L8-Memory Management
Memory Management
메인 메모리 관리에 대한 이슈. 프로세스가 상주하는 공간은 RAM(random access memory), 주기억 장치인데 이 장치를 관리하는게 주요 이슈이다. 먼저 이 장에서는 기본적인 primitive한 개념의 메모리 이야기를 다룸.

Protection: 우리가 쓰는 os는 멀티 프로그래밍(프로세싱) 체제이다. 문제는 하나의 물리적인 메모리 공간에 여러개의 프로세스를 담아야 하는 것이다. 특정 프로세스가 수행하는 와중에 다른 프로세스의 주소공간을 참조하면 절대 안된다. 즉 프로세스간에 구분, protection이 필요하다.
MMU: memory management unit이라는 하드웨어가 있다. 이런 하드웨어가 동작해야하는데 멀티 프로세싱을 위해 protection과 주소공간의 변경이 아주 빨리 이루어져야한다.
메모리 관리라는 것은 결국 os와 하드웨어가 함께 하는 것이고 같이 움직여야한다. 메모리 관리에 대한 fundemental한 수단은 architecture 기반에서 제공하고 os는 이를 잘 활용해서 메모리 관리를 수행한다.
목표:
1 프로세스간 isolation 구현 2 메모리 자원을 여러 개의 프로세스에 효율적으로 제공하고 관리하기.

이슈들
- 하나의 프로세스는 연속된 logical adress가 제공되어야한다. 하지만 프로세스마다 요구하는 메모리 공간이 다를 수 있다.
- 쓸 수 있는 physical 메모리 양보다 프로세스들에서 요구되는 메모리 양이 더 큰 경우가 존재.
- protection(철저히 주소공간이 보호되어야함)과 공유의 문제 ( 어떤 주소공간은 같은 프로세스 내에서, 어떤 주소공간은 두개 이상의 프로세스가 공유할 수 있음)
- 성능도 보장해야함.
-
프로세스 내부에 여러가지 공간(segments) 이 존재(ex. code, heap stack…). 이 segment들 특성에 따라 관리를 다르게 해줘야함. access write, protection등
(Segement의 조합으로 프로세스가 구성되는데 각 세그먼트의 종류에 따라 다른 특징을 지님)
Address Spaces

물리 주소공간과 논리 주소공간.
물리 주소공간: 0 ~ MAXsys 까지 실제 하드웨어직인 공간
논리 주소공간: 프로세스가 소유한 메모리 공간. 0~MAXprog까지의 공간.
💡질문) CPU가 프로그램 카운터, stack pointer, 등을 계속 update하면서 사용하는데 program counter가 가지고 있는 주소가 물리주소인가 논리주소인가? -> 논리 주소.
word size 32bit, 64bit다 라는 얘기는 결국 프로그램 카운터가 담을수 있는, 식별할 수 있는 메모리의 크기를 의미한다.(32bit면 4기가, 64면 8기가) 즉, 모든 프로세스가 2의 32승만큼의 logical memory address를 지닌다는 뜻임. 프로그램 카운터, 스택 포인터는 이 4기가 내에 한곳을 가리키는 것이다.
CPU가 만들어내는 모든 주소는 logical address이다. physical 램 메모리 사이즈가 몇 기가바이트인지 상관 없이 모든 프로세스는 각각 word size만큼의 논리적 주소를 지니고 있다.
Address Generation
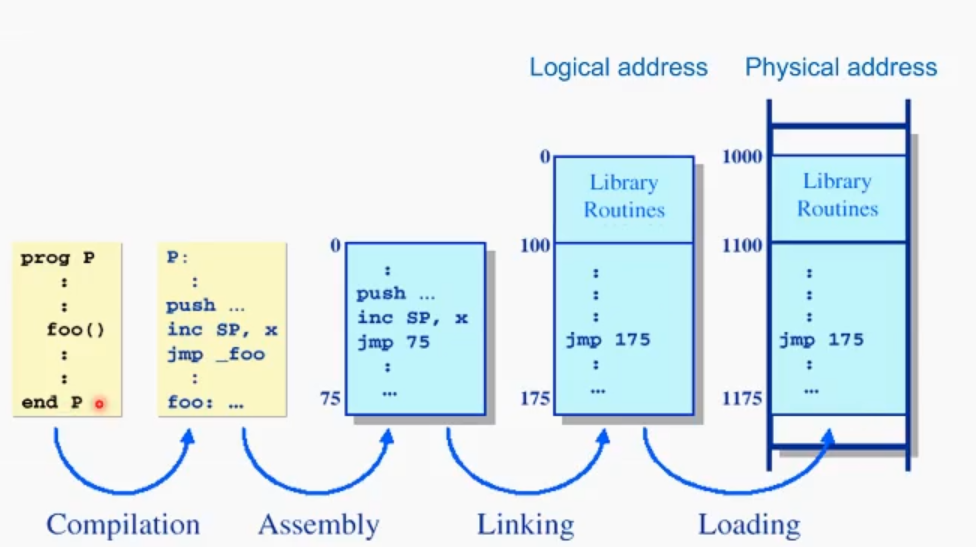
컴파일-> assembly-> linking - > loading
컴파일 된 코드는 어셈블리어로 바꾸고, assembly가 된 코드는 어셈블리어를 기계어로 바꾼다. 이후 코드에서 필요한 라이브러리들을 붙여주는 링킹 과정을 거친 후 physical memory어딘가에 loading되어 사용된다.
Hardware for Address Translation
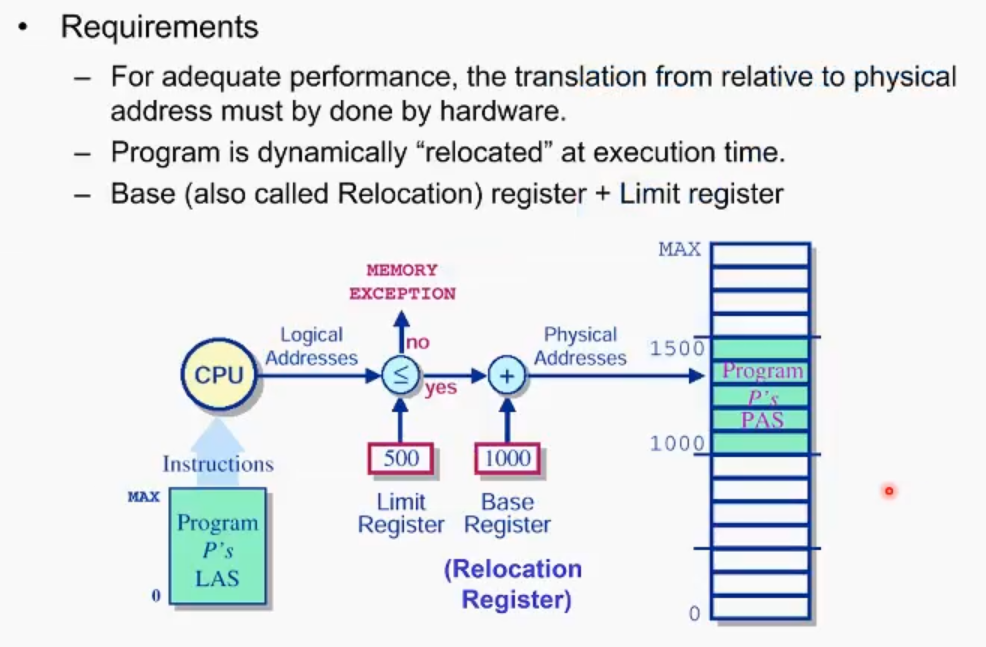
하드웨어, internal register들은 이런 과정들 속에서 여러가지 protection 체킹을 한다. 멀티 프로세싱을 해야하기 때문에 하나의 프로세스가 다른 프로세스의 공간을 침범하면 안된다. 또한 런타임에 만들어낸 논지주소가 자신의 프로세스 밖에 있으면 안될 것이다.
runtime에 cpu가 특정 주소를 access했을때 os와 아키텍쳐가 access하려는 주소가 제대로된 address인지 항상 검사한다. 위의 예시에서 limit register보다 큰지 작은지 먼저 검사한 후 여기에 base register값을 더해 실제 메모리에 접근하게 된다. 시스템은 현 프로세스가 로딩이 되어있는 base address를 알고 있고 기억해 둔다.. 또한 현 프로세스의 max size(limit register가)도 기억해 둔다.
swapping
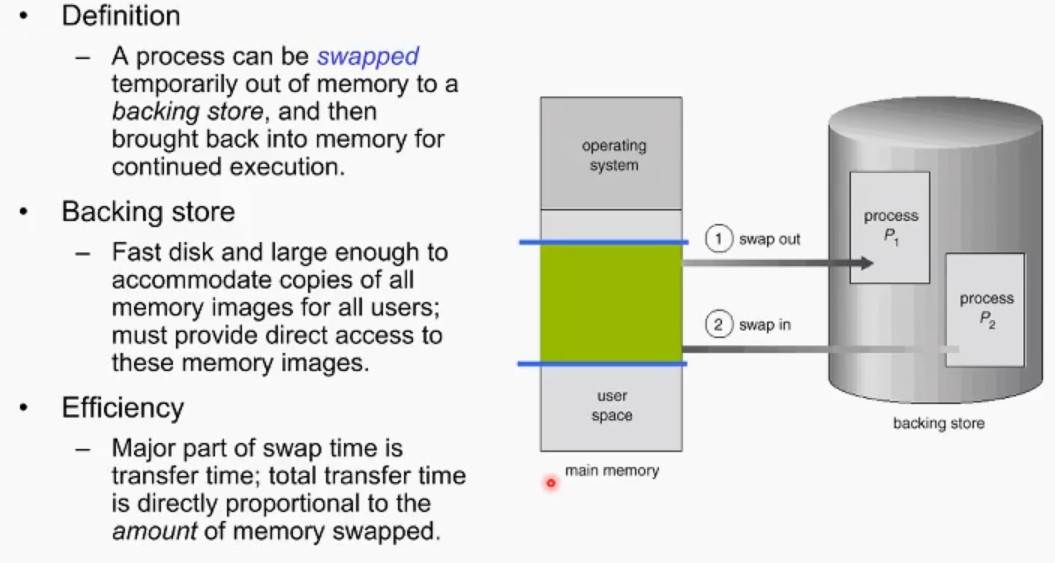
스웝핑: physical ram의 사이즈가 적을 때 run time에 현 프로세스의 특정 메모리 영역이 이미지로 non volatile 하드 디스크에게 swap out하고 필요한 process이미지들을 하드디스크로부터 swap in 하는 기법. 오버헤드가 큼.
Simple Memory Management

가상 메모리의 개념이 없는 간단한 형태의 메모리 management 방법들. 4가지를 다룰 것임.
전제 조건: 어떤 프로세스가 수행되기 위해서는 프로세스에 속하는 모든 continuous한 공간이 완벽하게 physical ram에 확보,로딩이 된다.
이런 simple memory management 정책들도 현재까지도 많이 쓰인다. 컴퓨터라는게 우리가 알고 있는 노트북, 데스크톱, general os등 뿐만 아니라 티비 셋톱박스, 전자레인지 가전기구 등등도 모두 컴퓨터이다. 이런 작은 컴퓨터들은 하드웨어 공간 역시 매우 작고 하는일도 간단해서 메모리도 작다. 이러한 embedded system에서 메모리 management를 최적화 할 필요가 있지만, 가상 메모리 기법은 너무 무거운 기법인 것이다. 이러한 작은 태스크를 하는 오에스가 하는 일이 뻔한데 범용의 가상 메모리 기법은 너무 오바다. 따라서 simple memory management 정책들은 이런 작은 일을 하는 오에스들(펌웨어)에서 여전히 쓰이는 기법임.
Fixed Partitioning

fixed partition이라는 것은 물리 주소 공간을 고정크기로 쪼내는 것이다. 쪼갤때 equal-size 와 unequal size가 있다. 기본적인 baseline은 쪼개진 것이 고정이라는 것이다. 하나의 방은 각각 오로지 하나의 프로세스만 사용 가능하다.

만일 프로그램이 고정된 fixed partition의 사이즈보다 크면 overlay라는 방법을 사용하여 고정 사이즈의 기법을 활용할 수 있다.
장점: 간단한것.
단점: 만일 프로세스가 방의 크기보다 매우 작은 메모리만을 요구한다면 방에 있는 나머지 메모리 공간은 비효율적으로 놀릴 수 밖에 없다. -> internal fragmentation 하나의 방안에 프로세스가 다 쓰지 못하고 남긴 공간.
이 문제를 해결하기 위해 unequal size-partition을 활용하기도 하지만 근본적인 문제는 해결 안된다.

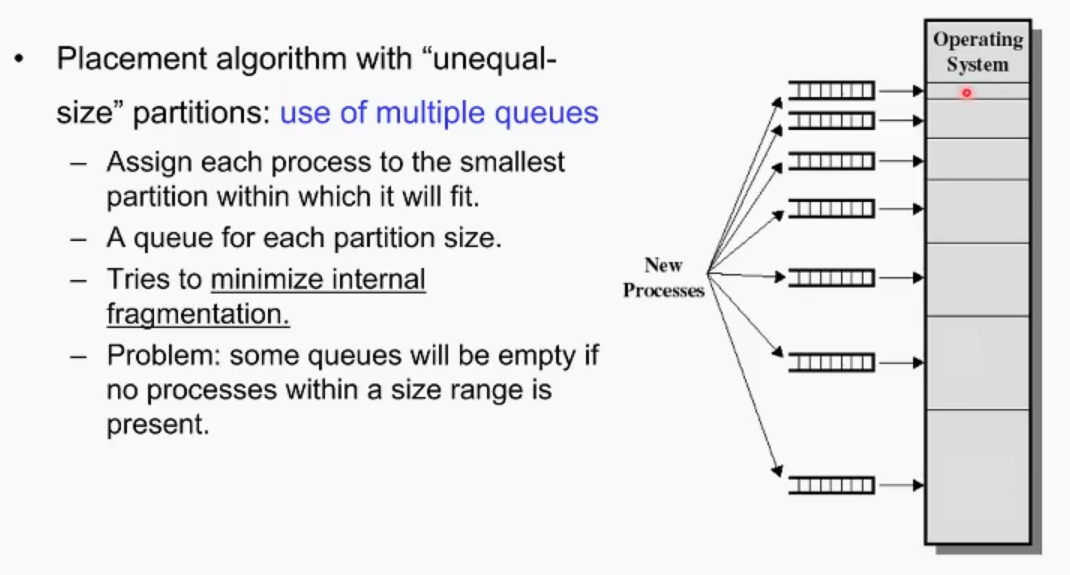
프로세스가 어느 방에 들어가야하는가. equal size는 크기가 다 똑같기 떄문에 어딜 드가든 상관 없다.
하지만 unequal은 선택지가 다양함. 방마다 큐를 만들어 놓는다. 내 프로세스가 들어오면, 이를 담을 수 있는 방중에 가장 작은 방의 큐에 프로세스가 들어간다.
하지만 이것 또한 문제인게, 이렇게 하면 특정 큐에만 프로세스들이 몰리게 된다.(만일 작은 사이즈의 프로세스만 계속 들어오면 작은 사이즈의 메모리 방에 계속 몰리게 됨.) 효율성이 떨어짐.

그래서 나온게 unequal partition을 하고, single queue를 두는 것이다. 안쓴 공간을 쓰겠다는 취지. 이러면 또 아까와 같은 internal fragmentation 문제가 다시 발생하지만, concurrency degree를 올릴 수 있는 장점이 생김.
internal fragmentation과 메모리 활용률는 trade-off 관계 이다..
Dynamic Partitioning

그렇다면 메모리 공간을 dynamic allocation을 하면 되지 않을까? 적어도 internal frgmentation은 해결될 수 있게끔 필요한 만큼만 주고 다쓰면 리턴받자. internal fragmentaion을 아예 없앨 수 있다. 하지만 이렇게 쓰면 또다른 문제인 external fragmentation이 발생한다.
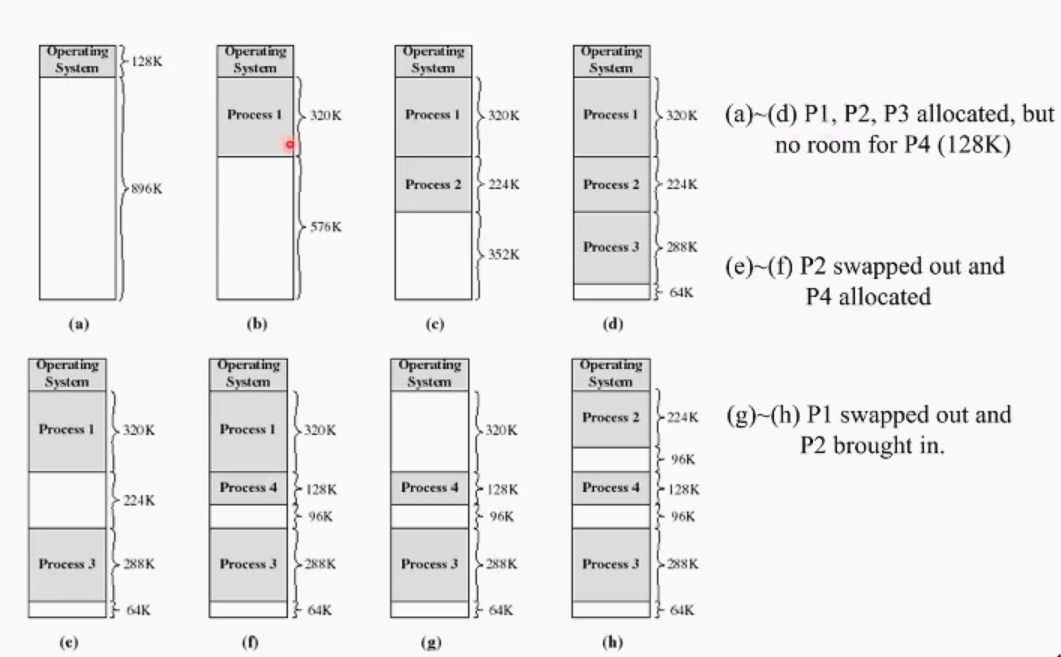
위의 상황에서 그림과 같이 중간중간 듬성듬성이가 바로 external fragmentation이다.
예를 들어 마지막 (h) 상황에서 만일 이다음에 들어오는 프로세스 크기가 계속 100k이상이라면, 두 개의 external fragmentation(96k, 64k)는 절대 영영 못쓰게 된다. 나머지 100k이상의 공간을 할당받고 있는 프로세스들을 스웝 아웃 하는 수 밖에 없다. → external fragmentation
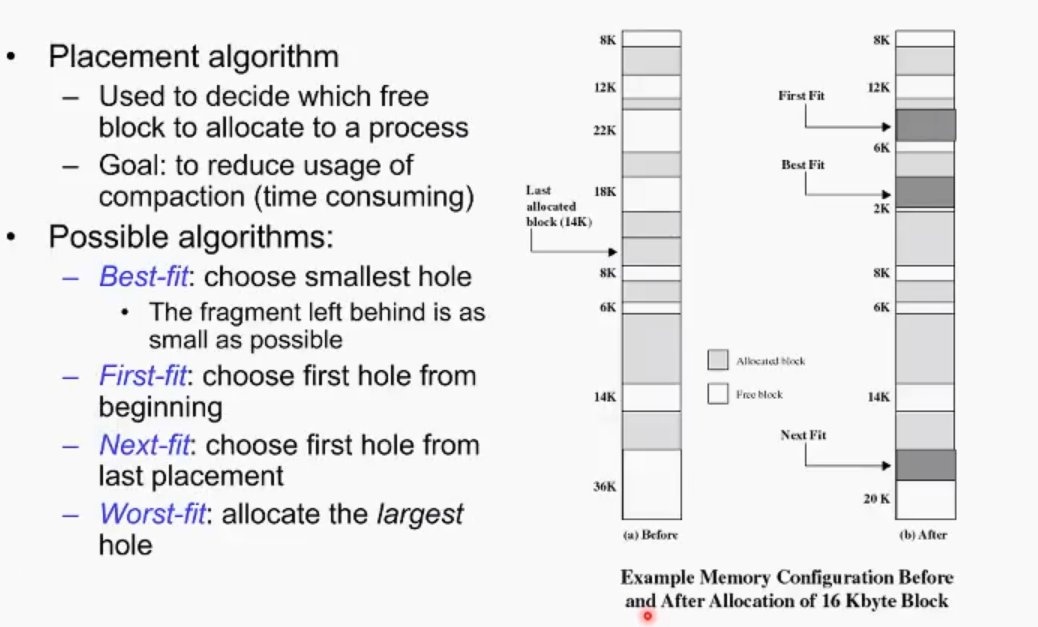
external fragmentation을 막기 위해 placement algorithm이 필요, -> 비어있는 공간 어디에 프로세스를 할당할 것이냐
best-fit, first-fit, next-fit, worst-fit 등이 있음.
best-fit: 할당할 수 있는 가장 작은 공간에 넣기.
first fit: 메모리공간을 풀 스캔 하면서 무조건 처음 만나게 되는 할당 가능한 공간에 넣기.
next-fit: last allocated block으로부터 스캔을 시작해서 첫번째로 만나게 되는 할당 가능한 공간에 넣기
worst-fit: 할당 후 남겨진 fragmentation중 가장 큰 쪽을 택하겠다. (왜 worst fit을 쓰는가? 가장 큰 공간에 할당한다는 것은 할 당 후 남는 공간이 가장 큰 external fragmentation이라는 뜻이다, 즉 fragmentation 공간이 가장 크므로 다음 프로세스가 남은 공간을 사용할 수 있을 확률이 가장 높다.)
정답은 없고 상황마다 다르다.
Fragmentation

위에서 살펴봤듯이 메모리 할당 방식에 따라 발생하는 두 가지 종류의 fragmentation이 있다.
Compaction

기존에 할당된 프로세스를 빈공간 쪽으로 밀어버리는 것.
조심해야할 점은 만일 프로세스가 block 상태(IO수행중)이라면 block 끝난 후에 해야함. 이런 류의 문제들이 골치.
Overlay 기법
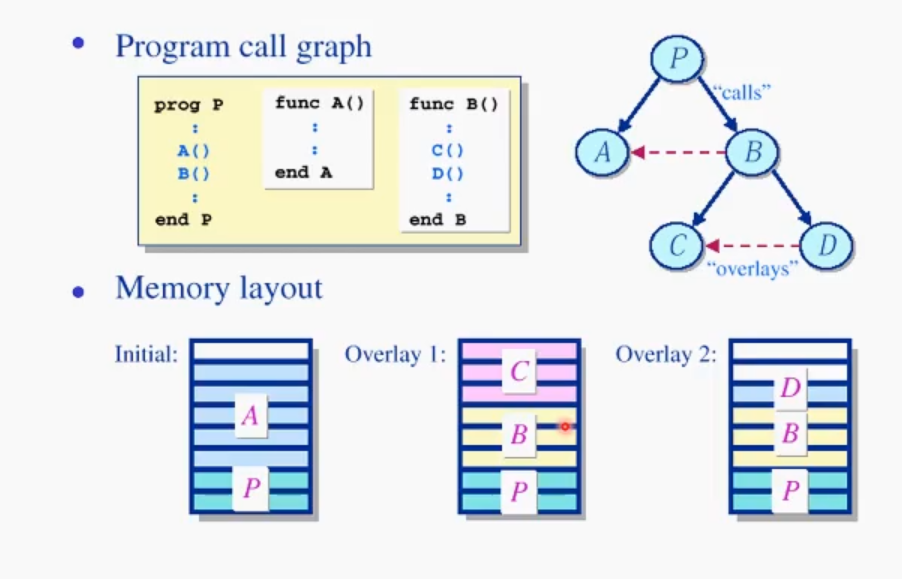
램이 많이 부족한 상태에서 큰 프로세스를 돌릴 수 있는 방법 중 하나이다.
프로그램의 크기가 너무 커서 만일 메모리에 못 들어간다면. 프로그램의 순서도, 즉 콜 graph를 그리고 이 sequence대로 프로세스 loading을 나누어 수행하는 것.
지금은 많이 사용하지 않지만 옛날에 물리메모리 크기가 작을 때 많이 사용했다고 한다.
Buddy System

실제로 리눅스 커널 안에서 커널의 메모리 할당(Kernel Memory Allocation) 에서 기본적으로 쓰이는 기법이다. 기본적인 철학은 고정 파티션과 다이나믹 파티션의 단점을 줄이고자 하는 방향이다. (internal, external frgmentation을 최소화하기) 리눅스 뿐만 아니라 다른 운영체제에서도 쓰이고 advanced한 기법임.
버디시스템에서의 메모리 할당의 기본은 2의 지수승이다. 특정 크기의 메모리를 요청 했을때 요청한 메모리의 크기가 두개의 연속된 2의 지수승 사이에 있느냐 확인을 하고 그렇다면 그 공간을 할당한다.
버디시스템의 알고리즘

현재 가용 메모리의 크기가 2의 u승이라 하자. 프로세스가 s만큼의 크기의 메모리를 원한다 가장하자. 2의 u 승에 해당되는 크기 중에 프로세스가 s만큼 할당을 받겠다 가정했을 때, s라는 숫자가 2의 u-1과 2의 u사이에 있다고 가정을 하면, 남은 2의 U승을 전체로 할당을 해준다. S가 만일 이보다 작으면 2의 U승을 다시 반으로 쪼개서 재귀적으로 사이즈 탐색을 지속한다.
프로세스가 블록을 다 쓰고 리턴을 할 때에도 연속된 붙어있는 블록이 비어있을 때에는 두 블록을 합해서 하나의 큰 블록으로 만든후 리턴한다.
버디시스템 예제
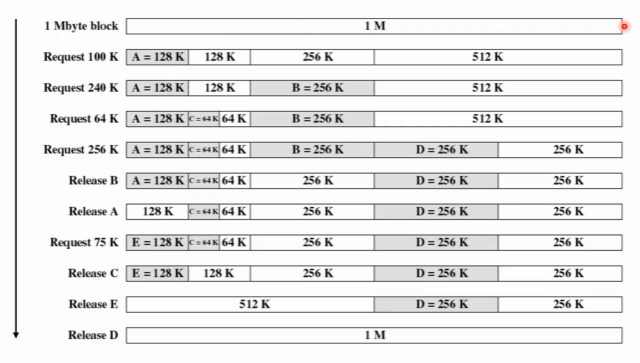
전체 1mb(2^10kb)의 빈 가용 메모리가 존재한다. 이런 상황에서 A가 100k를 원한다 가정을 할 때, 버디시스템 알고리즘에 따르면 128k 하나를 두고 세개의 빈 블록이 생기게 된다.
Relase C하는 부분에서 프로세스 C가 쓰던 64k의 옆공간(버디) 64k도 비어있다. 이런 상황에서는 128k를 반환한다. 왜냐하면 시스템은 비교적 젤 큰 공간을 블록으로 남겨두려 하기 때문이다, 쪼갠 후에 남겨두면 계속 쪼개지기 때문에 계속 손실이 발생. 그러므로 최대한 큰 블록으로 남겨둬야한다.
버디란 정확이 무엇을 의미하는가? 양옆이 비어있다고 버디가 아니라 이진트리에서처럼 부모노드가 같아야만 버디이다.
Release를 하는 상황에서도 양옆에 같은 공간이 비어있다고 해서 무조건 합치는 것이 아니라 오직 버디끼리만 메모리 공간을 다시 합칠 수 있다. (쪼개지는 것도 마찬가지)
Paging

페이징 기법은 논리적인 contiguous한 주소공간을 맵핑한 물리공간이 contiguous 하지 않아도 된다는 특징을 지닌다.(지금까진 논리 공간이 물리 공간에 연속적으로 맵핑 되어야 했음.)
물리 메모리를 고정된 사이즈인 프레임으로 나누고 논리 메모리를 페이지라 불리는 고정된 크기로 나눠준다. 어떤 페이지가 어떤 프레임에 맵핑되었는지 모두 트랙킹 한다.(프레임의 크기와 페이지의 크기는 동일하다)
결론적으로 물리적으로 n page로 구성된 프로세스가 있다면 n개의 프레임이 필요하다는 뜻임. 이때 n개의 프레임이 절대 연속적일 필요는 없다는 의미이다. 연속적이지 않더라도 n개의 프레임만 있더라면 프로그램을 돌릴 수 있다.
이를 위해서 논리주소와 물리 주소를 translate해주는 메타 정보인 page table이 필요하다.
이 페이지 테이블은 반드시 모든 프로세스당 한개씩 존재해야만한다
하지만 페이징 기법을 사용하면, internal fragmentation은 존재하긴 한다.

논리 주소를 나타내는 법
프로세스의 논리주소공간을 페이지라는 단위로 일정하게 쪼갬.
페이지라는 공간을 나눈 결과, 논리 주소의 표현이 달라짐.
이제는 (p,o) page number와 page offset 으로 프로세스의 가상 메모리 공간의 주소를 나타냄.
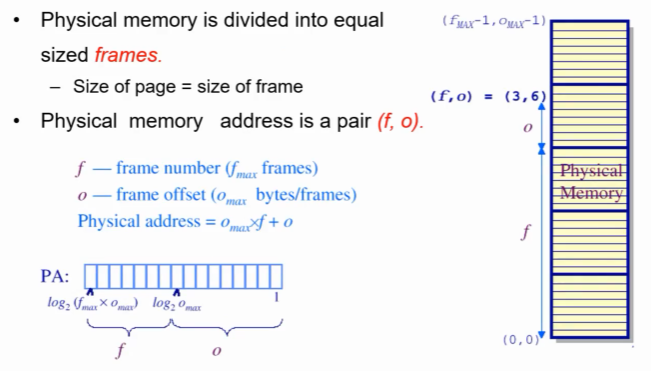
물리 주소를 나타내는 법
물리 메모리의 주소도 마찬가지로 프레임이라는 단위로 일정하게 쪼갠다.
(f,o) frame number와 frame offset으로 메모리의 physical address를 표시함.

페이징 기법이란 연속적인 주소공간으로 구성된 페이지(논리 메모리 공간)들을 물리적으로는 굳이 연속적이지 않은 임의의 물리 주소공간에 배치할 수 있음을 의미한다.
필요에 따라 모든 페이지들이 physical memory에 맵핑이 안되더라도 cpu는 우리의 프로세스를 처리할 수 있다.(이후 나올 가상메모리의 기본이 되는 철학이다).
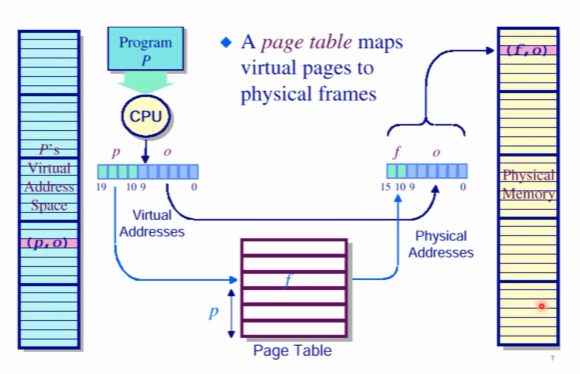
주소 공간의 변환.
페이지 테이블은 어떤 페이지가 어떤 프레임에 맵핑되어있는지 정보를 지니고 있다. 논리 메모리와 물리 메모리를 똑같은 수의 페이지와 프레임으로 나누고 페이징 기법을 적용시킨다.
위의 예시에서는 주소공간으로 2의 20승을 지니는 프로세스다.
이상황에서 하위 열비트를 페이지 수로, 상위 10비트를 offset으로 설정.
페이지 주소(p,O) 를 (f, O)에 연결시키는 과정임
먼저 페이지 테이블에서 p번째 페이지를 확인, 여기서 이 페이지가 f번째 frame에 연결되었다는 것을 알아냄. 여기에 offset을 더해 물리 주소로 변환하게됨.(offset을 공유 가능. 왜냐? 논리 메모리와 물리 메모리를 똑같은 수의 페이지와 프레임으로 나누어놨으니)
페이지 테이블에 내용이 몇개냐 몇개의 엔트리가 있느냐->페이지 테이블의 엔트리 개수는 프로세스가 지니는 페이지 수와 같다.
다시 말하면, 페이지 테이블 엔트리는 프로세스가 가지고 있는 로지컬 페이지 개수만큼 있다. 모든 페이지 마다 하나의 엔트리를 지녀야함.
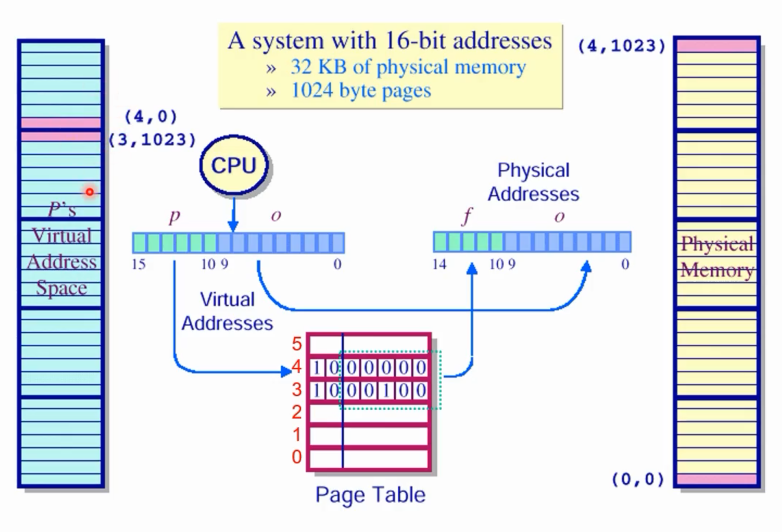
논리주소 공간과 물리 주소 공간을 어떻게 맵핑되는지 한번 더 위 그림의 예제를 통해 살펴보자
논리 주소는 2의 16승까지 가능하다.
물리 메모리의 주소는 2의 15승까지 가능하다.
논리 메모리 공간은 다섯개의 페이지로 나뉠 수 있으며 현재 빨간색을 칠한 부분끼리 (논리/ 물리 메모리 그림 위에서) 맵핑되어 있다. 먼저 논리메모리(3,1023)을 맵핑해보자. 페이지 테이블에 페이지 수인 3 에 저장된 엔트리를 살펴본다 . 그러면 00100 즉 4번쨰 프레임에 맵핑되었단 사실을 알 수 있게 된다. 오프셋(1023)은 둘다 같은 수를 사용한다.
(페이지 테이블의 앞에 있는 두 비트는 뒤에서 설명)
Page table Structure
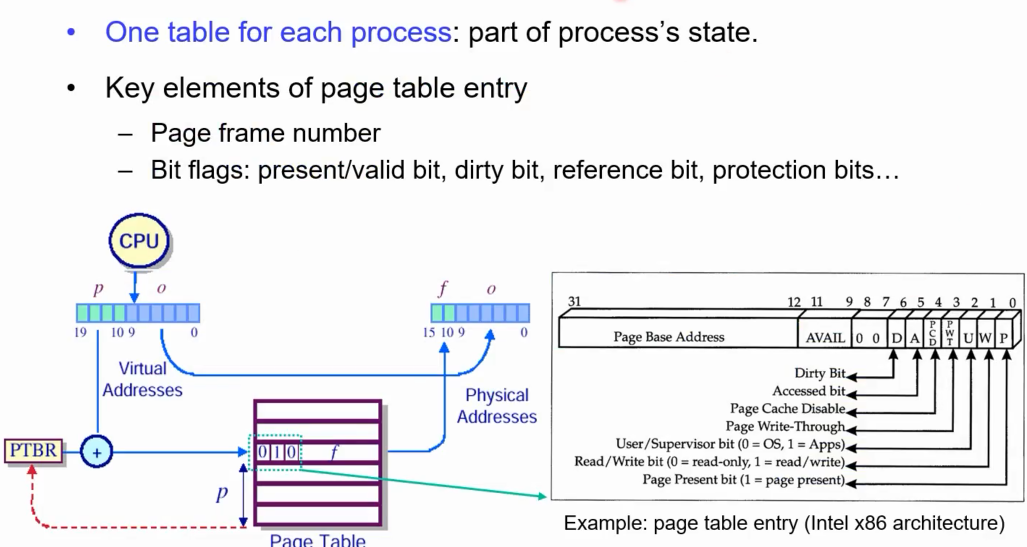
페이징 기법을 구현할 때 반드시 지켜야 하는 것은 프로세스당 하나의 페이지 테이블을 지녀야함.
실제로 하드웨어적으로 구현은 어떻게 되나?
실제 인텔 아키텍쳐의 예시
페이지 테이블 공간에서 f number 외에 상위 12비트를 통해 여러 구현상 필요한 정보들을 저장해 놓는다.
페이지 주소 뿐만 아니라 여러가지 ‘bit flags’들에 대한 정보도 담고 있음. 상위 20비트를 제한 나머지 12비트에는 다양한 정보들이 담겨있음.
Page Sharing
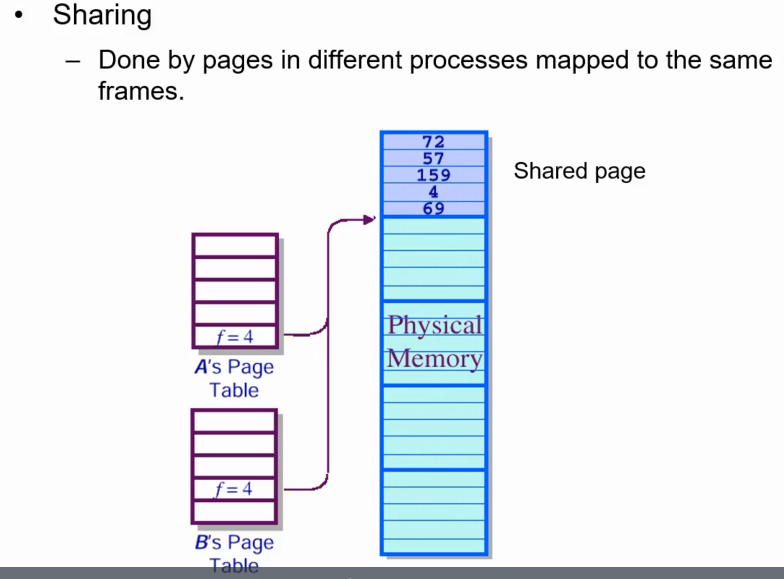
멀티 프로세싱의 경우 특정 이미지, (shared library, 표준 c library) 등을 공유할 수 있다. 예를 들어 표준 C 라이브러리를 한 물리 주소공간에 할당해 놓고 여러개의 프로세스가 해당 공간을 레프런스 하게 하는 상황 등을 생각해 볼 수 있다.
Page Table Implementation

페이징과 관련된 가장 큰 특징은 다시 설명해 논리적으로 연속적인 주소공간이 물리적으로 연속적일 필요가 없다는 것이다. 이 아이디어는 external fragmentation을 아예 없앤다. 물론 internal fragmentation은 존재한다. 또한 physical memory에 프로세스가 가지고 있는 모든 페이지를 전부 loading할 필요도 없는 장점이 있다.
논리적인 장점을 얻기 위해 감수해야할 희생, 즉 오버헤드도 존재한다.
-
성능 이슈: 페이징을 쓰면 logical address를 physical adress로 바꾸는 선행 절차가 필요하고 다시 그 주소로 실제 pysical memory에 access해야되어서 총 두번의 메모리 access가 필요하다. 프로세스의 실행 속도가 두배가 느려진다고 볼 수 있음.
어떻게 페이징을 통한 주소변경에 따른 오버헤드를 줄일 수 있을까?
-> 이 문제를 해결하기 위해 고안된 특별한 TLB라는 associative memory 하드웨어를 두어 아주 빠른 memory translation을 처리하게 한다.
Associative Memory

컴퓨터 구조 관점에서 associative memory라는 구조가 있음. 병렬 서치를 가능하게 하는 메모리 구조이다. associative 혹은 content addressable memory(CAM)이라고 한다. 키를 주면 value가 단번에 튀어나오는 구조이다.
로지컬 page number를 주면 한번에 대응되는 f number을 준다는 개념.
구현하는데 여러가지 서킷 트랜지스터 등과 같은, 하드웨어적인 비용이 발생. (메모리가 아니라 레지스터로 구현되기 때문에 생각보다도 엄청 빠르긴 하지만 그만큼 비싸다.)
Translation Lookaside Buffer(TLB)
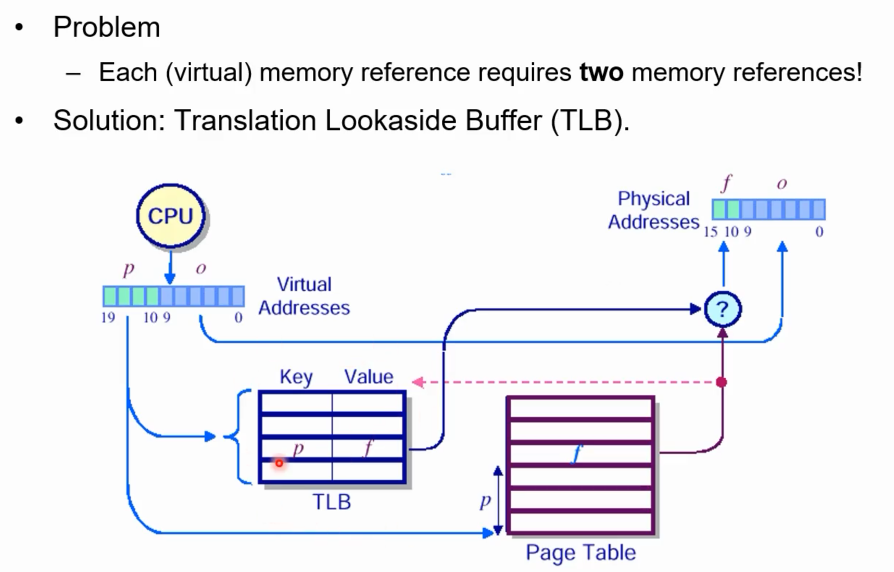
페이지 테이블은 그대로 둔다. TLB를 연결한 것만 다름. TLB에는 p, f라는 pair을 지닌 몇개의 entry가 존재한다. 하지만 비싼 하드웨어라 엔트리 수가 많지는 않고 몇 개만 있다. 하지만, p만 주어진다면 한번에 f를 얻을 수 있다.
기존에 하듯이 페이지 테이블에서 p에 해당하는 f를 찾는것 을 하기 전에 먼저, TLB에서 현재 p값로 시작하는 key 있는지를 찾아본다. 만일 있다면 f를 얻어 바로 f,o를 물리주소에서 access함. 매우 빠르고 constant time에 이루어짐.
만일 TLB에 해당하는 p key가 없다면 다시 page table을 lookup해서 f를 얻은 후 이전처럼 f,o를 구성하게 된다. 이때, p,f를 다시 TLB에 저장해준다.(약간 캐쉬같음) -> 이 경우는 TLB가 없을 때보다 성능 저하가 더 온다는 단점이 있다. TLB table look up의 오버헤드까지 더해짐.

이러한 TLB를 통한 access를 할 적에 성능 변화를 측정해볼 수 있다. TLB를 lookup하는데 쓰는 시간은 엡실론 이라고 하자. 메인 메모리를 access하는데 드는 시간을 1ms라고 하면 엡실론은 1ms보다 훨씬 작은 시간이다. Hit Ratio(alpha)는 p라는 page number가 TLB안에 있을 확률이다.
EAT(Effective ACcess Time): 평균적으로 로지컬 어드레스가 만들어졌을 때 실제 메모리를 통해서 얻을 수 있는 성능을 의미한다.
hit 할때는 1 + e(TLB + 실제 메모리), miss 할 때는 2 + e(페이지 테이블, 실제 메모리, 총 두번 access하니까)
알파가 1에 가까우면 거의 1에 가까워지고 알파가 0에 가까우면 거의 2에 가까워진다. 엡실론은 하드웨어 기술이니 알파(hit ratio)를 최대한 크게 늘려야한다.
가장 손쉬운 hit ratio를 늘리는 방법은 TLB의 엔트리 size를 늘리는 것. 하지만 비싸다는 문제가 있음.
대신에 hit ratio를 높이기 위한 여러가지 운영체제 차원의 기술이 쓰임.

페이징 기법을 쓰는 경우에 프로세스마다 하나의 페이지 테이블이 존재한다. 만일 1000개의 프로세스라면 1000개의 테이블이 필요하다. 하나의 프로세스를 위한 페이지 테이블의 크기는 어떨까? 32bit 아키텍쳐에서 페이지의 크기를 4kB로 설정 했을 때 프로세스가 가질 수 있는 페이지의 maximum은 2^32 / 2^12 x 4( 전체주소공간크기/ 페이지 사이즈), 즉 4mb의 Ram이 소요되는 것이다이다. 프로세스가 천개라면 페이지 테이블을 위해서만 메모리가 4G가 필요하다는 뜻이다. 너무 많은 공간이 필요하고 현실적이지 못함. 이 엄청난 크기를 줄일 방법이 필요함.
페이지 테이블 양의 전체크기는 크지만 램에서는 모든 프로세스의 페이지 테이블이 모두 꼭 다 있을 필요는 없다. 오직 쓰이는 부분만 적절하게 잘 ram에 놓으면 아무 문제가 없을 것이다. -> 여러가지 방법이 있음. Multi-level, hasehd, inverted 등.
Hierarchical Paging(multilevel paging)

- hierarchical(multilevel) paging. 페이지 테이블의 레벨을 여러 개 두자. 그리고 현재 필요한 엔트리만 램에 적재하는 기법을 쓰자.
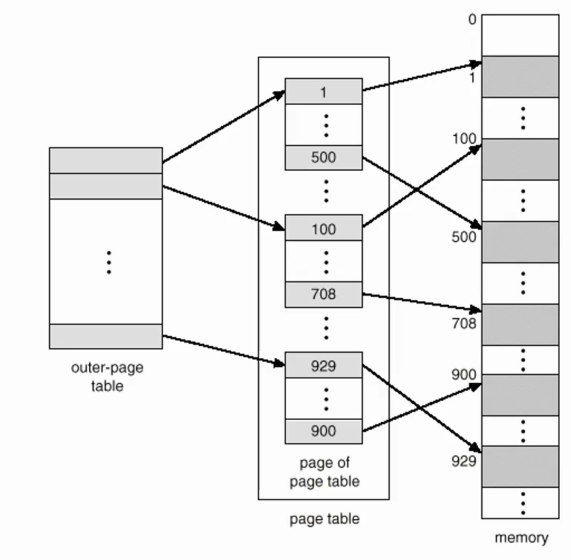
위 예시의 시스템에서는 프로세스당 두 단계의 page table이 존재하는 것이다. outer와 그냥 page table.
outer page table의 특정 entry는 두번째 페이지 테이블 내에 존재하는 여러 page들에 대한 base entry를 지닌다. 특정 가상 주소가 들어왔을때 outer page table에서 특정 값을 정하고 이 값을 기반으로 두번째 page table을 고르고 마지막으로 실제 frame number을 받게 된다.
즉 두번의 translation을 거쳐서 실제 instruction이나 acess data를 얻게된다는 idea다.
예를 들어 1000페이지 짜리 책이 있을때, 기존의 페이징은(1단계 페이징 기본 기법)은 책에서 특정 페이지의 특정 라인을 찾으라는 이야기로 비유된다. 반대로, 2단계 페이징은 몇 챕터의 몇번째 페이지의 몇번쨰 줄을 찾으라는 이야기로 비유된다. 즉 outer page table은 각 챕터의 시작정보(base entry)를 지니고, page table의 entry들은 그 챕터가 속한 페이지에 대한 내용을 담고 있는 것이다.
두개의 페이지 테이블만 지니면은 어느 순간에 특정 memory adress나 데이터에 access가능하다.
두 단계 페이징의 이점 대하여
page directory 2^10, 각 page directory의 entry는 또다시 페이지 테이블 2^10 을 가리키고 있음. 결국 2^10 x 2^10 = 2^20으로 1단계 페이징의 page table size인 4mb와 동일하다. 그렇다면 왜 storage 상의 이점이 있다고 하는 것일까??
우선 os는 프로세스마다 page directory를 할당한다. 이때 2^10의 page direcetory가 각각 가리키는 page table은 아직 할당이 되지 않고 논리적으로, 가상으로만 존재한다. 이후, page directory를 사용할때 그제서야 할당이 되며 메모리에 올라간다.(만일 deallocate되면 하드상에 존재할 것임.) 따라서 4mb 자체가 모두 램에 올라가 있을 필요가 없고 필요한 녀석들만 그때그때 생성해서 쓰기 때문에 저장 공간상의 이점이 존재한다고 하는 것이다.
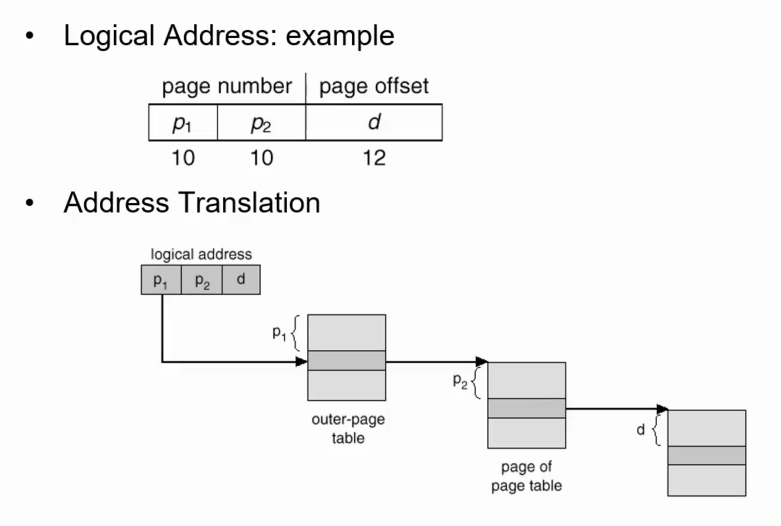
virtual address가 32비트인 아키텍쳐에서 총 32비트 주소 공간을 가지는데 여기서 pagenumber는 20비트, page offset은 12비트이다. page number를 두 단계 페이징을 쓰기 때문에 10비트 10비트 두개로 쪼개진다.
먼저 p1의 값으로 outer table에서 inner table에 대한 base entry를 받고, 여기에 p2 값을 더해 실제 메모리의 base entry를 받게 된다. 마찬가지로 마지막에는 offset으로 실제 접근하고자 하는 주소에 접근하게 된다.
단점은 페이지에 접근하기 위해 access하는 페이지 테이블의 수가 많아짐에 따라, 전체적인 접근 시간이 느려진다.
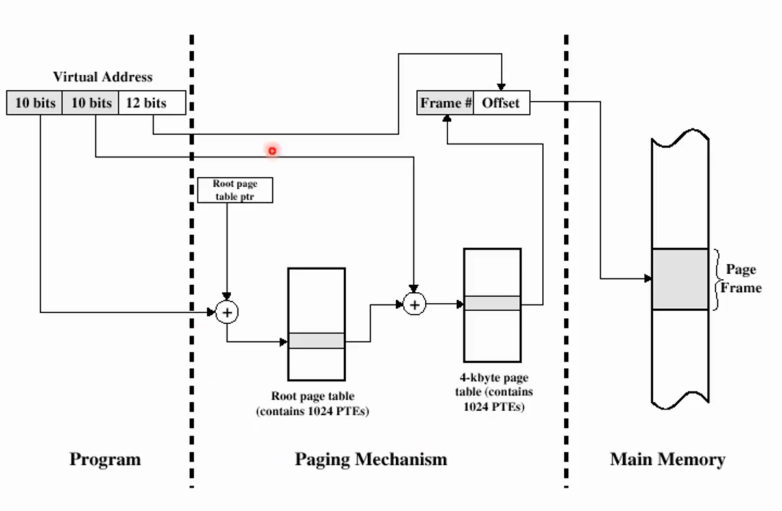
두 단계 페이징을 쓸 때 첫번째 페이지 테이블과 2번째 테이블 페이지과 같이 여러 단계를 두면 run time에 page table의 storage overhead를 엄청나께 쭐일 수 있다. 즉 ram에 올라갈 페이지테이블의 양이 줄어드는 것이다.
하지만 이런 이득 역시 추가의 memory access를 필요로 한다. 하나만 있을 때만 해도 두번 access했는데 여기서는 토탈 3번의 access가 필요하다는 것. 즉 단계가 올라갈 수록 page table의 양은 줄어들지만 성능이슈가 발생된다. 현실에서는 많은 기술들 TLB, cache등의 기술이 보조된다.
32비트에서는 두단계면 많이 충분하지만 64비트에서는 2단계도 부족해 3단계 페이징을 쓴다. 즉 토탈 4번의 메모리 access를 한다는 것이다.(앞선 책 예시 비유를 다시 들면 이거는 세계 백과사전 전집 수준. 몇 전집, 몇 권의 몇 챕터의 몇 줄을 찾는 것이라고 할 수 있다.)
Hashed Page Table
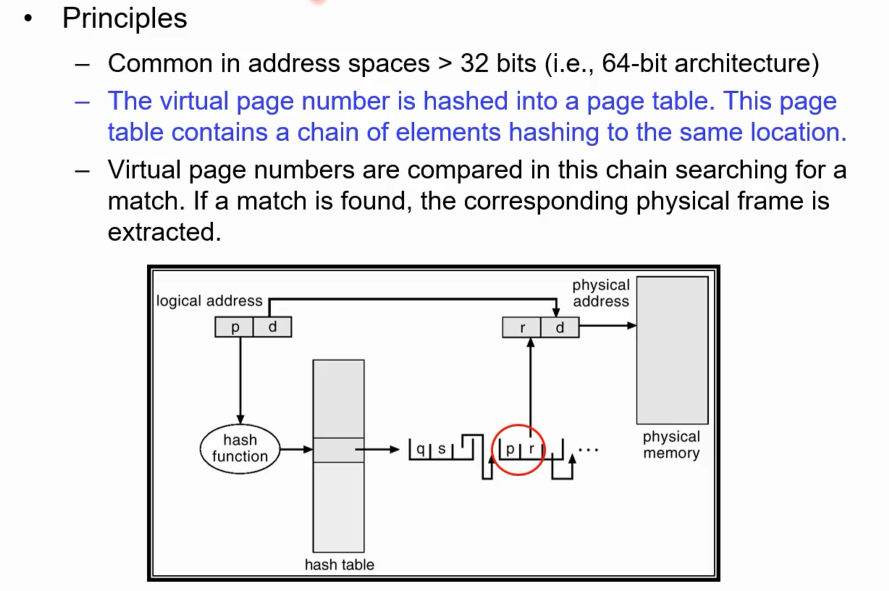
64비트 아키텍쳐와 같은 아주 큰 주소공간을 갖는 아키텍쳐에 활용되는 기법이다. 해쉬 테이블을 만들어 logical address의 p를 hash function 에 넣으면 hash table에서 엔트리가 나오게 될 것이고 이 엔트리에 p,r에 해당하는 정보를 담고 있는 것이다. (p가 페이지 넘버고 r이 frame 넘버).
여러 개의 주소공간의 hash 값이 conflict이 날 수 있다. 하나의 hash 함수가 다른 p에 대해서도 같은 값을 낼 수 있기에 conflict 이 발생하고 이런 경우에는 linear search를 통해 해당 값을 찾게 된다.
이런식으로 hash table을 사용해 많은 process가 요구하는 page table entry의 갯수를 줄인다는 철학의 개념이 hashed page table이다. 개념이 이렇고 실제 구현은 상당히 어렵고 복잡하다.
Inverted Page Table

프로세스가 아주 많은 경우 프로세스 개수에 비례하는 page table의 양 때문에 multilevel, hash table과 같은 기법들을 활용해 entry 수를 줄이려고 노력했다.
inverted는 시스템 전체의 프로세스 개수에 상관없이 page table을 오직 하나만 유지하자는 역발상이다.
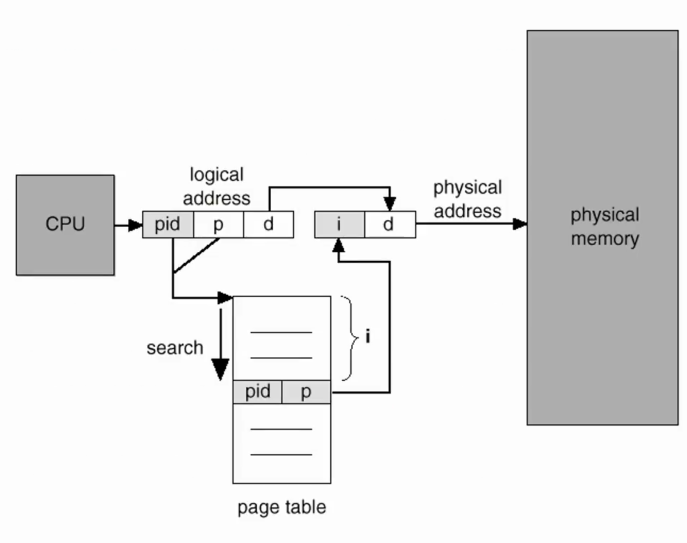
인버티드 테이블의 개념을 보여주는 그림.
앞선 기법들과는 달리 페이지 테이블 엔트리가 pid, p로 들어가 있다. 이 pid, p 쌍은 page table의 i번째에 들어가 있으며 이 i가 바로 frame number가 된다.
피지컬 메모리의 i번째의 주인 프로세스가 누군지 기록하는 것 즉 i번째 프레임에 들어간 자료는 pid인 프로세스의 몇번째 page가 주인이다 라는 듯이다.
key가 pid와 p 두개가 되고 이를 가지고 page table을 search한다. 만일 page table의 i번째 값이 pid, p 값이라면 i번재 frame이 내가 구하고자 하는 주소라는 의미이다.
만일 pid, p가 없다면? page fault가 발생하는 것을 의미한다. 즉 physical frame 속에 프로세스가 속하는 p가 없다는 의미이다. 이런 상황에서는 다시 원래의 page table에 access해서 page table을 메모리에 불러오고 본 프로세스가 수행할 수 있도록 절차를 거치야 한다.
정리하자면 hit하는 경우는 위 설명처럼 가지만, fault하는 경우는 문제가 매우 커진다. fault 상황에서도 어떻게든 page table을 결국엔 access해야만 한다. 이 경우에 page table은 램에 갖고 있는것이 아니라 보통 storage hard disk에 가지고 있기 때문에 fault 할 때 overhead는 매우 커지게 된다.
fault시 오버헤드는 매우 커지지만, 최소한 페이지 테이블을 램에 가지고 있지 않기 때문에 램 공간에 대한 이슈를 줄일 수 있다.
인버트 테이블 역시 단독으로 쓰이지 않고 다른 페이지 테이블 기법들과 섞어서 사용한다.
Segmentation
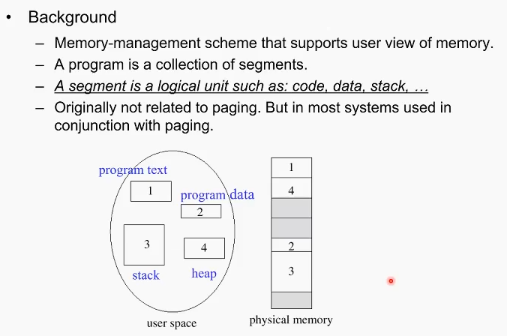
프로세스의 이미지는 여러개의 부분으로 나눌 수 있다. code, program text, program data, heap stack 등등. 이미지를 가만히 보면 똑같은 모든 구성 요소가 같은 것이 아니라 구분에 따라 아니라 특성이 존재한다.
이미지가 가진 컨텐츠의 특성에 따라 메모리 할당을 하자. 그렇게 나뉜 메모리 블록을 segmentation이라고 한다.
예를 들어 code segment는 read only이니, write가 안된다. 만일 누군가 code segment에 쓰려 하면 이거는 100% illegal approach임을 알 수 있다. 만일 global data라면 read, write 연산이 가능함.
페이징은 이러한 논리적인 segmentation의 개념이 아니라 linear address를 똑같은 사이즈로 쪼갠 것이다. segmentation의 개념은, 이미지가 가진 컨텐츠 특성에 따라 따로 관리하자 이런 철학이다.
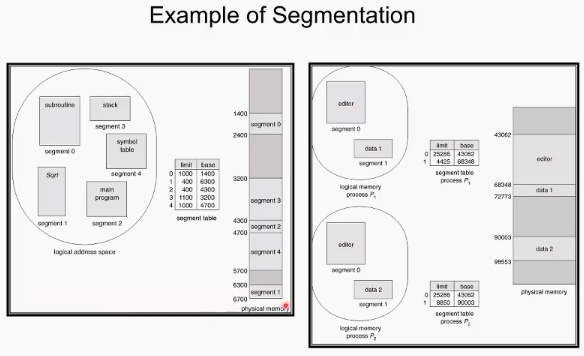
예시의 두번 째 그림을 보면, 두 프로세스가 공통적으로 editor를 사용하고 있음. 이 editor는 physical memory에 한 카피만 올려두고 각각 segment단위로 각 프로세스 내에서 테이블로 관리된다. 각 프로세스의 segment를 보면 공유되는 editor 영역의 세그먼트는 같은 주소를 가리키는 것을 볼 수 있다.
부가적으로, editor는 코드이므로, 수정이 불가하게 끔 관리할 수 있다.
좀 더 logical한 management를 할 수 있는 여지가 생김.
segmentation Architecture
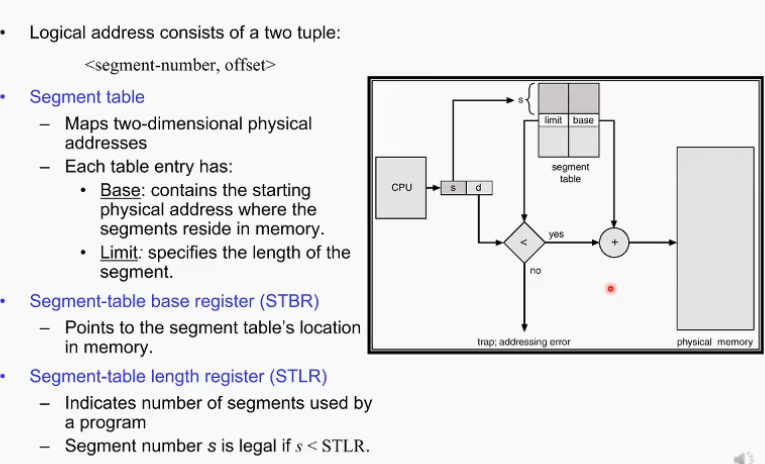
이렇게 하기 위해선 하드웨어가 segmentation architecture, 즉 segmentation 기능을 지원하는 하드웨어가 필요하다.
segment table: 마치 페이지 테이블 처럼 어떤 segment가 어디서부터 얼마만큼 있다라는 정보를 지니고 있다. 모든 segment에 대해 base address와 limit(maximum크기를 나타냄) 정보를 담고 있다.
CPU가 어떤 프로세스를 segmentation에 기초에 돌릴 적에 이 논리 주소가 s,d로 표현이 된다. 몇번째 segment에 몇번째 entry(offset)이냐는 식.
s, d로 테이블에 접근하면 테이블의 s번째에 base주소와 limit 정보가 있다.
STBR: 시스템이 segement table의 base를 지닐고 있는 register
STLR : 최대 몇개의 element를 가질 수 있는지 담고 있는 segment table length register

segmentation은 dynamic memory allocation과 유사하다. fixed가 아니라 필요한 만큼 할당 받고 끝나면 없어지는 식.
allocation과 deallocation이 반복적으로 이루어지고 그러다 보니, fragmentation(external)이 발생하게 되고 segment어디를 쓰냐에 대한 allocation 이슈 등등이 존재.
여기도 상황에 맞게 first fit, best fit, 등의 방법들을 선택해야한다, external fragmentation이 필연적으로 발생하기 때문이다.
Segmentaion vs Paging

페이징은 external한 fragmentation 을 없앨 수 있지만 logical한 관점에서의 MANAGEMENT가 적절하지 않다. 특정 페이지가 의미가 다른 segment를 포함할수도 있기 때문에. 또한 크진 않지만, internal fragmentation은 여전히 존재한다.
segmentation은 external fragmentation이 발생할 여지가 있음.
그렇다면 페이징과 segmentation을 섞으면 어떨까

intel x86 아키텍쳐에서 segmentation과 paging을 적절하게 섞어 쓸 수 있는 기능을 제공한다. 세그멘트 안에서 동일한 크기로 나누 어 페이징을 하자. segment의 특정내용들이 pageable하게 메모리 할당을 하자
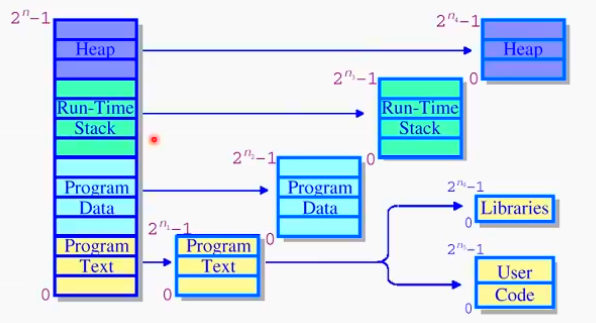
위의 예시 그림에서 색깔별로 각각 다른 segment를 의미한다. 하나의 segment를 page로 나눈다. 네 개의 segment 중 하나의 segment를 다시 페이지로 나눈 것이다. 즉 program text에 해당하는 segment를 내부적으로 여러개의 page로 나누어 paging으로 쓰겠다 이 의미.
각 segment당 paging을 사용해 메모리 management를 하겠다. 주소의 표현은 마치 두단계 페이징처럼 세 개의 엔트리로 구성된다.
s : segment number
p: page number
o : apge offset

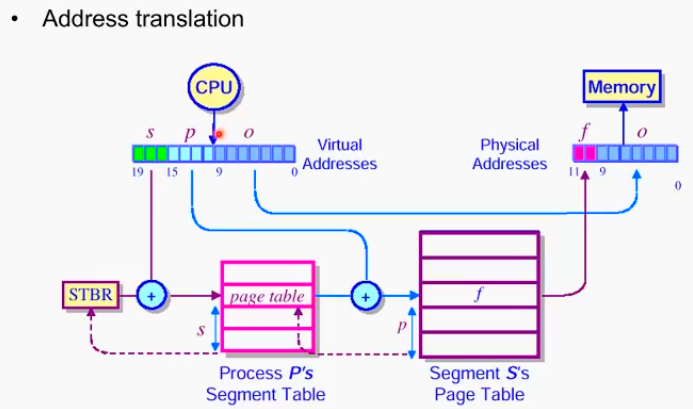
s,p,o (논리주소)가 f,o(물리주소)로 바뀌는 과정이다.
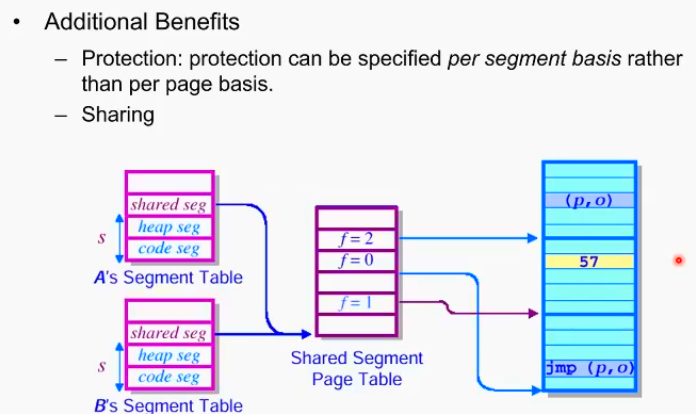
이러한 segment + paging 조합의 강점:
semantic 측면에서의 강력한 관리가 가능
ex) 특정 코드 세그먼트에 대해 permission을 같이 유지한다든가, 공유자원을 관리 등
위 그림에서는 프로세스 A, B에서 공유된 자원을 shared segment page table에 저장하고 있다. 이를 통해서 공유된 자원의 share, permission 문제 등을 갈끔하게 해결해낼 수 있다.
세그먼트만 단독으로 쓰이는 경우는 잘 없다. 대부분 페이징과 함께 쓰임.
인텔 아키텍쳐는 segment가 매우 잘 구현되어있음. os개발자는 이를 잘 활용해 segment 특성에 따른 protection을 효율적으로 수행 가능.
Case Study - Segmentation with Paging in Real system
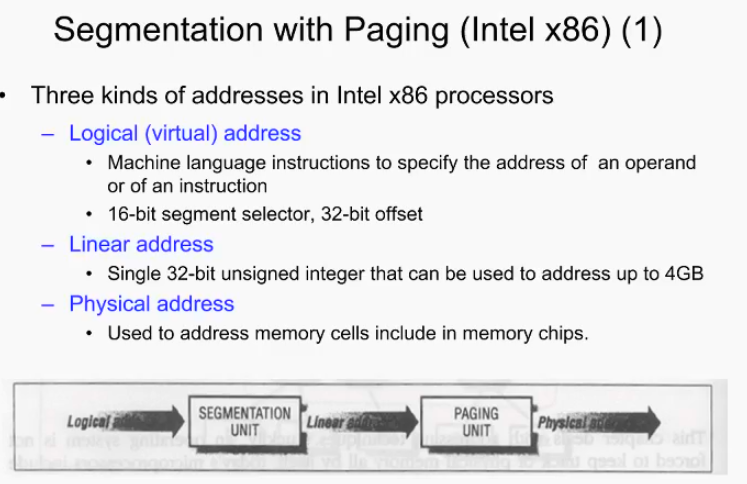
인텔 아키텍쳐에서는 메모리 주소를 세 가지 개념으로 나누어 관리한다. 정확히 말해서, 위에서 우리가 사용한 개념은 논리(가상)주소= Linear주소였다. 하지만 인텔에서는 이를 명확히 구분한다.
logical adress가 segmentation을 통해 linear address로, linear address가 paging을 통해 physical address로 변환된다고 한다. segmentation과 paging을 조합한 기술
logical address: 컴파일러가 generate하는 address. 두단계의 paging을 통해 물리 주소로 바뀜
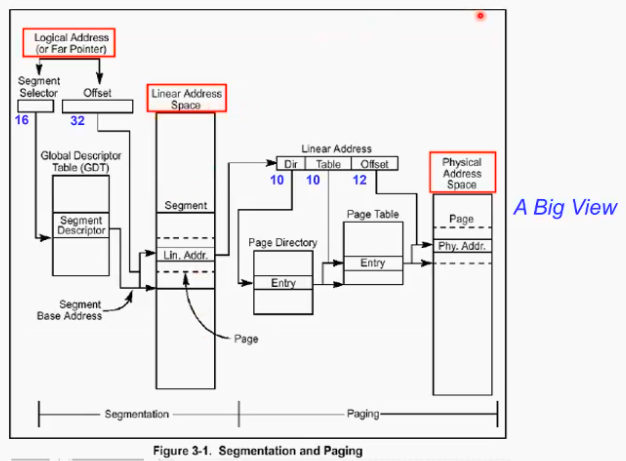
논리주소(16비트 segment selector + 32비트 offset)에서 시작한다
처음에 gdt라는 테이블에 16비트의 segment selector로 접근하여 어떤 segment를 access할지 받아옴(코드냐 데이터냐 힙이냐 등등). 여기서 offset은 32비트로 해당 세그먼트 안에서 어디를 access하는 거(논리주소)인지 해석하고 이것이 Linear Address가 된다
Linear address상에서는 2의32승, 즉 0에서 4기가 사이의 주소가 된다. 즉 48비트 logical adress가 32비트 linear address로 전환되는 것이다. 여기서 다시 페이징을 통해 physical address로 번역함 페이징은 두 단계 페이징 기법을 (10비트 + 10 비트 + 12 비트offset)활용

인텔에서는 16 비트의 segment selector라는 것을 활용해 segmentation을 구현
인텔 프로세서에는 segmentation register라는 것이 있다. CS, DS, SS ES, FS, 등으로 각각 맡은 논리적인 세그먼트가 들어가는 레지스터들이다.
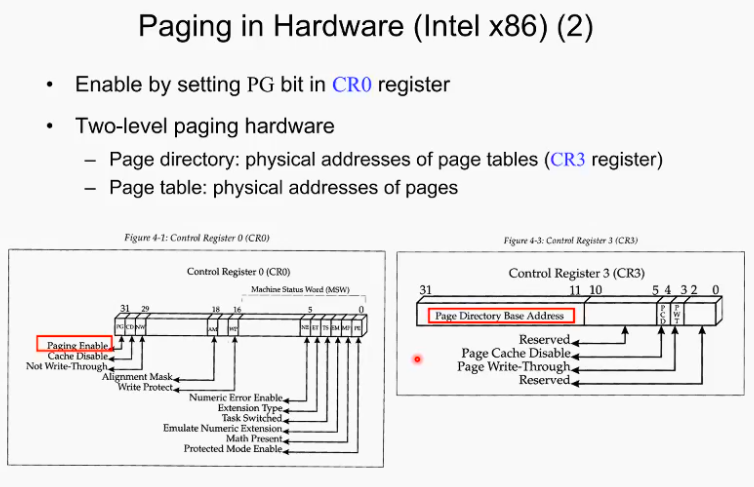
페이징을 돕기 위해 인텔 프로세서 안에 몇개의 레지스터가 있다. CRO~CR4 이중에 두개의 register(CR0, CR3)가 페이징에 관련되어 있다. 각 비트가 특정 의미를 지님.
CRO 의 맨 마지막 비트인 page bit가 1로 바뀌는 순간 CPU가 페이징을 지원하는 모드로 바뀐다. (그 전까지는 유저 모드였다가 )즉 페이징 enable이 된 하드웨어 시스템이 동작함.
CR3는 상위 20비트가 두단계 페이징 중 첫단계 페이지 테이블의 base addresss를 저장한다.
페이징을 지원하는 os는 모든 프로세스에 대해 각각 유니크한 페이지 테이블을 따로 지니고 있어야 한다. 그리고 각 프로세스는 자신의 PCB 안에 페이지 테이블이 어디에 있는지에 대한 정보가 필요하다.
스케줄이 되어 프로세스가 선택이 되면 첫번째 할일은 프로세스의 페이지 테이블이 어디에 있는지 알아야하는 것이다. 알게 되면 그 정보를 CR3의 상위 20비트에 전달하게 된다. 어디부터가 페이지 테이블인지 하드웨어적으로 인지를 하는 것.
PCB는 항상 이 정보를 지니고 있고 스케줄이 되면 그 정보를 CR3의 상위 20비트에 써줘야 한다.
Regular Paging

4kb page size를 쓰는 것을 regular paging이라고 하고 4mb로 쓰면 extended paging이라고 한다. 일반적으로 regular paging을 사용 함.
32비트 머신이기에 하위 12비트를 page offset으로 쓰고 상위 20비트를 10비트 10비트 나누어 첫번재 페이지 테이블의 index와 두번째 페이지 테이블의 index로 각각 사용된다.
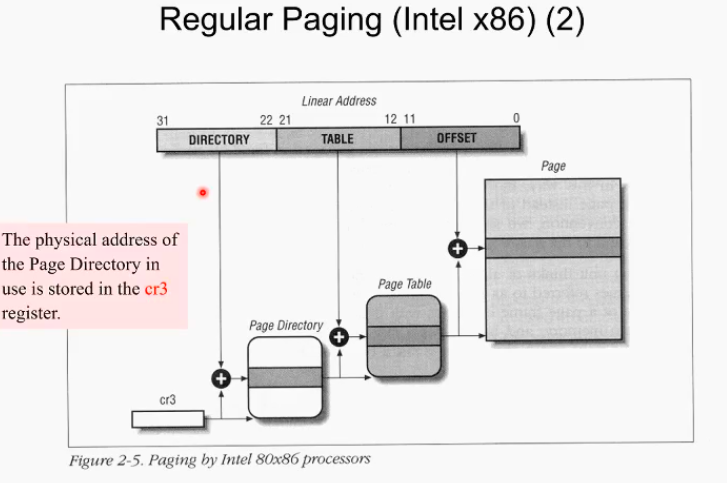
1단계 페이지 테이블을 page directory, 두번째 페이지 테이블을 그냥 page table이라고 함.
실제 페이지 디렉토리와 페이지 테이블 구현

page table의 엔트리 중 address offset정보 말고도 control bit들이 존재함. 구체적으로 control bit들이 각각 어떤 의미를 담고 어떻게 쓰이는지 알아보자.
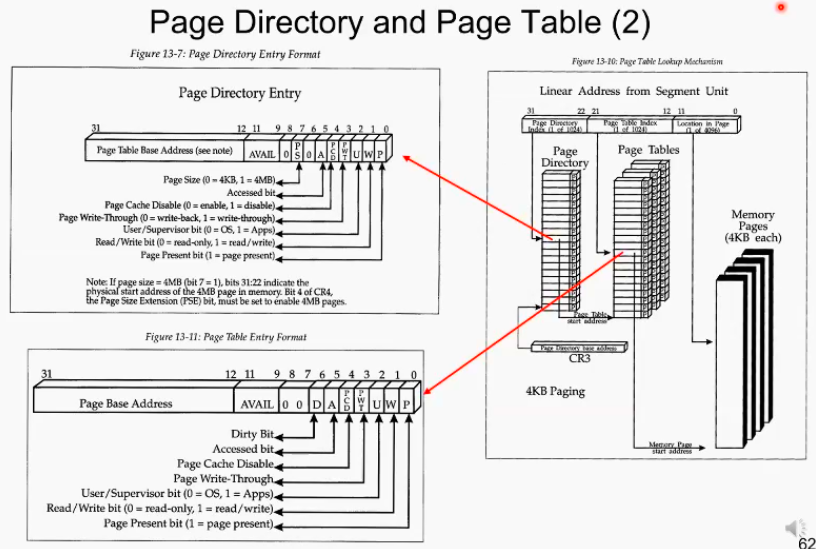
가상주소
- 하위 12비트는 page offset로 쓰이고 20비트가 쪼개져 10비트 10비트 씩 페이지 테이블에 대한 base address로 쓰인다.
페이지 디렉토리
- 페이지 디렉터리 의 entry는 1024개, 하나 entry당 4byte이기 때문에 전체 페이지 디렉토리의 크기는 4kb이다. 한 페이지의 크기도 4kb이므로 딱 한 페이지에 page directory가 들어간다.
즉 한 프로세스의 특정 페이지 1개가 해당 프로세스의 1단계 페이지들을 다 담고 있는 형태가 될 것이다
페이지 테이블
- 두번째 단계의 페이지 테이블은 모두 1024개가 있다.(첫번 째 단계의 페이지 디렉터리의 모든 1024개 entry가 base address를 가지므로 1024개)
즉 총 페이지 테이블(1024개) + 페이지 디렉토리(1개) 1025개가 존재.
<페이지 테이블(디렉토리) 엔트리의 추가적인 정보 비트들>
- page present bit: 현재의 페이지가 물리 메모리에 있나 없나를 나타냄, 1이면 물리메모리에 존재, 0이면 존재하지 않음.
- read/write bit: 0이면 읽기만, 1이면 읽기쓰기 다 가능
- user/supervisor bit : 0이면 os, 1이면 유저가 이 프로세스(페이지)의 주인임.
- Accessed bit: 1은 이 페이지가 physical ram에 올라와서 cpu가 한번이라도 access를 했다는 의미
- dirty bit: 이 페이지가 cpu에 의해 한번 수정이 되었다. update가 되었다는 정보 (만일 dirty bit가 1인 상태라면, 하드웨어적으로 업데이트가 안되었다는 의미이다. 교체상황에서 이런 정보를 활용한다)
그렇다면 이런 비트들의 setting, reset은 누가 하느냐? mmu(memory management unit)이라는 하드웨어가 이런 비트들을 setting해준다. + os , 아키텍처와 os가 협업을 해서 읽기도 하고 쓰기도 한다.
위같은 구조가 모든 아키텍쳐의 norm이다. 옛날에는 모든 것이 os, 소프트웨어가 했다. 발전하면서 아키텍쳐가 펌웨어적으로 자동적으로 setting하게 되었고, 지금은 os와 아키텍쳐가 협업하여 작동한다.
Extended Paging
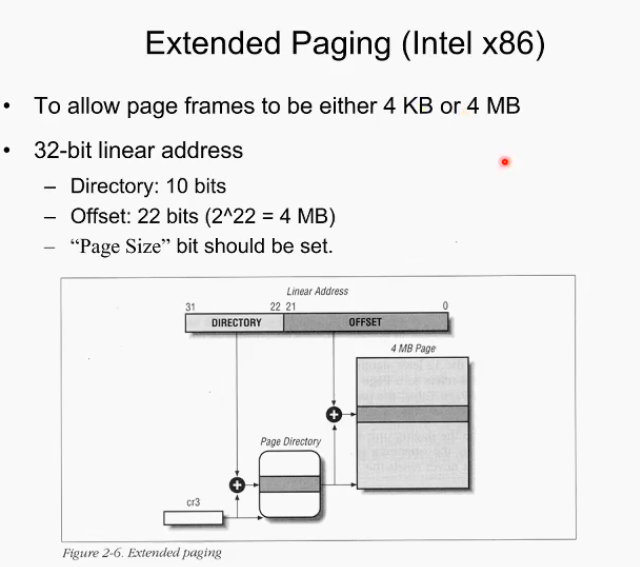
특정 상황에서는 아주 큰 페이지로 configure해서 쓰인다.
두단계 페이징-> 1단계 페이징으로 변경. 하위 10비트를 page directory, 그리고 상위 22비트를 모두 4MB page의 base address로 사용
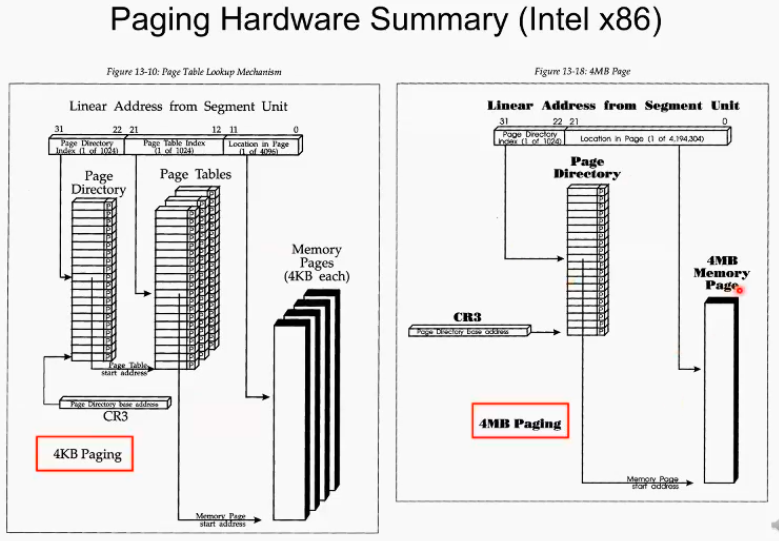
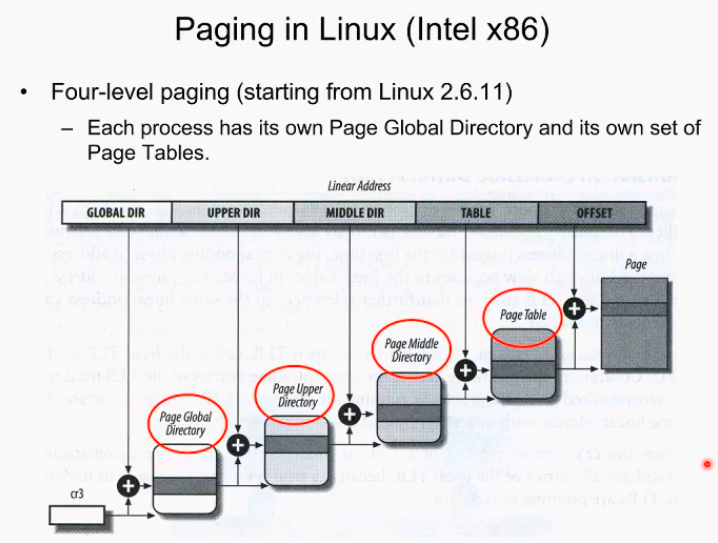
지금까지는 아키텍쳐적인 설명이었음 지금부터는 철저히 os관점에서의 paging을 설명.
리눅스, 커널의 메모리 management. 커널이 활용하는 자료구조중 Linear Address가 있는데 놀랍게도 네 단계의 paging의 하드웨어를 가정하고 소스가 쩌여있다. 왜 4단계로 가정하고 구현했을까?? - >portability 이식성떄문에
이미 지금도 아키텍쳐 32 비트 64비트, 그리고 아직 개발중인 128비트 등등 다양하다. 커널 개발자의 관점에서 memory management관점에서 하드웨어 호환을 최대한 허용하기 위한 설계라고 보면 되겠다. 아키텍쳐 independent한 소프트웨어를 개발하는 것이 좋을 것이고 그러다 보니 네 단계로 구현을 하면 꽤 오랜 기간동안 페이지에 관련된 커널소스의 수정은 없을것이다 라고 판단한 것임.
대부분 상황에서 네 개중 가운데 두개는 그냥 넘기고 처음과 마지막 페이지 테이블만 사용한다. 처음에 만들어놓고 안쓰는게 낫지 새로 확장하는게 더 힘듬.
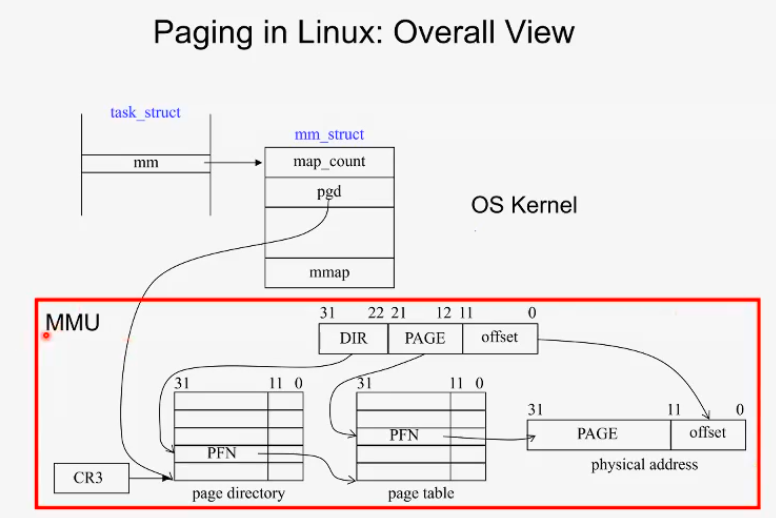
CPU 안에 들어가 있는 MMU, 실제 하드웨어이다. MMU는 하드웨어적으로 (os가 하는게 아님) address translation을 해준다 오에스와 하드웨어가 만나는 부분
CR3 register가 특정 address를 지니면 그 순간 부터 mmu하드웨어가 자동으로 인지하는 것이다. 아 이 주소부터 4kb가 일단계 페이징의 내용이구나. 그다음 거기서 하위 20bit address가 2단계 페이지 테이블의 base address구나 라고 인지한다. 이런 모든 access가 하드웨어적으로 동작시킨다.
mmu가 없을 적에는 모든 일련의 과정을 소프트웨어가 직접 했다. 하드웨어는 전광석화처럼 빠름. linear address만 주어지면( + 커널을 , 어디부터가 내 프로세스에 속하는 페이지 테이블인지 알고 있으면) 즉시 translation의 결과가 나오게 됨.
task struct의 mm 안에 pgd라는 자료구조가 있다. 이 pgd가 해당 프로세스가 가지고 있는 첫단계 page table의 base address인 것이다. 스케줄링이 이루어지면 pgd를 곧바로 cr3에 쓰게 되고 하드웨어는 즉시 로드하게 된다.
요약

프로세서는 항상 logical address를 사용한다. os+하드웨어가 physical address로 번역해준다.
댓글남기기