L7-Deadlock
연세대학교 차호정 교수님의 운영체제 강의를 듣고 작성한 강의록
프로세서 이슈 중 마지막 이슈. 데드락이라는 교착상태에 대하여. 이 역시 멀티 프로세서가 있는 시스템에서 발생할 수 있는 상황 중 하나이다. 시스템이 살아있는데 프로세서가 진행이 안되는 상황임. 멀티 프로세스나, 네트워크 등에서 이런 데드락을 피하기 위한 고민을 하고 많은 연구가 진행되는 분야임. 데드락을 막기 위한 관련 알고리즘을 시스템에 넣어주어 해결함.
The Deadlock Problem

데드락 문제의 핵심 원인: 리소스는 제한되어있는데 리소스를 원하는 프로세서가 많을 때 발생.
위의 예시.P1과 P2 프로세스가 있고 두개의 io장치가 있다고 가정. P1과 P2가 각각 io 디바이스를 하나씩 쓰고, 서로의 것을 필요로 하는 상황.
- 세마포를 잘 못 쓰는 경우에도 발생할 수 있다.
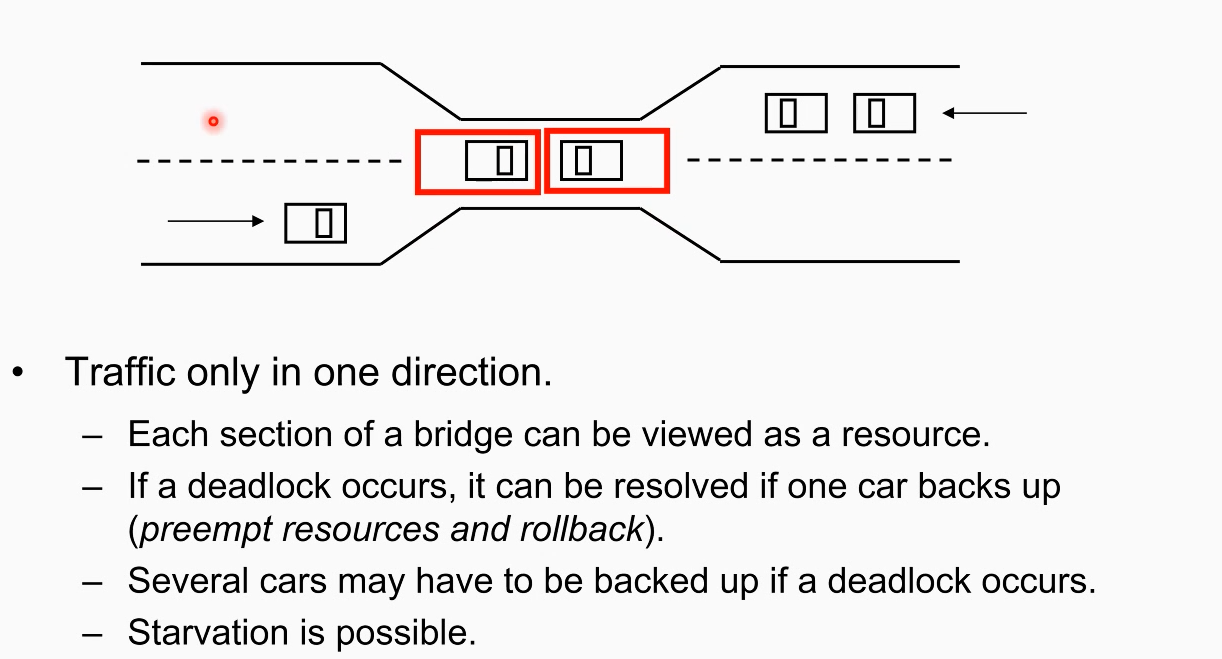
현실적인 비유, 위 그림의 도로상황 같은 경우.
Formal Model of Deadlock

데드락을 formal하게 표현해 보면 시스템에는 두가지 집합이 있음. 프로세스의 집합과 리소스의 집합.
위의 그림은 프로세스 관점에서 request and release모델임. 특정 리소스에 대해 request를 하고, 가능하면 리소스를 할당 받고 다 쓰고 난 후에는 반납(release) 하는 sequence다.
Resource Allocation Graph
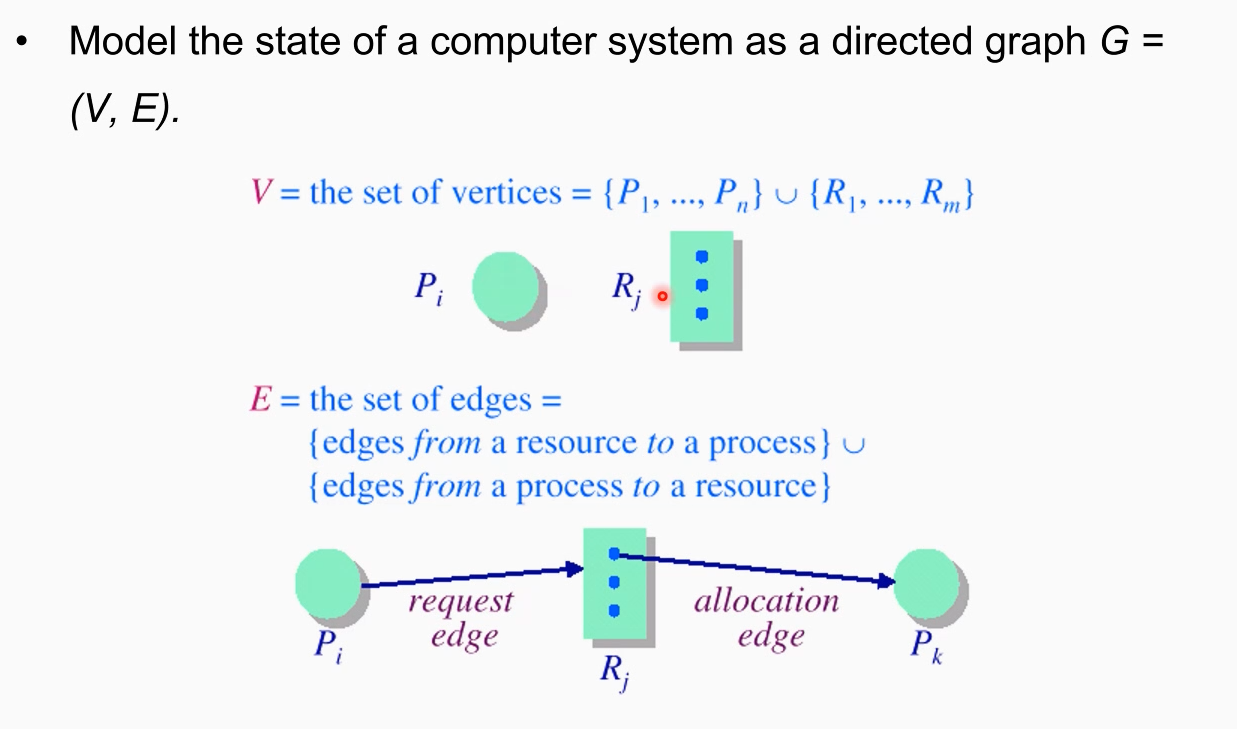
이러한 상황을 시스템 관점에서 간단한 수학적 이론으로, 그래프 이론으로 표현 가능한데 이를 Resource Allocation Graph 라고 한다.
운영체제 리소스 할당의 관점에서 표현된 그래프를 해석을 할 경우 노드 타입에 두 가지가 존재한다이.위의 예제에서 동그라미 노드는 프로세스, 박스 노드는 리소스를 의미함. 리소스 노드에는 안에 파란 점들이 있는데 이건 리소스의 개수임(프린터의 개수 등등)
노드를 연결하는 엣지도 두가지 타입이 있음. process에서 시작해서 resource로 들어가는 request edge와 resource에서 시작해서 process로 가는 allocation edge .시스템의 프로세스와 리소스의 annotation과 같은 위 그래프를 resource allocation graph라고 한다.
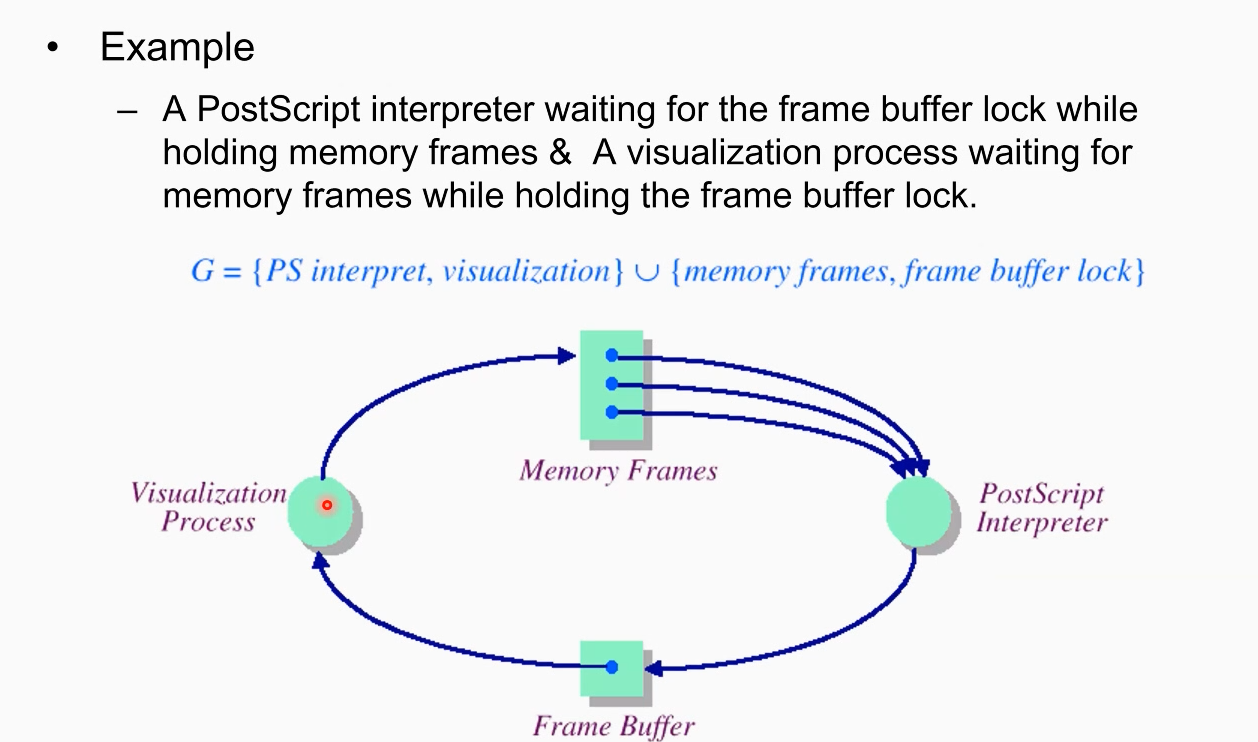
위의 resource allocation graph의 상황을 살펴보자. visualization process는 frame resource를 하나 붙잡고 있으며 추가로 memory resource을 요청(request) 하고 있다. 반면에 PostScript Interpreter는 Memory Frame을 모두 붙잡고(allocate) 있으며 추가로 visualization process가 할당하고 있는 Frame Buffer을 요청하고 있다.
이 상황이 바로 deadlock이다. 두개의 process가 서로 resource를 요청하고 있는 꼬리를 물고 있는 사이클의 형태. 이런 형태를 풀어내는 솔루션이 필요하다.
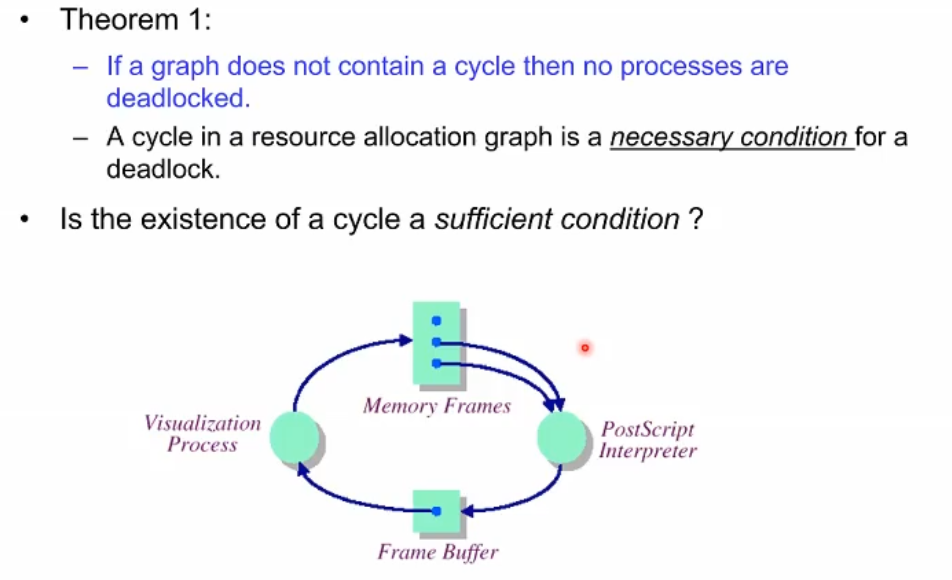
가장 직관적으로 데드락은 사이클이 존재할 때 발생. RAG가 사이클 형태가 아니라면 데드락이 발생하지 않을 것. 따라서 역으로 source allocation graph가 사이클을 포함하는 것이 데드락의 필요조건이 되는 것이다.
그렇다면 사이클만 있으면 무조건 데드락이 되느냐(충분조건이냐?) 그거는 아니다. 위의 그림처럼 사이클인 형태임에도 남는 resource가 존재한다면 충분히 데드락을 피할 수 있다. 사이클은 데드락의 필요조건 중 하나이다.
만약에 리소스의 개수를 제한을 해서 모든 resource가 한 개 뿐이라면 사이클은 데드락의 필충 조건이 되는 것이다.
데드락 발생의 조건들과 해결책의 타입
데드락이 발생하기 위해서 반드시 만족해야하는 조건. 데드락의 발생은 위 네가지 조건을 동시에 만족하면 일어날 수 있다. (네가지 조건은 필요조건이다)

- mutual exclusion: 어떤 resource가 mutually exclusive하게 쓰여야 한다 (한 프로세스만 한 리소스 자원을 사용가능)로 쓰여야만 한다.(mutual exclusion이 필요하지 않다면 데드락은 아예 발생안함.)
- Hold and wait: 어떤 프로세스가 리소스 몇개를 가지고 있고, 이를 진행하기 위해 additional한 리소스를 요청하고 있는 상태가 존재해야한다.
- No preemption: 어떤 프로세스가 리소스를 쓰고 있을때 강제로 뺏을 수 없어야한다.(ex printer 같은 경우.)
-
Circular wait: RAG가 꼬리를 무는 형태로 사이클로 존재한다. 사실은 4번 조건이 2번조건을 포함하고 있다. (솔루션을 위해 저자가 이 조건을 추가로 억지로? 넣음.)
사이클은 충분 조건이 아니다. 필요조건일 뿐. 왜 그럴까 생각해 보기. -> 사이클의 형태더라도 어떤 타입의 리소스가 사용가능한 여러개가 존재한다면 deadlock x

데드락 이슈는 다양한 곳에 존재한다. 네트워크, 병렬 프로세싱 상황 등등
여러가지 솔루션들
- deadlock prevention and Avoidance 시스템이 데드락을 아예 발생하지 않게 애초에 prevention을 하는 솔루션, 가능은 하겠지만 이를 위해 감수해야하는 overhead가 매우 크다.
- Deadlock Detection and Recovery 데드락이 발생하게 내버려 둔다. 문제가 발생하면 데드락 detection 알고리즘을 통해 진단을 하고 데드락이라면 recovery를 한다. 특정 프로세스를 죽일 수 있고 state를 roll back할 수 있고 등등. 첫번쨰 것보다 관대하지만 여전히 overhead가 존재.
- 아무것도 않하기 시스템이 freezing이 된다, 혹은 데드락이 발생한다 라면 specific한 해결 알고리즘을 넣지 않음. 그냥 재부팅해버림. 우리가 쓰는 윈도우 유닉스 계열, gp os(general purpose os)가 이에 해당함. 고려하지 않아버림.
DeadLock Prevention

아주 강력한 해결책. 데드락이 절대 발생하지 않게끔 설계하기.
앞서 말했던 네 가지 데드락이 발생하기 위한 필요조건들이 절대 동시에만 일어나지 않게끔만 해주는 방법이다.
- Mutual Exclusion: resource specific한 feature임. ex printer라는 리소스는 태생적으로 한 프로세스만 쓸 수 있는 특성을 지님. 즉 리소스한정 특징이기때문에 이를 해결할 방법은 딱히 존재하지 않음.
-
Hold and wait: 어떤 프로세스가 기존의 다른 타입의 리소스를 잡고 있으면서 동시에 또다른 타입의 리소스를 request하고 있는 상황의 문제이다 No Wait
어떤 프로세스가 필요한 resource가 현재 다 사용 가능할때만 request를 허용함.(ex 어떤 프로세스가 resource 4개가 필요한데 만일 현재 가능한 resource가 3개 뿐이라면 아예 request를 하지 않아버림)
No hold 어떤 프로세스가 다른 리소스를 원할 때, 해당 프로세스가 사용하고있는(hold하는) 리소스가 없을때만 허용한다-> 프로세스가 다른 리소스를 request할때 절대로 기존의 resource를 hold하지 않게 해야함.
강력한 방법이긴 하나 놀게되는 resource가 많아지거나 starvation이 발생할 수 있음. 시스템의 활용도가 떨어지거나 특정 프로세스는 활성화가 절대 안되는 경우 발생.

-
No preemeption
어떤 프로세스가 리소스를 잡고 있고 추가로 리소스를 원할 때(wait), 만일 시스템에 추가 리소스의 여분이 존재하지 않는다면 지금까지 hold했던 resource들과 작업들을 다 놓아버리고 이전 상태로 돌아가게 함.->preemption 오직 특정 타입의 리소스들에만 적용됨. 이전 상태로 돌리기가 용이하거나 state를 저장할 수 있는 resource들에 대해서만 적용 가능(cpu register, memory등등) No preemption의 조건을 깨는 형태.
위 세개는 이론적으로는 가능하나 현실적으로 구현하기는 어려움이 있다.
-
Circular wait
현실적으로 가장 가능성 있는 방법
아예 circular wait한 상황을 발생시키지 않는 방법. Total ordering을 함. resource type을 acces하는 순서를 정한다. 예를들어, 리소스 타입이 A,B,C가 있다면 모든 프로세스는 반드시 A, B,C 순서로만 resource 를 access해야함. 즉 프로세스가 resource를 access하는 순서를 제한하는 것임. ordering을 부여하는 이 개념이 가장 널리 알려진 방법이며 확실하고 현실적인 방법이다.
예를 들어 리눅스에서, 세마포를 사용할 때, circular wait 을 구현한다. 여러 세마포를 쓰는 경우, 메모리상에 address가 낮은 것 부터 세마포를 access할 수 있도록 강제하는 방식이 있다.
Deadlock Avoidance

프로세스들의 state들을 checking하고 프로세스들의 resource allocation을 지속적으로 관찰하고 분헉한다.시스템이 resource allocation을 하기 전에 몇수 앞을 내다본다 resource allocation에 따른 데드락 문제가 발생할 것이라는것이 분석을 통해 예상된다면 조치를 취하고 아니라면 진행하는 식.
하지만, OS가 하느님도 아니고 완벽히 예측하기는 힘들다. 이게 가능하려면 process들이 runtime동안 어떤 type의 resource를 몇 개를 쓸 것인지 os에게 미리 제시해야한다. 커널이 각 프로세스들의 보고를 받은 후 global table을 짜고 이를 전제해 reource할당을 처리하는 것이다. 현실적으로 제약이 많기에 구현이 어렵다.
general purpose os에서는 현실적으로 안쓰이지만, realtime system이나 mission cirtical 한 상황에 쓰이는 시스템에서는 이러한 형태의 avoidance 조건을 사용한다.
어떤 방식으로 avoidance 해낼 수 있을까?
Safe State

Safe state라는게 존재.
Safe state란 현재 각 프로세스들이 점유하고 있는 리소스들과, 시스템에 할당이 가능한 남아있는 리소스들을 모니터링해서, 현재 실행중인 프로세스들이 모두 데드락 없이 리소스 할당을 받아 실행할 수 있는 순서가 존재하는 상태이다.

safe한 상태이면 데드락을 반드시 피한다. unsafe한 상태이면 데드락을 피할 수도 있고 못 피할 수도 있다. 다시말해 unsafe의 경우 최악이 데드락이다.
Baknker`s algorithm

다익스트라 할아버지의 Bankers algoritm. deadlock avoidance를 위한 알고리즘이다. 프로세스가 resource request를 할 떄마다, resource allocation state가 safe한지 판별한다. 만일 safe하다면 주고 그렇지 못하다면 원래대로 돌아가서 기다리는 것이다. 이 알고리즘의 전제조건은 모든 프로세스가 사전에 시스템에게 자신이 필요로 하는 모든 리소스들을 알려줘야한다.

용어 설명.
- available: resource type에 있는 실제 리소스의 개수
- Max: n x m 매트릭스 n은 프로세스 m은 리소스 . i번 프로세스가 j번 리소스를 최대 몇개 필요로 하는지 저장함.
- allocation: n x m 매트릭스, 현재 순간에 i번 프로세스가 j번 리소스를 몇개 가지고 있느냐라는 매트릭스
- need: n x m 매트릭스로 max매트릭스에서 allocation 매트릭스를 뺀 매트릭스이다..


m = number of resource types n = number of processes
예제
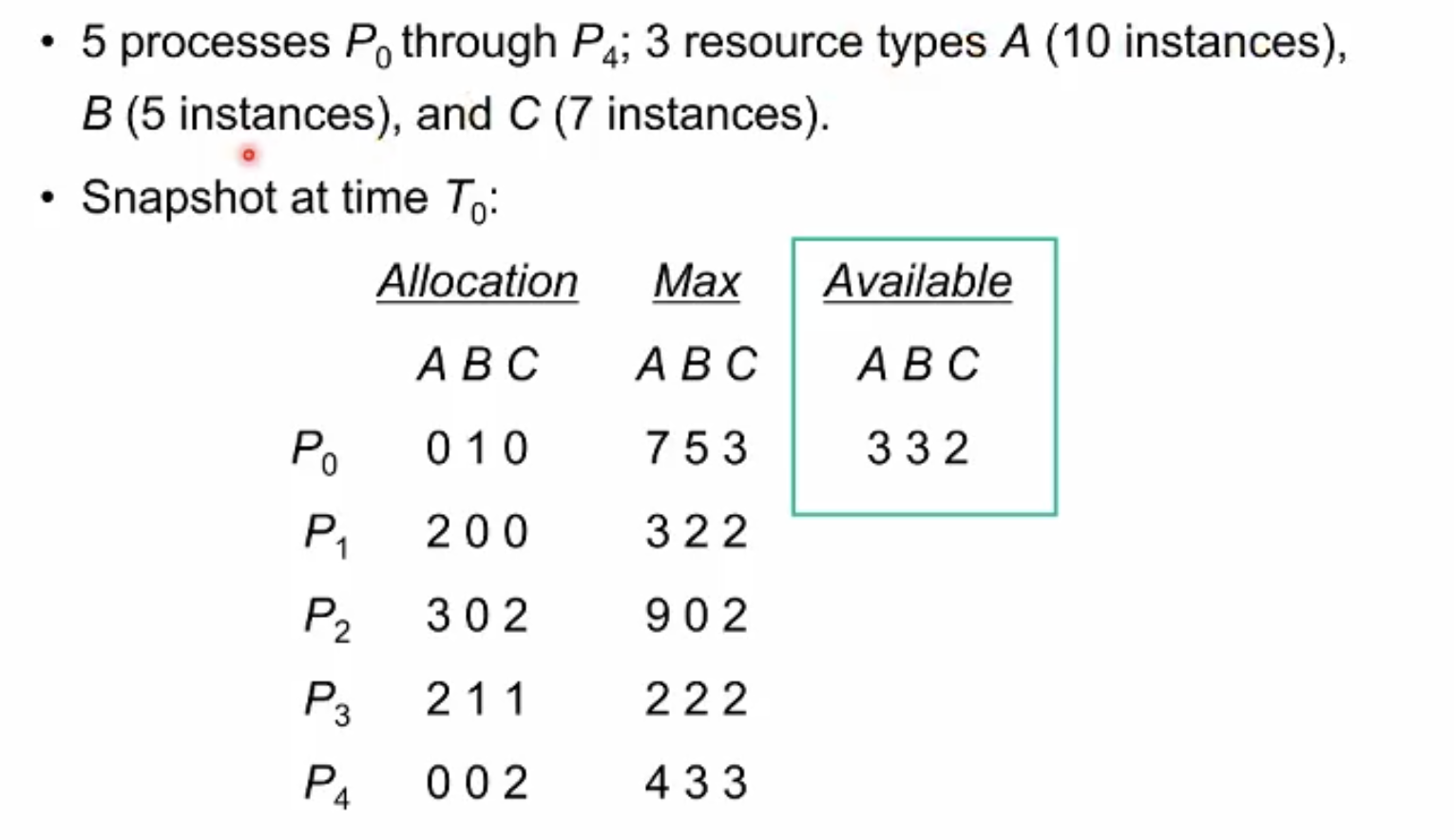
시스템에 5개의 프로세스가 존재, 3개의 resource type이 잇으며 각 resource type a, b, c는 10개, 5개,7개가 있는 상황이다.
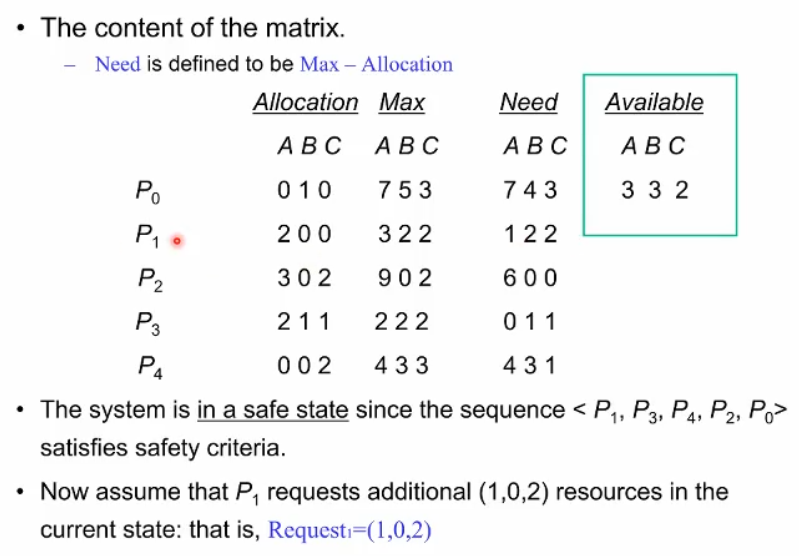
현재 상황이 safe한지 아닌지 커널이 판단함. 모든 다섯개 프로세스가 끝날 수 있는 순서가 있다고 하면 이 상태는 safe하다고 시스템이 판단함. 위 예시에서는 P1,P3,P4,P2,P0 의 순서로 모두 끝낼 수 있음.
이 상황에서 P1이 현재 상태에서 추가로 리소스(1, 0, 2 ) 를 커널에게 추가적으로 요청함

당연하게도, 요청보다 available이 더 많아야한다. 이후 요청(1,0,2)를 P1에게 할당하고 나면 그 이후에도 safe한 state가 유지되는지 커널이 시뮬레이션을 함. 존재하면 리소스 요청에 대한 할당을 진행하고 존재하지 않으면 리소스 요청을 기각한다.
Deadlock Detection

prevention과 avoidance는 atomic하게 deadlock을 막는다. 즉 unsafe state진입 자체를 금지한다.
detection and recovery는 반면 deadlock 이 발생하게 끔 놔 두고, 발생하면 이를 감지하고 처리한다. 앞선 방법들에 비해 더 현실적인 방법들이다.
앞서 살펴봤듯이, 데드락은 unsafe state에 들어가도 발생 안할수도 있다.
unsafe state에 들어서는 것 자체는 허용하되, 만일 최악의 경우 데드락이 발생하면 감지 후 recovery를 하겠다는 취지임.
예제

프로세스가 사전에 커널에게 정보를 주는게 아니라 그냥 리소스를 필요한대로 가져다가 사용함. 위의 예제 상황에서 남은 리소스는 아무것도 없는 상태이지만 각각의 프로세스가 또 리소스를 request중에 있다. 그럼에도 safe한 sequence가 존재함(0,2,3,1,4)

하지만 만약에 앞선 상황과 같은데 p2가 001을 원한다고 가정하자. P0가 끝나도 P2의 request에 해당하는 resource를 할당할 수 없다. 이렇게 운이 안좋은 상황에 데드락에 걸릴 수 있음. 이러한 상황에서는 일전의 safety algorithm으로 데드락임을 디텍션을 하고, P0만 일단 실행을 하고 나머지 P1~P4에 대해서 조치를 취해줘야함(Recovery)

safety algorithm의 need를 request로 바꿔주면 그게 detection algorithm임.

os가 데드락이 걸렸는지 안걸렸는지 언제 detection algorithm을 돌려서 판단하나? 어떻게 언제, 얼마나 자주 detection 알고리즘을 수행하는가가 구현상의 이슈이다. 너무 많이 하면 overhead가 부담되니까 적절하게 잘 detect하는 만큼만 detection algorithm을 실행해야할 것이다.
Recovery from Deadlock

만일 디텍션을 통해 데드락의 발생을 알았다면 이를 위한 적절한 조치가 필요하다.(recovery)
process termination : 프로세스를 죽여버리는 것. 이때 어떤 것을 terminate하는지 또 이슈이다. 우선순위가 낮은 거를 먼저 죽이는가? remaing time이 많이 남은 것을 먼저 죽이나? 많은 리소스를 이미 holding하고 있는 것? 판단을 잘 해야지 waste를 줄여나갈 수 있음.

프로세스를 죽이는 것이 아니라 바로 전단계 혹은 이전단계들로 롤 백을 하는 것이다. 롤 백을 해서 이전상태로 되돌렸을때 resource를 반환하게 되고, 이때 deadlock이 해결된다면 ok . 누구를 롤백시킬지, starvation 등의 이슈가 있다.
댓글남기기