을 오랫동안 가지고 있다면, 다른 blocking된 쓰레드는 busy waiting을 하므로 CPU를 쓸데없이 낭비하게 된다.
장점은 스핀락을 잘 사용하면 context switch를 줄여 효율을 높일 수 있다. 무한 루프를 돌기 보다는 일정 시간 lock을 얻을 수 없다면 잠시 sleep하는 back off 알고리즘을 사용하는 것이 훨씬 좋다.
(https://brownbears.tistory.com/45)
따라서 이러한 spin lock은 고급 기능을 제공하기 위한 primitive로만 쓰인다. 상위 레벨의 메커니즘을 위한 mutual exclusion을 수행하는 가장 low level의 기능 단위로 쓰임.
System-level Solution : Disabling Interrupt
System Level의 해결책.

결국 커널 레벨에서 동기화문제의 근본은 생각해보면 interrupt에서 발생함.,
ex)시스템 콜 핸들러가 커널모드에 돌아가서 시스템 콜을 처리하는 와중에 IO interrupt가 발생. 시스템 핸들러가 처리하던 자료구조를 IO 핸들러가 접근 및 수정.
커널이 크리티컬 섹션을 수행하는 시점에 interrupt를 막아버림. 다 쓰면 interrupt를 열어줌. Interrupt를 막아버리면 쭉 쓸 수 있는 것임. 강력한 기능
단점:
커널 안쪽에서만 쓰임. 중요한 interrupt를 놓칠수도 있으므로 시스템 효율성을 떨어뜨림. 병렬 cpu환경에서는 interrupt를 막는다 하더라도 mutual exculsion이 안되는 상황이 있음.
이것 역시 이러한 단점들 떄문에 spinlock 과 함께 higher level solution의 기본 primitive로 사용함. 독자적으로 모든 책임을 지우는 사용보다는, 적절히 다른 수단들과 조합해서 단점을 보완하여 사용함.
High level synchronization

primitive 단독으로 쓰이면 단점들이 존재 커널의 성능, 효율성 하락문제, 즉 resource를 낭비하게 된다.
운영체제나 컴파일러 체제에서 지원하면 어떨까 atomic lock들이나 primitive들을 적절히 조합한 활용으로 구현
효용성도 maximize하면서 기능도 제대로 수행하게! 그것들 중 하나가 바로 세마포다
Semaphore
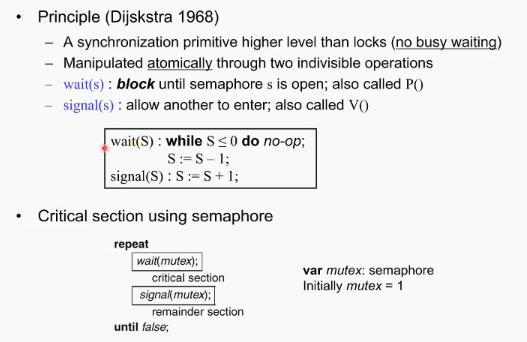
다익스트라가 제안한 기법. milestone급의 제안.
Lock이 필요한 것은 확실하다. 하지만 low level에서 locking하고 spin하는 방법자체가 문제이며 커널 안쪽에서 사용하기에는 효용이 떨어지는 한계가 있다. busy wating하지 않은 lock 개념인 semaphore 기법을 제안.
어떤 변수를 두고 (semaphore라고 불린다), 두개의 operator을 제공(wait, signal) 위의 소프트웨어 알고리즘이랑 다른 점은 blocking이 가능하다는 점이다.
wait 함수(semaphore): semaphore 값이 0보다 크다면 access 가능, 0과 같거나 작으면 acess안하고 대기 즉 lock. wait 콜을 부르는 프로세스가 일종의 공유변수인 세마포가 0보다 작다면 아예 자신의 프로세스 state를 blocking state로 바꾸어 버린다.
signal 함수(semaphore): 크리티컬 섹션을 다 쓰고나서 blocking state에 있는 대기중 프로세스들 중 하나를 불러오는 콜임.
크리티컬 섹션의 동기화 이슈를 프로세스 스케줄링과 연관지어버린 유용한 기법. 이전의 방법들은 spin lock, 즉 바쁘게 while문을 실행하면서 대기했으므로 cpu resource를 많이 잡아먹었었다. 하지만, semaphore기법은 아예 프로세스 state을 blokc상태로 바꾸어 대기한다. 커널 안쪽에서 사용할 때 훨씬 리소스를 아낄 수 있기에 효율적이다.
세마포의 구현

가장 기본적인 구현방법.
semaphore 자료구조를 만든다. L이라는 리스트가 존재, 세마포에 엮여있는 프로세스/스레드들을 담고 있다.
또한 block 과 wakeup이라는 기능을 동반해서 사용된다.


문제: 세마포의 자료구조를 동시에 업데이트 하는 상황 발생(S.value 혹은 세마포 변수) 가능성
세마포 변수 값 자체가 공유된다. 다시 원점으로 producer consumer 문제가 생긴다.
세마포 변수를 다룰 때에도 concurrency control을 해야함. 이 상황, 이 부분에 대해서 앞서 설명한 low level primitive의 spin lock을 사용함. 하나의 작은 변수의 값만 이용하는 상황이기에 오버헤드가 크지 않다. 이 변수에 대해서만 low level primitive를 사용하게 되는 것이다. 이로써 atomicity guareentee가 된다.
하지만, 만일 cpu가 한개, 단일 프로세서 상황이라면 spin lock을 할 수 없다.(프로세서가 하나이기 때문에 ping pong이 이루어지지 않아서) interrupt를 막고 푸는 방법밖에 없음. (spin lock사용 불가)
반대로 interrupt를 막는 방법은 멀티프로세서 상황에서 이용이 불가하다.
하지만 멀티 프로세서는 하드웨어 lock, spin lock 같은 기초 primitive 사용 가능. 한군데가 쓰고 한군데는 spinlock으로 돌게 할 수 있음. 쓰고 있는 쪽이 풀면 spinlock하던 쪽이 잡아채는 방식임.
세마포의 종류 와 사용

Binary semaphore : 한번에 하나의 스레드/프로세스만 쓸 수 있는 것. counter값이 1 혹은 0 (뮤텍스라고도 불린다)
counting semaphore:
리소스가 여러개 있는 상황에서 (ex printer가 3 개인 상황에서 프린터 리소스에 대한 세마포) 쓰인다.여러개의 스레드/프로세스들이 동시에 사용 가능 resource가 많을때 사용. counter값이 N까지 가능.
세마포의 다양한 쓰임 - ordering of activities
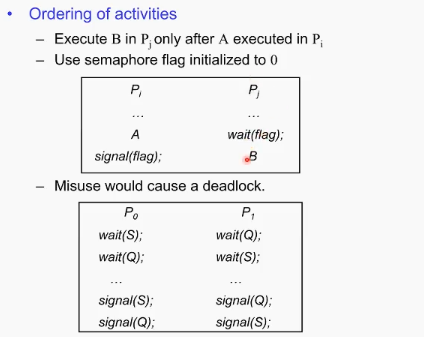
(Mutex란-> mutal exculsion의 준말)
쓰임: mutual exclusion 말고도 ordering에도 사용됨.
Pj 의 B 부분은 Pi의 A 부분보다 항상 뒤에 쓰이게 함. 위의 첫번째 그림에서 flag를 0으로 initialize하는 것임. Pi프로세스의 A 부분이 끝나야만 Pj의 B 부분이 시작할 수 있다.
원래 semaphore의 목적(mutual exclusion)과는 다르지만, 이렇게 프로세스간 작업 흐름을 조절할 때에도 용할 수 있다.
만일 잘못 쓰게 되면 두번 째 네모박스 그림에서처럼 deadlock을 발생시킴. P0와 P1이 영원히 서로 상대방을 기다림. ⇒세마포를 사용하는 프로그래머가 이런 상황이 일어나지 않게끔 정교하게 잘 고려, 설계해야한다.
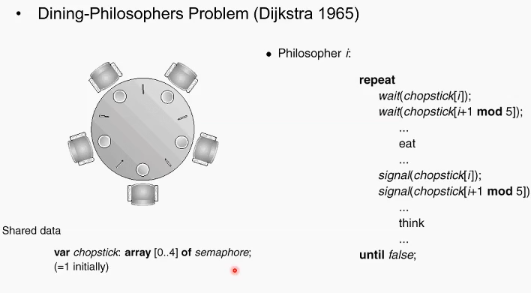
다익스트라의 문제: 원탁에 다섯명이 앉아있고 각각 음식이 있음. 다섯명 자리의 사이 사이에 젓가락이 하나씩만 있음. 다섯명이 식사를 할때 어떻게 젓가락(resource) 를 할당해야 starvation 없이 식사를 하겠는가? -> concurrency control의 문제.
한사람이 먹기 위해서는 반드시 왼쪽 오른쪽을 모두 가져야함.
오른쪽의 코드대로 하면 될 듯 하지만 안되는 상황이 있음. 만일 시작 하자말자 모든 사람이 왼쪽의 젓가락을 집는다면 영원히 wait만 하고 교착상태, 끝나지 않는 문제가 되어버릴 것임.

여러가지 해결책 존재: 홀수번재 먼저 집어들고 짝수번째 집게 하기, 최대 4명까지 젓가락 집게 하기, 양쪽에 젓가락이 모두 확보될 때에만 집어들게 하기 등등.
세마포의 한계, 단점
잘못쓰게 된다면 시스템이 crush 되어버림. bug의 근원!

mutual exclusion이 본래목적이기는 하다. 하지만 ordering이나 스케줄링에서도 사용할 수 있는 강력한 기능이다. 너무 강력한 기능이다보니 잘 못 사용하게 된다면 시스템 전체가 망가질 수 있다.
다른 개념들
Critical Region

개념만 이해해라. 현제는 거의 안쓰이는 개념. 어떤 철학이 있는지만 확인.
프로그래밍 언어에 region, shared라는 키워드, 개념, syntax등을 도입해서 concurrency control을 하자.
Monitor

마찬가지로 프로그래밍 언어의 구조로 제시하자.

모니터는 크게 공유 변수, 그리고 preocedure들로 이루어짐.
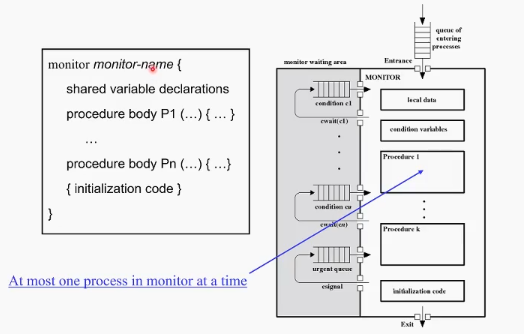
여러개의 procedure가 들어올 수 있지만 모니터 안에서는 한번에 오직 하나의 processs만 돌아갈 수 있음. procedure을 수행 하는 와중에도, 어떤 조건이 만족이 안되면(공유변수를 기다린다든가) waiting area의 대기 큐로 빼내서 대기. 실제 프로그래밍 언어로도 구현하여 syntax에 도입- 컴파일과정을 거쳐 runtime에 이를 구현.

오늘날에는 별로 안쓰임.


pthread

pthread 만의 독특한 동기화 기법들이 많이 있음.
mutex관련, Condition Variables, Semaphore 등 다양하다. 쓰레드를 잘 활용하려면 공유 변수들을 잘 사용해야한다. 그렇기에 이런 기능들을 지원.

mutex 정의, 컨디션 변수 not_full, not_empty 정의, resource 정의.
코드를 살펴보면 빨간색 빼고 모니터에서의 코드와 동일. 즉 mutex_lock, mutex_unlock이 모니터의 기능을 해준다고 보면 됨. 두개의 프로세스가 (스레드) 해당 코드들을 수행하더라도 검정색과 파란색 부분은 반드시 하나의 프로세스(스레드)가 수행하게 된다.
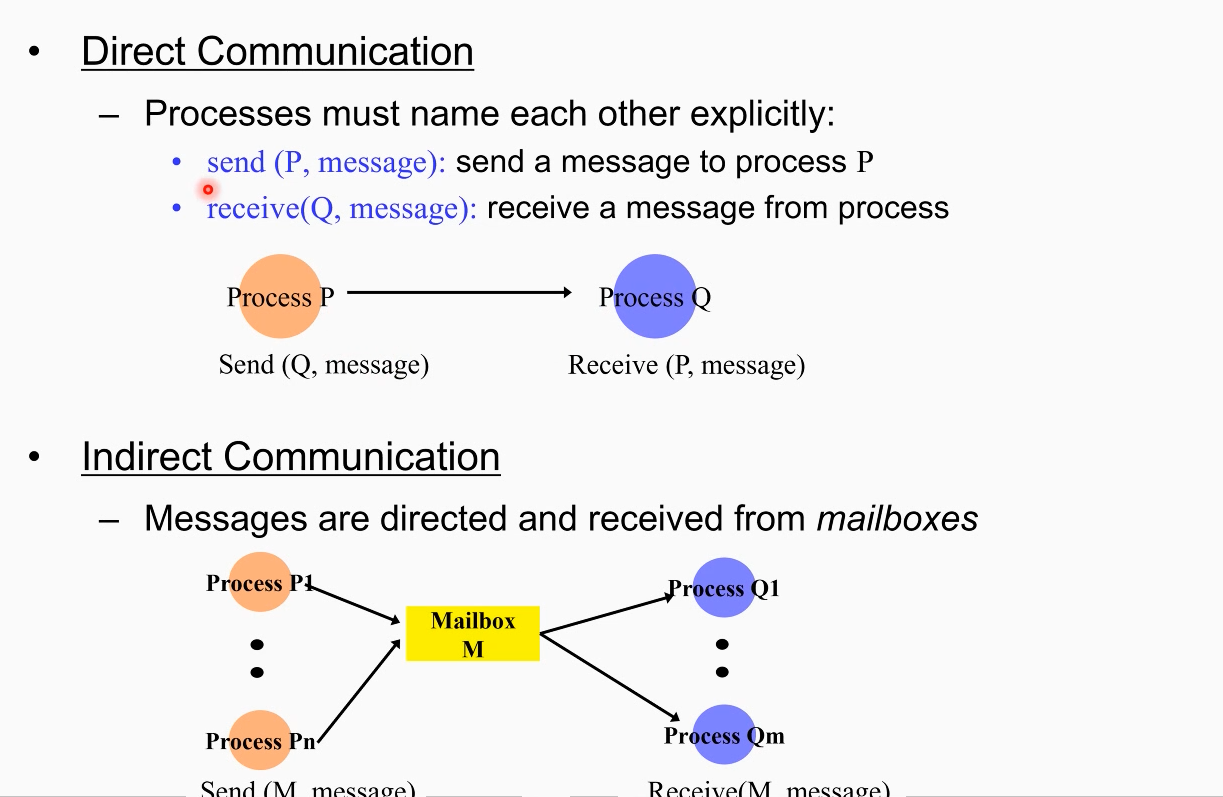
Message Passing

ipc 기법중 하나임
메시지를 전달함으로 센더와 리시버 간의 동기화를 함. (ex 소켓 통신: 대표적으로 메시지를 보내서 두 개의 프로세스가 동기화하는 방법이다.) 메세지를 주고 받은 시점이 두 프로세스가 동기화가 된 시점이고 이 메시지 패싱 자체도 primitve들 중 하나이다.
센드, 리시브를 어떻게 구현할 것인가 어떤 semantic을 줄 것인가?

send와 receive를 어떻게, 어떤 semantic을 주느냐에 따라 구현이 달라짐.
send와 receive 사이에 blocking 이슈가 존재. 만약 센더가 send를 했는데 receiver가 완벽히 받을 때까지 block을 하느냐. 혹은 만일 리시버가 receive를 열었는데 send가 아직 메세지를 안보냈다면, block 할 것이냐 아니면 체크만 하고 진행할 것이냐.
양쪽이 모두 메시지를 주고 받는 관점에서, block을 할 수 있고 혹은 non block 할수도, 혹은 한쪽만 block할 수도 있는, 구현 이슈가 있다. 정답은 없다.
일반적으로, send는 메시지를 보내고, block을 굳이 할 필요가 없다. reciever만 blocking으로 구현. 즉 보통은 send는 nonblock, reciever는 blocking으로 구현한다.(정답은 없음, 소켓통신에서는 이렇게 함.)
만일 양쪽으로 다 block 구현했다면 랑데뷰라고 한다.(full synchronization) 완벽히 양쪽이 일치해야만 진행
완전히 반대로 센더와 리시버를 asynchronous하게 구현할 수 도 있다. 즉, 센더가 보내고 나서 block을 하지 않고 진행하고, 리시버도 체크를 해서 없으면 그냥 진행하고 나중에 다시 주기적으로 받은게 있나 확인하고 이런식이다. (asunchronous programming model)
실제 운영체제에서 동기화

각 운영체제에서 제공하는 기능들 . 어떤 primitive를 사용할까?
대부분 운영체제가 멀티 프로세스, 멀티 스레딩 기능을 지원한다.
솔라리스는 운영체제 차원에서 아주 많은 형태의 동기화 기능을 지원한다. 리눅스는 pthread만 지원. 윈도우도 꽤 많음.
리눅스 커널의 동기화 기능

앞선 슬라이드들에서는 유저 관점에서 어떤 동기화 primitive를 사용하는지 살펴보았었다. 다음 내용들은 리눅스 커널 안쪽에서는 어떤 동기화 primitive를 활용해서 커널 코드가 동기화 이슈를 해결하는지 살펴보자.
많은 기능이 있지만 포인트는
단일 cpu상황일 지라도 커널 안쪽에서 돌아가는 커널 코드들 상에도 동기화 이슈가 있다 라는 것이다!
(+interrupt handler, systemcall handler가 interleaving되서 돌아가기 때문)
때문에 커널의 자료구조를 적절하게 동기화 이슈로부터 보호해야한다. race condition을 피하고 공유데이터가 concurrent하게 활용되는 상황을 막아야한다.
자세히 보다는 그냥 알아보는 느낌. 축약하여 정리.

크게 세가지 카테고리의 컨셉이 있다.
-
Atomic operations
atomic로 시작하는 커널 함수가 있음. atomic 이것들은 실제 실행이 atomic하게 된다. 간단한 operation을 cpu 수와 상관없이 반드시 atomic하게(깨지지 않게) 수행하는 용도임. 컴파일러가 이러한 코드를 isa로 바꾸는 과정에서 인텔같은 경우는 instruction 앞에 lock byte라는 prefix를 붙임. load, store 등의 명령어를 수행하는 와중에 다른 cpu에게 해당 operation과 관련된 데이터 흐름이 없도록 버스를 통제함(bus freeze). 다른 cpu가 해당 operation이 끝날때까지 못쓰게 함.
-
Interrupt disabling
중요한 커널 코드와, 커널 자료구조를 access하는 도중에 interrupt 기능을 잠시 멈춰버리는 기법.
하드웨어적으로 interrupt를 막거나 푸는 강력한 방법이다. cli() 나 sti()를 씀.
단일 cpu 상황에서 쓸 수 있는 유일한 동기화 기법. (단일 cpu에서 spin lockr과 같은 동기화 기법은 한계가 있다.)
-
Locking
spinlock(), semaphore 등이 있음. multiple cpu system에서만 사용함.
단일 프로세스에서 쓸 수 는 있으나 고려할 점들이 있음. 예를 들어 사용자 프로세스가 가동 중, 커널 안에서 인터럽트 핸들러가 동작하는 상황이 발생해서 커널모드로 바꾼 상황을 생각해보자 . 이때 인터럽트 핸들러가 커널 안쪽에서 공유 데이터 접근을 위해 세마포를 사용하고 있다고 하자. 핸들러가 공유 데이터를 위해 세마포 값을 읽어온다. 읽은 순간 보니, 다른 커널 스레드가 해당 공유 데이터를 사용하고 있다면, 현재 돌고 있는 인터럽트 핸들러를 포함한 유저 프로세스를 block상태로 바꿔버리게 된다. 즉 스케줄링에서 배제되어 무작정 기다리게 되는 것이다. 유저 입장에서는 예상치 못하게 blocking을 당하므로 상당히 불쾌할 것이다.
++ 디버깅이 가장 어려운 상황이 바로 동기화 이슈이다. 프로그래머 입장에서 에러가 발생하면 제현이 되어야한다. 즉 다시 돌렸을때 같은 상황, 같은 곳에서 에러가 나야지 고치기가 수월한데 동기화 이슈는 언제 어디서 어떻게 터지는지 알 수 없고 매우 다양하게 발생. 그래서 디버깅이 어려움.
모든 커널은 반드시 멀티 프로세서를 고려해야하고 커널의 많은 기법들이 이러한 동기화들 기법을 적절히 활용해 효율성 있게 동기화를 해 줘야한다.
댓글남기기