L9-Virtual Memory
Virtual Memory
표준 메모리 기법

우리가 콘솔에서 찍어서 나오는 주소는 linear address이다. 이미 컴파일되어 프로세스 이미지 layout에, 결정된 위치가 정해진 것.
내 linear adress상의 주소는 바뀌지 않음. 같은 운영체제와 아키텍쳐라면 항상 같은 주소이다. 우리가 짜는 process는 모두 이런식으로 돌아감.

가상 주소란.
프로세스가 generate한 (논리)주소 와 physical adress를 분리하자. 둘은 서로 independent한 존재 .
CPU가 수행하는 명령어는 가상주소를 기반으로 동작한다.
누군가는 virtual address를 physical address로 바꿔줘야한다. 운영체제와 하드웨어 기술이 합작을 해서 주소 변환을 해준다. 이런 기술을 VM Technique이라고 한다.
VM Technique

프로그램을 설계할때, 프로그래머는 철저하게 logical address만 고민할수 있게 하자가 원칙임.
장점:
- 멀티 프로세싱할 때 프로세스간 영향을 끼치지 않게끔 보호해줌. 프로세스들간 isolation 보장, 각 프로세스들이 각자의 독립적인 주소공간을 갖기 때문이다.
- 특정 시스템 코드, 라이브러리같은 거 를 쉽게 공유할 수 있어 효율성 제고
- 돌리는 프로그램들이 요구하는 physical memory가 실제 ram 사이즈를 초과해도 무리없이 돌리게끔 해준다.
앞서 배운 paging의 핵심: contiguous한 linear address를 non contiguous하게 physical space에 맵핑해서 돌릴 수 있다.
demand paging: 페이징 기법을 튜닝해서 발전된 방법. 페이징을 하긴 하되 필요할때 하자. VM의 코어 구현
runtime에 돌린 주소는 어짜피 linear(logical ) address이기 때문에 linear address를 포함하는 페이지 만을 피지컬 메모리에 담고만 있으면 해당 프로세스는 돌아갈 수 있다 라는 철학. 필요 없이 많은 페이지를 물리 메모리에 확보하지 말고 필요할때만 물리 메모리를 확보하자. paging의 demand버전.
아주 큰 프로세스의 이미지를 적은 페이지에 할당 할 수 있고, 여러개의 프로세스가 동시에 돌기 때문에 많은 프로세스들이 제한된 피지컬 메모리를 활용하는 상황이기에 필요할때만 페이지를 확보하면 제한된 피지컬 프레임을 효율적으로 활용 가능
이를 총칭해 virtual memory 기법이라고 한다. page 단위로 활용해 하드디스크로부터 필요한 부분만 swapping한다.
Demand Paging

프로세스가 특정 linear adress상에서 특정 address를 access할 때에만 페이지가 실제 physical frame에 있으면 된다. 논리적으로 있기만 하면 문제가 없다. 많은 페이지들을 미리 메모리상에 갖다 놓으면 좋겠지만, 안쓰는 페이지를 뭐하러 갖다놓냐. 꼭 필요할 떄만 갖다놓자.
page-level swapp : 스웝핑을 페이지 단위로, 필요한 것만 넣다 뺏다 하자.
운영체제 입장에서 봤을때 기존에는 메인 메모리가 전체 프로세스 내용을 담고 있는 permanent 공간이 아니고 현재 시점에서 내가 빈번히 쓰는 페이지만 담고 있는 캐시같은 공간으로 쓰자는 내용임
이 과정이 말은 쉽지만 간단치 않다. 캐쉬 유지를 해야하는데, miss되는 경우를 처리할때 일이 커진다. 원본이 storage에 있기 때문에 update 등등 오버헤드가 많은 작업이 지속된다.
캐쉬 공간이 항상 부족하다. 프로세스가 수행하려면 하드디스크의 해당 페이지를 가져와 physical ram 에 올려야되는데 공간이 부족하기 때문에 항상 다른 누군가의 페이지를 빼내야한다.(victimize)
얻는 장점은 적은 공간에 많은 프로세스가 돌릴 수 있다는 것이 강력하지만 이를 구현하기 위해서는 매우 어렵다.
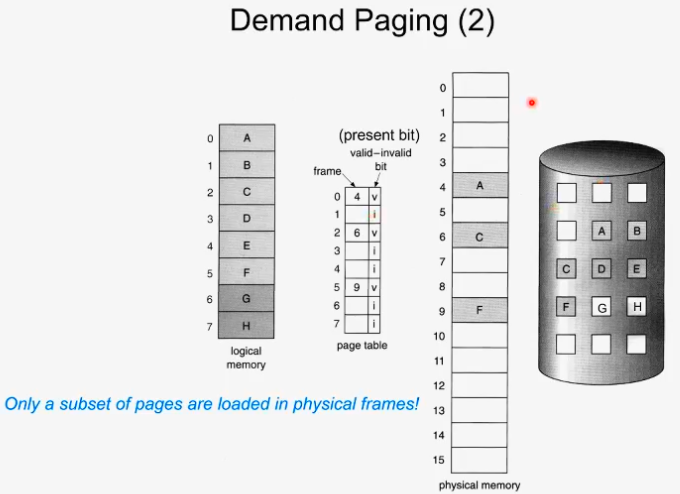
페이징을 쓰기 때문에 logical address와 physical address가 쪼개져 있다.
여덟 개의 페이지를 다 하드디스크에 가지고 있다.(원본) 여덟개의 페이지 중에 램에 3개 a,c,f만 올라와 있는 상황이다.
page table의 비트로 physical memory 에 해당 페이지가 올라와있는지 표시한다. v : valid, i: invalid. 즉 예를 들면, 4번 frame에 A라는 페이지가 올라와있으므로 page table에서 4, v 이런식으로 저장되어 있다.
기존의 페이징을 얘기할 떄에는 이거보다 좀 더 큰 개념이었다. 내 페이지가 physical한 frame이 있는데 여기저기 흩어져 있을 수 있다 이 정도 개념이다. 근데 demand paging은 내 프로세스에 속하는 모든 페이지가 이 램에 있을 필요가 없다는 것이고 이거를 관리하자는 뜻이다. 부분적인 페이지만 로딩이 된다는 더 나아간 개념.

os와 architecture는 demanding page를 구현하기 위해 여러가지 현재상태의 정보들을 서로 잘 전달해야한다. 이를 위해 결국은, 모든 페이지 테이블에 정보를 담아야한다. page table entry가 있고 이게 valid한지 표현함. 실제로는 훨씬 많은 정보들이 필요하다. 이거는 개념적인 설명
만일 프로세스가 해당 테이블을 access했는데 present bit 가 invalid라면 이것을 page fault라고 하는 것이다. 항상 runtime에 cpu는 address translation(mmu)를 하는데 어느 순간은 hit, 어느 순간에는 page fault가 되는 것이다.
present 비트가 1이면 현재 페이지가 프레임 확보를 받은 것이고 0이면 현재 페이지가 frame 확보를 못하고 있다는 의미.
page fault는 생각보다 많이 일어남. 대표적인 exception 중 하나. cpu가 linear address를 만들었고 mmu가 봤는데 없다 그러면 exception이 발생하고 cpu가 커널 모드로 모드 체인지를 한다. 그러고 커널 모드에서 exception handler가 동작한다. page fault exception handler임.
fault가 발생하면 매우 엄청난 오버헤드가 발생한다.

demanding paging 기법은 페이지 fault를 피할 수가 없다.
페이지 fault란??
physical 한 프레임에 없는 페이지에 access할때 발생하는 상황. 빈번하게 fault 상황이 발생하는데 fault가 발생하면 해당 페이지를 storage에서 가지고 들어와 어딘가에 저장을 하고 page table을 업데이트하고 수정해야한다. 이게 상당히 복잡한 과정이다. runtime에 어떤 process가 도는데 mmu가 page fault를 인식하면 커널 모드로 모드 체인지가 일어나고 커널 방에서 exception handler page fault handler를 돌리고 해당 프로세스가 원하는 페이지를 램에 확보를 한 다음에 페이지 테이블을 업데이트하고 다시 유저모드로 가서 페이지 프로세스에게 수행을 넘겨주는 것이다. 이 과정이 page fault handling 과정의 큰 흐름이다.
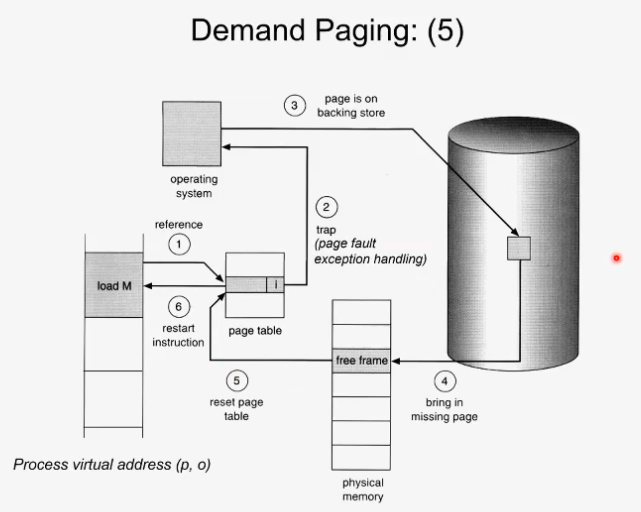
page fault exception handling의 과정을 예시 그림으로 나타낸 슬라이드다.
먼저 load M 이라는 수행을 포함한 PC가 access를 하는데 mmu가 page table을 들어봤을때 invalid함을 알게 되었다. mmu가 하드웨어적으로 exception을 발생시킨다 (page fault exception)
그러면 프로세스가 멈추고 커널 모드로 모드 체인지 한다. 커널은 하드 디스크의 어딘가에 있는 원래 이 프로세스에 속한 이미지를 찾아내야한다. 찾아서 가져와서 page table에 넣는다.
page table에 entry가 하드 디스크/메모리에 내 페이지가 어디에있다는 정보를 지니고 있다. i가 1이 아닌 경우는 frame number을 지니지만 0인 경우에는 하드디스크의 주소를 가지고 있다.
하드디스크로부터 가져오면 ram에 빈 공간을 찾아낸다. 빈 공간을 찾아내고 나서는 램에 놓고 page table을 update한다. i가 1로 바뀌고 하드디스크의 주소가 아닌 pyhsical frame의 인덱스로 바뀐다.
그제서야 다시 유저모드로 가서 아까 멈춘 instruction, process를 다시 실행한다.
아까 빈 프레임에 가져다 놓는것이 매우 어려운 문제이다. 상식적으로 아주 특이한 케이스(초기화한 케이스) 가 아니고서는 run time에 빈 프레임이 존재하는 경우가 거의 없다. 놀고 있는 빈 프레임이 현실적으로 없음. 이게 문제를 어렵게 만듬.
누군가 희생을 시켜야하는데(victimize) 누구를 희생시켜야하는가. 바로 다음에 쓰일 프레임을 희생시킨다면 비효율적일 것이다. 전지적 관점에서 지울 페이지가 앞으로 안 쓸 페이지가 확실하면 좋은데 이걸 알기가 어렵다. 그래서 페이지 교체 정책을 잘 세워야한다.
어떻게 해야 page fault 자체를 줄일까도 중요한 문제임.

개념은 좋은데 현실적으로 유의미한 퍼포먼스를 낼까라는 비관적인 생각이 들 것이다.
하지만 virtual memory기법은 3-40년동안 잘 쓰고 있고 거의 표준일 정도로 검증된 기술이다.
왜 가상 메모리 기법이 효율적일까? → locality때문 demanding paging 이 효율적으로 동작할 수 있는 근거
보통 코드는 반복문을 많이 쓴다. array등 을 활용. 현실적으로 다루는 코드는 대부분의 코드는 지역성이라는 특징을 지닌다. 쭉 진행하다 어느 코드를 많이 사용하다가 점프를 하거나 다음으로 이동한다. time 관점이나 공간 관점으로 봤을때 지역적으로 돈다. temporal locality, spatial locality. 시간적으로 그룹화, 코드상의 공간적으로도 지역화가 되어있다.
이 얘기는 paging이라는 관점에서 locality를 담고 있는 page의 frame이 확보가 되면 이 프로세스는 꽤 오랫동안 page fault 없이 그걸 쓸 확률이 높다는 이야기다. 이런 특징 때문에 real 상황에서 page fault가 생각 외로 많이 나지 않는다. 이론적으로는 갸우뚱 하지만 현실에서는 page fault 가 나올 확률이 다르다(상황따라 다르긴 하지만)
즉 locality라는 프로세스의 특성이 demanding paging 기법의 효율성을 보장한다.
지금도 page 교체 기법, 등은 아직도 연구되고 있다. optimal한 방법은 절대 없음. 그나마 다행인 것이 locality가 존재하기 때문에 이게 먹히는 것이다.
for loop를 아예 안쓰겟다-> page fault가 날 확률이 더 높아진다.

예시: 페이지 FAULT가 얼마나 퍼포먼스 관점에서 해악이냐?
page fault가 발생하면 exception이다. 모드 스위칭을 해야되는데 이거 자체도 오버헤드가 발생.
fault가 된 없는 페이지를 storage에서 찾아서 이거를 load하는 시간이 엄청 많이 걸린다. 갖고 와서 다시 뒷정리하고 유저모드로 가는 거 자체도 오버헤드
수를 가지고 간단히 계산을 한 극단적인 상황의 예시.
cpu가 ram을 access하는 시간: 100ns
disk acess time: 25ms (1ms = 백만 ns)
page fault의 확률이 p라고 했을 때,
cpu가 address만들었을때 실제로 수행해야할 시간 EAT(effective access time) : 100(1-p) + 25000000* p 이다.
만일 virtual memory를 안쓸 때 대비 10% 정도의 성능 감소만을 감수하겠다라고 하면, 도대체 얼마정도의 page fault rate이 보장되어야하는가 역계산해보면 p가 0.0000004보다 작아야한다… (250만번중 한번)

page fault가 발생하면 하드디스크에서 찾아 가져오면 된다.
그러나 physical memory에 사용 가능한 frame이 없거나 아주 적은 상황이 존재하는데 매우 큰 문제임.
정상적인 시스템이라면 프로세스가 수천개 돌아가는데, 당연히 물리메모리에 남는 빈 프레임이 적을 수 밖에 없다.
fault가 나고, 프레임이 부족한 상황에서는 결국 교체를 해야한다.
fault가 났을 때, 가져올 페이지를 위한 frame 확보를 하기 위해서는 기존 프로세스의 프레임을 뺴고 넣을 수 밖에 없다. 누군가는 희생이 되어야 하는데 이러한 내용을 기술적으로 page replacement policy라고 한다.
현재 ram에 어떤 페이지를 빼고서 내꺼를 집어 넣을까? replacement, 교체. 피할 수 없는 상황.
운영체제는 이 정책을 잘 만들어 보여야한다. 페이지 fault의 횟수를 줄이는 방향으로 정책을 세워야 함. overall number of page fault를 최소화한다. 하지만 이게 쉽지만은 않음. 아직 발생하지 않는 미래 일이기에 정확한 정답을 예측할 수 없다. 이론적으로 완벽한 해답은 없음.
교체를 할 적에, 어떤 페이지는 그냥 교체하면 되지만 어떤 페이지는 그냥 단순히 교체후 버릴 수 없다. 예를 들어, 어떤 페이지가 수정이 되었고 수정된 데이터를 하드디스크에 flush해야된다면,(원본에 update,dirty헤야하는 상황) 이 시점에 해당 페이지를 교체한다면 update가 안될 것이다. 이 같이 이런저런 constraints가 존재한다.
가상 메모리에서는 페이지 교체 정책이 이처럼 중요한 이슈이다.
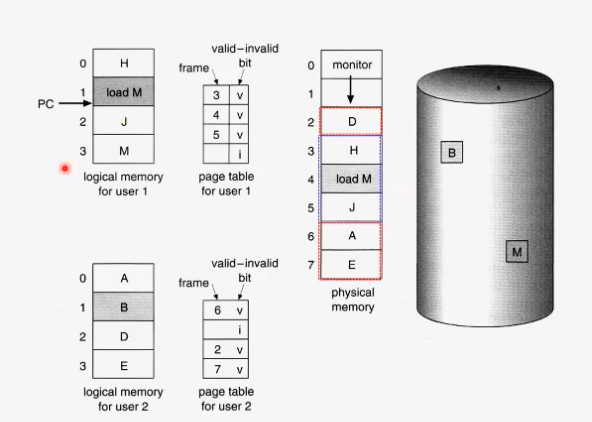
위 그림은 교체 정책이 필요한 상황의 예이다.
유저들 안의 프로세스는 네개의 페이지로 구성되어있고 페이지는 logical adress이다. pysical memory에는 프레임이 여덟개 뿐이고 두개의 페이지를 os가 쓰고 있고 유저가 쓸 수 있는 것은 6개 프레임 뿐이다. 현재 유저1의 맵핑은 유저1의 page table로 알 수 있는데 네 개의 페이지 중 위의 3개만 v이기 때문에 3개만 physical memory에 들어가 있다는 것을 알 수 있다. 또한 frame칸의 숫자로 logical memory의 0인덱스 페이지는 페이지 테이블의 0번째 인덱스로 맵핑 되며 이 안에 frame값이 3이기에 다시 physical memory인덱스의 3번째에 해당 페이지가 할당되었음을 알 수 있다.
현재 상황은, 프로세스들이 요구하는 전체 페이지 개수보다 피지컬 프레임의 갯수가 작은 것이다. 이런 상황이 비일비재하게 발생한다. 이러한 상황에서 프로세스1 이 할당되어 수행중인데 (Program Counter가 가리키는것) load M을 수행하는 중이다. m을 loading해야되는데 physical memory가 꽉 차있기 때문에 누군가 어떤 프레임은 교체되어야만 한다. 이것이 page fault고 os가 이를 핸들링 해줘야한다.
Page Replacement

교체 정책에 대해 알아보자.
교체 정책의 큰 scheme은 간단함. fault가 발생한 상황에서 빈 프레임이 없는 상황. 이런 상황에서 현재 프로세스가 원하는 페이지를 하드디스크에서 찾아서 가지고 들어와야한다. replacement 정책을 가동시켜 희생 victim frame을 선택해야한다. 정해졌다면, hard disk의 페이지를 victimize한 프레임에 loading하고, 현재 페이지 테이블의 내용이 update가 되었으니 적절히 present bit를 valid로 바꾸고 해당 프레임 번호도 업데이트 해준다.
여기까지가 exception handler가 커널 모드에서 수행하는 것이다. 이후는 유저모드로 모드 체인지하고 아까 page fault때문에 stall된 위치로 돌아가 다시 시작이된다.
위의 시나리오가 교과서의 시나리오다. 현실에서는 약간 다르게 돌아간다. page fault가 빈번히 발생하는데 페이지 fault가 발생할 때마다 실시간으로 빈프레임을 찾아 확보해 넣어야한느데 빈 프레임도 없으니, 교체정책을 사용해 다시 교체하는. 이런 일련의 과정이 너무 오버헤드가 크다. 즉 빈프레임을 필요할때 마다 확보를 한다는 자체가 상당히 부담스러운 상황인 것이다.
실제에서 os는 항상 일정량의 빈 프레임을 확보해놓는다. 시스템에 10개, 20개 predefined된 physical 빈 프레임을 항상 확보를 하고 있다. 이 상황에서 page fault가 발생하면 빈 프레임 중 하나를 그냥 줘버린다.
os가 백그라운드에서 널럴한 시간에 항상 현 상황을 모니터링한다. 예를 들어 빈 프레임 개수가 10개 이하로 떨어진다. 그때 바로 미리 확보해 놓는다. 즉 os 판단 하에 적절한 양의 physical frame을 확보해놓는 작업을 background에서 실행하고 있다.
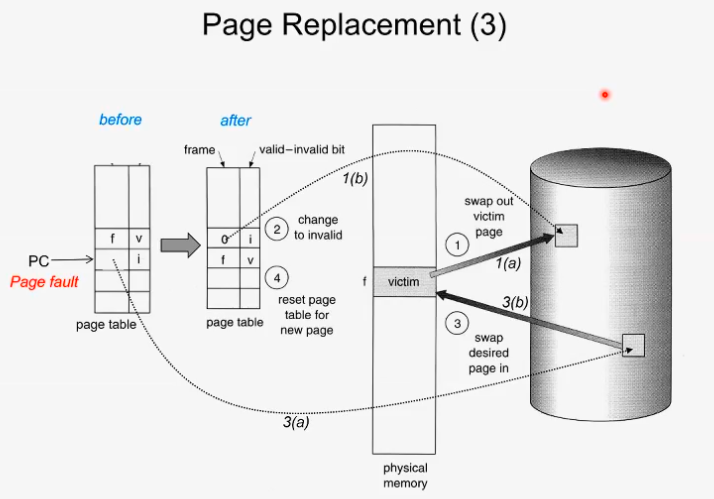
이 그림을 통해서 replacement 정책을 좀 더 설명해보자.
동그라미 안의 숫자를 따라가면서 봐야함. 어떤 프로세스가 돌고 있는 상황에서, 페이지 폴트가 발생하기 전의 페이지 테이블의 상황이 before이고 page fault handling 이후, 커널이 다시 유저모드로 돌아간 상황이 after이다.
pc에서 페이지를 접근하려 했지만 해당 페이지 테이블에 bit 가 i이기 때문에 없음을 확인, 즉 fault가 발생한다.
커널 모드로 들어가서 PC가 속한 page를 physical memory에 올려놓고 돌아가야한다. 커널이 보았는데 현재 physical memory에 빈 프레임이 없는 상황이다.
그래서 커널이 victim frame을 확정짓는다. 위의 예시에서는 현 프로세스의 PC 하나 위 인덱스에 있는 f, v가 victime으로 당첨되었다. 커널이 해당 페이지를 victim으로 결정했다면 victim frame을 하드 디스크로 빼 내야한다, 이때 만일 해당 frame이 dirty하다면 먼저 update를 수행해준다. victim을 뺴 내면서 위치를 기억해야하기 때문에 physical memory의 f 인덱스를 뺸 그 위치를 page table의 f인덱스에 기록을 해준다. 또한 valid를 invalid으로 바꿔준다.
그 다음으로는 내가 원하는 페이지를 가지고 와서 찾아서 f번째 frame에 집어 넣어야한다. 페이지 테이블에서, present bit가 i인 그 곳의 entry에 storage에서 찾을 위치가 담겨져 있으니까 storage에서 찾아서 physicial memory에 load해준다. 이게 페이지 레이블의 swapp- in이 되는 것이다.
이후 업데이트가 되어야한다. physical memory에 할당이 되었으므로 i가 아니라 v로 바꿔주고, f번째 physical memory entry에 존재하므로 f,로 바꿔줌,
replacement 정책이 실제 벌어지는 일을 시각적으로 설명하는 슬라이드다.
그렇다면 커널이 어떻게 victim frame을 찾을까?
커널 관점에서는 기준이 있어야한다. 어떤 페이지를 내가 희생양으로 삼아야 할까?
best victim은 page fault rate을 최소로 줄일 수 있는 녀석이고 이를 선택하는 것이 가장 좋은 알고리즘일 것이다.
예를 들면 만일 100개의 프레임이 있고 다 차있는데 15번쨰를 쫓게 되면 전체 10분동안 page fault가 제일 적다. 이녀석을 victim해야함. 즉 만에 하나 앞으로 절대 안쓰일거 같은 페이지를 victimize해야한다.(이론적으로는 완벽하지만 “절대 안쓰일” 페이지를 찾는 것이 불가능함)
‘절대 안쓰일’과 비슷한 정도의 행동양식을 보이는 페이지를 찾자.
Page Replacement Algorithms

알고리즘의 최종 목적은 전체 page fault의 개수를 최소화 하는 것이다.
알고리즘의 평가 : 알고리즘에 대해 일련의 input stream을 넣어, program counter 기준 몇번째 페이지에 access하는지 log를 만듬. 알고리즘에 대해 그러한 log를 적용시켰을때 몇개의 page fault를 발생시키는가를 측정한다.
Optimal

가장 최적화된 알고리즘.
미래에 어떤 sequence가 올지 안다는 가정 하에 만드는 알고리즘이기에 optimal은 현실적으로 불가능하다. 현실적인 알고리즘을 평가하기 위한 기준으로 쓰인다.
시간 0 지점에서 page frame에 a,b,c,d,가 할당된 상태로 시작.
시간 1에서 4까지 page request들에 따르면 모두 hit로 문제 없음.
시간 5에서 e page request에서 문제 발생. page fault발생. 현재시점에서 가장 뒤에 refer가 될 페이지는 d이므로 d가 vicitimize됨.
10번까지 단 두번의 page fault를 발생시킴.
위 알고리즘을 기본으로 다음에 등장할 현실적 알고리즘을 비교해보자.
FIFO
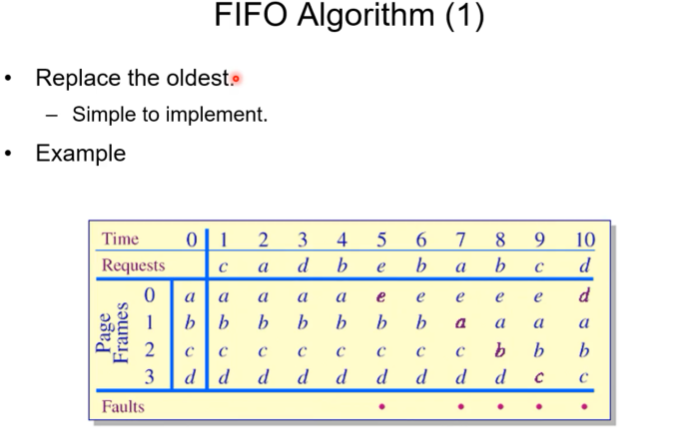
FIFO 알고리즘
친숙한 FIFO개념으로 구현. 먼저 들어온 순서대로 victimize함.
예시 sequence에 적용시켜보면 총 5번의 page fault가 발생한다.

장점: 구현도 간단하고 이해하기 쉬움.
약점: -> Belady`s Anomaly
만일 어떤 프로세스에게 프레임의 개수를 더 할당해주면 상식적으로 page fault가 적게 발생할 것이라 기대할 수 있다. 하지만 belady`s anomaly에 의하면 어떤 replacement 알고리즘은 꼭 그렇지만은 않다는 것이다. 즉 많은 프레임을 줘도 page fault가 줄이는 것이 gurantee가 되지 않는 알고리즘이 존재.
결론적으로 FIFO 알고리즘도 Belady`s anomaly를 지닌다. 위의 그림이 그 예시.
페이지 프레임을 더 줬음에도 fault는 늘어남.
LRU

현재 시점에서 가장 오랫동안 쓰이지 않은 프레임을 victimize하겠다.
오늘날 학계의 정설. 가장 유명하고 많이 쓰이는 알고리즘. 많은 운영체제에서 이런저런 변형을 해서 쓰이고 있음.

LRU에도 문제가 많음.
커널에 코드화가 되서 구현이되어야 하는데 가장 큰 이슈가, 현재시점에서 가장 과거에 쓰인 페이지를 어떻게, 최소 오버헤드로 식별해내는가가 이슈이다. 즉 이전 페이지에 대한 기록을 해야함.
두 가지 방법이 있따. 하나는 counter라는 정보를 활용하는 것이고, 또하나는 stack 자료구조를 활용한다.
counter 기법을 말하자면, cpu가 memory를 access할 때 마다 access 시간을 기록하는 것이다. 카운터를 두고 카운터가 특정 페이지에 access한 시간을 기록한다. 타임 값이 가장 작은 페이지를 victimize한다.
또다른 기법은 stack을 활용한다. 최근에 access한 페이지를 top으로 놓는다. 어떤 페이지가 access된다면 그 페이지를 stack의 top으로 가져옴.
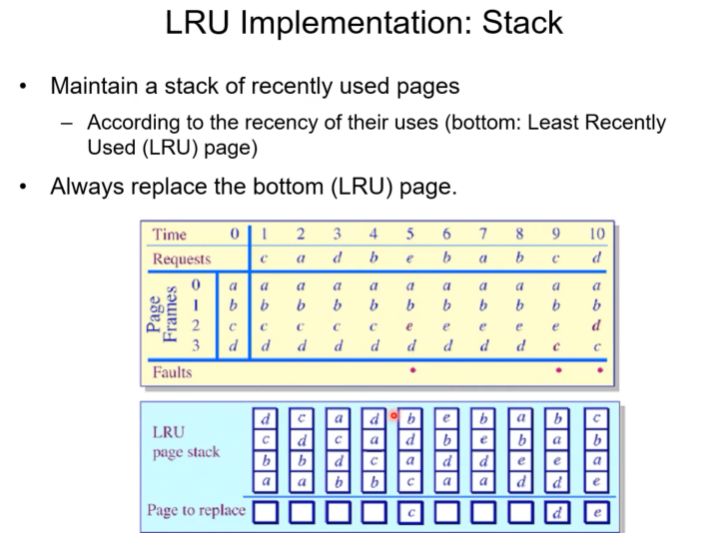
위 그림은 LRU- stack의 예시다. 가장 아래에서 뽑은 페이지가 victimize의 대상임.
개념은 간단하지만 구현이 어려울 수 있다.
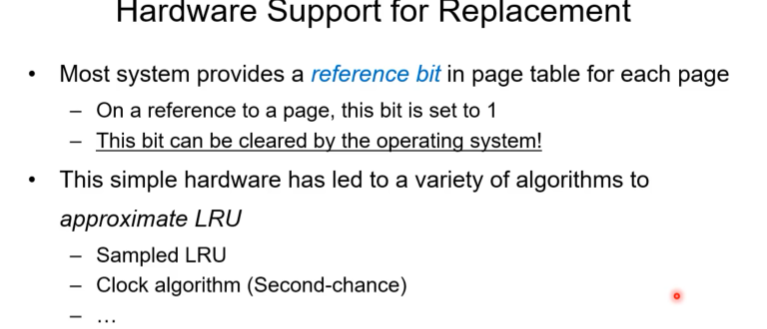
카운터 베이스의 알고리즘은 하드웨어의 서포트를 받아 구현한다.
페이지 테이블에 reference bit가 존재. 해당 페이지를 refer한다면 그 비트를 1로 바꿈. 어떤 페이지가 쓰이기 때문에 페이지 교체 관점에서는 해당 페이지를 victimize하는게 좋은 아이디어는 아니다. 아무래도 해당 비트가 0인 페이지를 victimize하는게 상식적으로 맞는 교체일 것이다.
reference bit는 운영체제가 다시 0으로 교체할 수 있음. 이런 기법을 써서 LRU를 한다. 앞서 말한 스택이나 time을 측정하는 것은 정확하게 하려면 오버헤드가 크기 때문에 현실적인 방법은 approximation을 한다. LRU를 정교하게 하는 것보다 비슷한 느낌이 나게 구현하되 LRU principle을 따를려고 하는 것이다.
이걸 approximate LRU라고 한다.
현실적으로 많은 os가 이 approximate LRU를 사용한다.
LRU Approximation : Sampled LRU
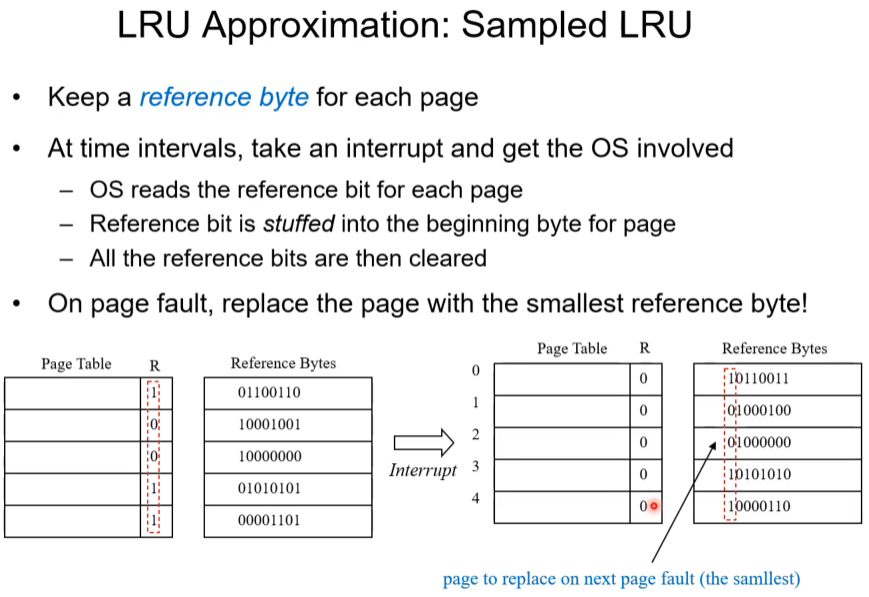
이 기법의 특징은 reference byte와 R비트를 모든 페이지에 추가한다. r비트가 1이면 페이지가 한번이라도 참고가 된 것이고 0이면 페이지가 한번도 참고가 안되었다는 의미이다.
이 상황에서 주기적으로 R 비트를 검사한다. 모든 페이지의 R비트 를 검사해서 R 비트를 그대로 Refernece byte 의 앞에(Most siginificant bit에) 붙이는 것이다. 오른 쪽은 Reference byte가 적용된 후이다. 그러고 나서 R비트는 reset하는 것이다. 이같은 과정을 반복한다.
Page fault가 발생했을 적에 vicitimize 대상을 찾는 solution의 답은 reference byte의 값이 가장 작은 것이다(값이 작을 수록 쓰인 지 오래되었다는 의미) . 일정 기간의 인터벌 상황에서 LRU를 판단한다는 것이다.
LRU Approximation clock Algoritm

또다른 LRU approximation: clock algorithm
똑같이 R bit를 추가하고 LRU clock을 두고 fifo를 한다.
가장 오래전에 들어 왔어도 메모리에 있는 상황에서 reference가 되었다면 해당 페이지에게는 한번의 기회를 더 주겠다는 것이다. 언제 까지 기회를 주냐? clock이 한바뀌 돌 때 까지 reference 가 안되면 victimize하고 된다면 victimize하지 않고 한번 더 기회를 준다.
Page 가 refer 되면 reference bit이 1이 된다. 페이지 fault가 발생하면 clock이 돌아가면서 스캔을 한다. 스캔을 하면서 r bit가 0인 페이지를 victimize로 고르는데 r bit가 0인 페이지가 나올때 까지 진행하고 나온다면 해당 페이지를 고른다.
clock scan이 진행하는 과정에서 r bit를 0으로 모두 reset한다.
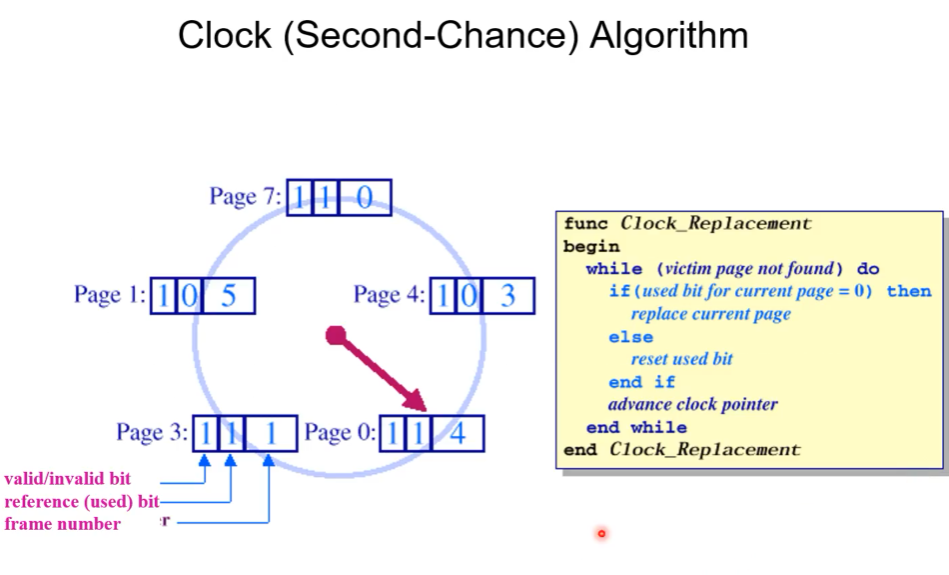
현재 프로세스에 다섯개의 페이지가 있고 각각의 박스가 페이지 테이블의 엔트리이다. 두개의 FLAG가 앞의 두 비트고 마지막 박스가 프레임 넘버이다. 첫번째 비트는 PRESENT BIT이고, 두번째 비트가 REFERENCE BIT(R) 비트이다. 이런 상황에서 CLOCK ALGORITHM의 동작을 보자
현재 화살표가 시계방향으로 스캔함을 의미한다. 빈 프레임 하나를 찾아 쫓아야한다. 스캔을 하면서 R비트가 1이면 해당 비트를 0으로 바꿔주고 스킵한다. 한바퀴 돌아서 보았을때 그때도 0이라면 그때 VICTIMIZE하겠단 의미이다. 페이지가 ACTIVE하다면 (한번이라도 쓰이면) CLOCK이 돌아가는 와중에 다시 R비트가 1이될 것이다.

전의 슬라이드는 BASELINE CLOCK ALGORITM이었으며 솔라리스의 변형된 TWO HANDED CLOCK ALGORITHM이라는 기법도 존재한다.
클락 핸들을 두개를 쓰는 것이다. 클락 알고리즘과 유사하게 시계방향으로 두 핸드가 같이 돈다. FRONT END와 BACKEND가 있으며 그 간격은 항상 고정이다. 간격은 작게 혹은 크게 세팅 가능. PAGE FAULT가 발생할 떄 VICTIMIZE 절차는 이러하다.
FRONTEND는 스캔하면서 모든 R BIT를 0으로 RESET한다. 그다음 뒤따라 가는 BACKEND 핸드는 R BIT가 0인 녀석을 검사한다. 이때 프론트와 백의 간격 사이에 만일 해당 페이지가 ACCESS되게 된다면 그때 R비트는 1로 다시 바뀌므로 안쓰이는 페이지만 0으로 남게 되어, BACKEND에 의해 검출당할 것이다.
솔라리스 OS는 추가적으로 LOTSFREE라는 변수가 존재한다. REAL OS는 미리 FREE PAGE 를 확보해 놓는다고 했는데 이런 미리 확보하는 작업을 할것이냐 말 것이냐를 결정하는 기준을 담고있는 숫자이다. 만일 FREE FRAME의 갯수가 LOTSFREE보다 적다면, PAGE OUT이라고 하는 커널 스레드가 WAIT하게 되어 FREE FRAME을 일정량 이상 확보하게 된다.
간격을 넓히고 줄이는 것을 세팅 가능. 간격이 적어지면 거의 모든 페이지를 FREE하겠다는 급박하다는 의미이며 넓으면 널럴한 상황을 의미.
Counting Algorithm

counting 계열의 replacement 정책.
카운터를 두고 해당 페이지가 참조가 되면 카운터 값을 increment 시킨다. page fault가 발생시켰을때 victimize의 기준은 바로 카운터 값이 된다. 카운터 값이 가장 작은 페이지를 희생시키다는 것이 LFU, 반대의 개념은 MFU이다. 카운터 값이 큰 것을 희생시키겠다는 의미.
LFU는 직관적으로 상식적이며 이해된는데 MFU는 의문이다.
MFU도 나름 논리가 있다, 프로그램 초기 부분은 initialize하는 과정이 많고 메모리 참조를 많이 하므로 카운터 값이 증가되는 상황이 많다. 하지만 프로그램이 진행됨에 따라 프로그램의 초기화 부분은 더이상 쓰이지 않게 되지만 카운터 값이 여전히 충분히 커서, 쓰이지 않음에도 불구하고 victimize되지 않는 상황이 발생될 수 있다. 이를 해결하기 위해 MFU를 적용하게 된다.
즉 프로그램 후반부에는 오히려 카운터 값이 큰 페이지들이 더이상 access하지 않을 확률이 늘어나므로 MFU 정책을 쓰는 것이다.
Allocation of Frames

프로세스에게 몇개의 페이지 프레임을 할당할까? 에 관련된 이슈.
동시에 여러개 프로세스가 돌고 있고 메인메모리의 프레임들이 적절히 프로세스들에게 배분, 할당 될 것이다. 어떤 프로세스에 몇개의 프레임을 할당하고, page fault상황에서 어떤 프로세스의 프레임을 victimize 할 것인가
이 같은 이슈를 frame allocation이라 칭한다.
가상 메모리를 사용하는 경우, 논리적으로 프로세스의 모든 이미지가 피지컬 프레임에 할당이 안되고 오직 몇몇 페이지가 프레임에 로딩이되면 동작할 수 있다가 demanding page의 기본적인 원리이다. 그럼에도 불구하고 현실에서 어떤 프로세스가 진행하기 위해서는 최소한의 필수적인 프레임 갯수가 있다.
프로세스에 몇 개의 프레임을 할당할 것인가에 대해 크게 두개 정책이 존재한다.
Local Replacement: 어떤 프로세스가 일정량의 프레임을 고정으로 할당 받고 고정으로 할당받은 페이지들 내에서 자체적으로 해결하는 것이다. page fault가 발생하게 되면 내가 가진 페이지 용량 내에서 replace 한다.
global replacement: 어떤 프로세스가 page fault가 발생시킨다면 빈 프레임을 할당 받을 때 다른 프로세스들에 할당된 프레임도 뺏어 올 수 있는 agressive한 정책. 가변적으로 프로세스당 할당된 페이지 수를 관리하고 프로세스의 우선순위에 따른 여러가지 글로벌 정책을 적용한다.
Local Replacement(Fixed Allocation)

Equal Alloaction: 프로세스의 크기 차이 없이 무조건 n빵하는 것이다.
proportional alloacation: 프로세스마다 이미지의 크기가 다를 수 있으니 프로세스의 이미지 크기에 비례에 할당한다
Global Replacement (Priority Allocation)

Priority alloaction방법.
프로세스의 위급도에 따라 다른 프로세스가 지닌 프레임까지 쓸 수 있는 정책
만일 어떤 프로세스가 page fault를 발생시키면 우선 자체 보유한 프레임 내에서 해결을 하려 하고, 여차하면 다른 프로세스가 지닌 프레임도 뺏어온다. 구현하는 여러가지 방법이 또 있음.
이를 구현하는 방법에 앞서 이해해야할 demanding paging 기법의 현상들이 있음.

Thrashing 현상.
Thrashing의 사전적인 의미는 뭔가가 바쁘게 움직인다는 뜻이다.
운영체제에서의 정의는 physical frame이 부족한 상황에서 여러개 프로세스가 physical frame을 공유하고 있고 워낙 빈 프레임이 적기 때문에 실제 프로세스를 수행하기보다는, 너무 빈번하게 page fault가 발생해서 page fault를 처리하는데 너무 많은 cpu 시간을 쓰는 현상을 thrashing 상황이라고 한다.
기본적으로 운영체제는 시스템의 through put을 높여야한다. 즉 단일 시간내에 많은 프로세스 처리를 해야함.
기본적 철학은 kernel관점에서 cpu의 utilization을 보는 것이다. 현재 시피유가 얼마나 많이 쓰이나, cpu 사용도가 낮으면 더 많은 갯수의 프로세스를 로드해서 cpu에게 수행시킨다. 운영체제는 어느 순간에 멀티 프로그래밍의 정도를 가급적이면 많이 가질려고 하는 것이다.
예를들어, 어느 순간 cpu의 활용도가 낮아, 더 많은 프로세스를 램에 올려놓는다. 의도는 시피유 활용도를 높이기 위함이었는데 막상 올리고 보니 오히려 cpu 활용도가 더 낮아지는 상황이 발생한다. 그이유는 할일이 없어서 낮은게 아니라 너무 많은 프로세스가 많은 양의 physical frame을 요구하고 있고, 이상황에서 너무 빈번한 page fault가 발생하는 것이다. 즉 너무 메모리의 사용이 dense한 것이다. 이런 현상을 thrashing이라 한다.
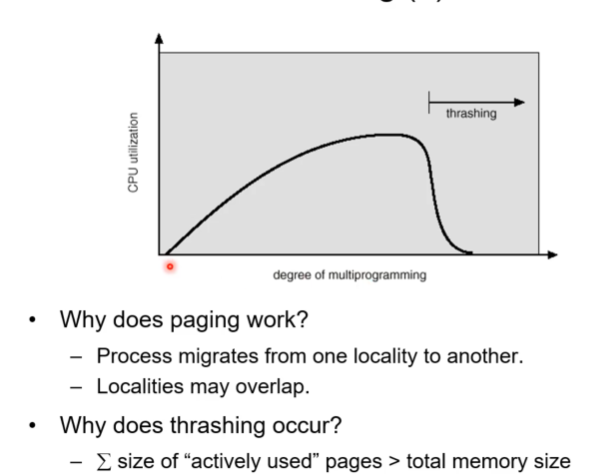
thrashing 현상을 그래프로 나타난다. 프로세스의 수가 증가함에 따라 cpu활용도가 올라가다 포화상태를 넘어서면 thrashing이 발생되며, 오히려 활용도가 떨어지는 그림이다. 이전 슬라이드에서 말했다시피 만일 thrashing 상황을 인지하지 못한다면, cpu활용도가 떨어지므로 더 많은 프로그램을 ram에 올리게 되고 이는 상황을 더욱 악화시키게 되어 악의 늪으로 빠지게된다.
가상 메모리 구현과 실행시킬적에 신경써야 할 부분이며 thrashing을 지양해야한다. 프로세스 수 조절, 프로세스에 할당하는 프레임 수도 조절해야함.
다시 원론으로 돌아가서 page 기법이 왜 잘 동작할까?? 프로세스의 locality 특성 때문에 잘 돌아가는 것이다. spatial , time locality가 있어 특정 부분이 많이 쓰이기 때문에 그 부분만 physical frame에 올리면 프로그램 수행이 전혀 지장이 없다. 즉 이것때문에 physical memory의 공간 활용력을 극도로 끌어올리는 것임. 프로세스의 모든 이미지를 physical memory에 load안해도 프로세스들이 원할하게 작동함.
그런데, 프로세스가 진행함에 따라 바로 이 locality에 변화가 생긴다. locality가 이동을 하고 어떤 locality는 overlap이 되기도 하고 등등 많다.
thrashing이 왜 발생할까를 가만히 보면 현재 여러개 프로세스가 램에 적재되어있고, (frame 할당을 받고 있고) 램의 공간은 한계가 있다. 각각의 프로세스가 만일 로컬리티에 포함한 페이지만 담고 있으면 각각의 프로세스가 도는데 문제가 없다. locality에 포함되는 페이지라는 말은 결국 active하게 사용되는 페이지를 의미하고 만일 이 active하게 활용되는 페이지가 전체 램 공간의 양을 뛰어넘게 된다면 thrashing이 발생하게 되는 것이다. 이를 컨트롤하면 thrashing을 역으로 막을 수 있다.

로컬리티를 나타내는 아주 오래된 그림. 교수님 학부시절에 본 legacy 그림이라고 하심. x축은 시간이고 시간에 따라 어던 프로세스가 refer하는 page number을 쭉 찍은 것이다. 시간이 흘러가면서 그래프에 찍힌 부분의 페이지가 access된다는 의미.
그래프를 잘 살펴보면 page id 18~24번 까지가 하나의 locality, 그리고 24~ 30정도가 또다른 locality를 형성하고 있다. 시간에 따라 active하게 참조하는 locality가 변동됨을 알 수 있다.
가상 메모리 관점에서 살펴보면 위 그림에서 나타내는 프로세스를 위해 저정도 locality를 포함하는 페이지 수만 할당해주면 전혀 지장없이 돌아가게된다는 의미임.
Working set Model
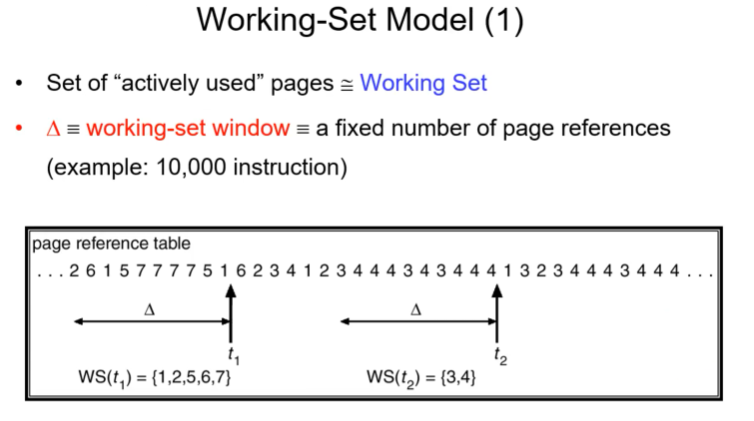
이러한 locality를 포함한다는 개념을 peter den이라는 분이 working set이라는 모델로 제시함.
active하게 사용되는 process page들을 working set이라 칭한다.
위 그림에서 숫자가 페이지 number라고 했을 때 t1시점에서의 working set을살펴보자. 과거 델타 정도의 시간 내에 빈번히 refer된 page는 1,2,5,6,7정도가 되겠다. 즉 5개정도의 페이지 locality 내에서 해결된다.
t2로 흐름에 따라 working set도 바뀌게 된다. 똑같은 델타 시간 동안 3,4 두개의 페이지로만 구성된다.
여기서 시사하는 바는 동일한 프로세스가 진행하는 동안에도 시점에 따라 working set이 다르다는 것이다. t1은 5사이즈 t2일때는 2사이즈 정도만 프로세스에 할당해주면 프로세스 진행에 문제가 없다.
델타는 working set window라고 칭한다.

working set size라는 것은 델타 시간동에 reference가 된 total number of page이다.이 모델에서 델타(window)의 정의가 중요한 이슈가 된다.
만약에 델타가 너무 작거나 크면 locality를 잘 담아낼 수 없을 것이다. 델타가 너무 작다면 locality자체를 확보 못할 것이며 너무 크다면 여러개의 locality를 담아내어 결과적으로 frame 낭비를 초래할 것이다.
WSS= working set size
Sigma WSSi를 D로 정의한다, (즉, D는 현재 n개의 프로세스가 프레임을 쓰고있다고 하면 각각의 프로세스의 working set size를 다 더한 것임. )
만일 D가 현재 physical memory의 frame 갯수보다 크다면 그때 thrashing이 발생하는 것이다.
OS는 thrashing을 피하기 위해 D > total number of frames inphysical memory를 활용한다. D값을 더 작게 만들면 된다. os는 working set을 잘 모니터링 해서 D가 절대 크지 않게끔 유지해야한다. 만일 D 가 임계치를 넘어서게 되면 어쩔수 없이 특정 프로세스를 찍어서 swap out해야하고 나머지 process들을 수행한 후 상황이 나아지면 다시 swap out한 프로세스를 다시 들여와 수행하게 된다
이상이 peter den이 제시한 working set model 이며 이런 철학을 리눅스에서도 활용중이다.

현실적으로 커널이 어떻게 프로세스의 working set을 잘 파악할까? 여기서도 cost, overhead를 최소화하면서 working set의 크기를 파악해야한다. 정확히 파악하려면 cost가 너무 드니까 LRU처럼 approximation을 하는 기법이 있다.
Sample LRU기법과 유사함. Internal timer을 두고 주기적으로 reference bit을 검토해서 working set을 판단하는 정책이다.
예를 들어 델타를 10000으로 두자. interval timer을 주어 5000 time때마다 interrupt를 준다. 그러면 첫번재 5000번 동안 page table에는 reference bit이 기록된다. 5000번 access하는 동안 page table 의 r bit가 기록이 될 것이고 5000번의 refernce가 끝나면 intervel timer가 들어오고 rbit를 그대로 카피해서 main memory에 기록을 해 둔다.
델타를 만으로 했기 때문에 메인 메모리에는 페이지당 두 비트를 둔다. 첫번째 비트는 첫 5000번 두번째 비트는 두번째 5000번을 기록하기 위한 비트이다. page당 두비트 메모리가 추가적으로 필요한 기법임.
결국 모든 페이지에 2비트가 기록될 것이다. 이 비트 기록으로 working set을 판단하는 기준으로 삼는다.(예를 들어 두 비트중 하나만 1이라면 working set 에 포함시키기 등)
5000번 timer 를 두기 떄문에 절대 정확한 working set이 될 수 없다. 완벽한 working set은 매 time cycle이 될 것이지만 너무나 overhead가 크다.
결국 compromise해야하는데 working set accuracy와 overhead간의 trade off 문제이다. 좀더 정밀하게 하려면 페이지 메모리 비트를 10개정도 추가 할당해서 1000 time마다 기록하게 하는 것을 생각해 볼 수 있음. 델타를 좀더 세분화하게 확인 가능.
Page Fault Frequency Allocation
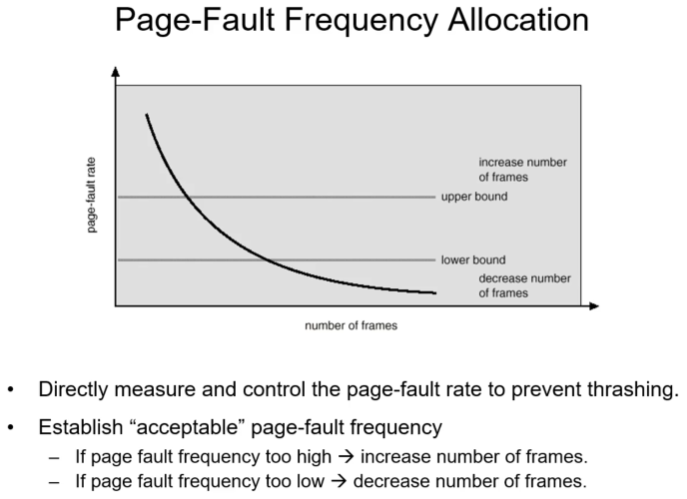
시스템이 페이지 fault rate를 알 수 있다. 어떤 프로세스가 page fault rate 가 높다면 그 프로세스에 할당된 페이지 수가 너무 적다는 의미이니 page frame을 더 준다. 반대로 page fault rate가 너무 낮다면 할당할 frame을 뺏는다.
이런 기법은 winows os가 부분적으로 제공하고 있음.
other issues

fundemental 한 가상메모리 이슈와 연관된 자잘한 이슈들이 있는데 그러한 이슈들을 살펴보고, 리눅스에서는 가상 메모리가 어떻게 구현되었는지 확인해 보자
PrePaging

미리미리 예측을 해서 내 프로세스가 활용할 페이지를 미리 physical frame에 가져다 놓겠다. page fault가 빌생하면 값비싼 하드디스크 operation을 동반하게 된다. 이때 어쩔 수 없이 hardware operation을 해야만 할 때, 앞으로 예상되는 working set을 한번에 physical frame에 넣어 놓는 기법이다.
Thrashing 상황이 발생하면, 해결을 위해 os에 의해 특정 프로세스가 swap out이 된다. 상황이 좋아진 후에 swap out 된 프로세스는 다시 들어오게 되는데 이때 원래 이론에 따르면 한번에 하나씩 fault가 발생할 때마다 page를 들여놓는다. 이 시점, 들여 놓는 상황에서 한 페이지 말고, out 되었을 시점에서의 working set을 알 수 있으니 working set을 통째로 가지고 들어오게 하는 기술이다..
이 상황에서 검토할 것은 역시 cost issue이다.
s가 prepaged 된 페이지 수라고 하고 알파가 prepaged 된 페이지 중 실제로 쓰인 비율이라 하자.( 알파 * s) 가 실제로 page fault를 예방한 것이고, (1-a)s가 쓸데없이 페이지를 로딩한 cost가 될 것이다. 즉 알파가 커질수록, (prepaging한 페이지가 hit를 많이 할수록) prepaged가 도움이 된 것이다. 알파를 높일 수 있는 형태로 prepaging 정책을 개발해야한다.
Page Size

인텔 아키텍쳐의 경우 4kb의 페이지 사이즈를 쓴다. 특수한경우는 4mb를 쓰기도 함. cpu마다 정하는 page size가 각기 다르다. 아키텍쳐를 설정 할때 페이지 크기를 결정해야하는데 어떤 기준으로 정할 것인지, 크게 정할 것인지 작게 정할것인지 , 각각의 장단점이 있다
이 슬라이드에서는 페이지 크기 정할 시 고려할 사항들을 나타낸다.
페이지 크기를 작게하는 경우.
- 장점: 페이지에 들어간 internal fragmentation이 작음. + locality 활용도가 높아서 memory효율이 늘어남.
- 단점: 페이지 테이블의 사이즈가 커진다. 메모리 오버헤드를 야기시킴. + 페이지 fault가 일어날 확률이 늘어남.
대부분 아키텍쳐가 일반적으로 4kb의 페이지 크기를 권장함.
Table Reach

TLB는 page table lookup을 빠르게 하기 위한 아주 비싼 하드웨어 컴포넌트이다. TLB hit가 일어나면 access overhead없이 address변환이 가능함. TLB Reach라고 함은 TLB 를 통해서 메인 메모리를 얼마만큼 access할 수 있는지 그 양을 말한다.
하나의 TLB entry가 하나의 page를 담당 가능.
TLB reach를 크게 하면 아주 빠른 시간에 많은 physical memory에 해당하는 address변환을 할 수 있다. 이상적으로는 process가 가지고 있는 working set을 TLB Reach 가 모두 커버할 수 있으면 좋다.
TLB Reach를 크게하는 법은 Page size를 늘리는 것이 있는데 이에 따른 장단점이 앞선 슬라이드에서 보았다시피 각각 존재함. 또다른 방법은 TLB size를 돈을 좀 더들여서 하드웨어를 크게 키우는 것이다.
현실적으로 쓰는 기법은 page size를 여러개 섞어 쓰는 것이다 . 예를 들어 여러 크기의 페이지 사이즈를 config 할 수 있다면, 작은 크기의 페이지 사이즈는 일반적인 프로세스를 위해, 큰 크기의 페이지 사이즈는 커널 코드를 다룰 때 쓰는 식으로 한다. 큰페이지나 작은 페이지나 TLB entry 한개에 대응되기 때문에 적절히 잘 효율적으로 섞어 쓰면 TLB Reach 값을 단점 없이 늘릴 수 있다.
Program Structure

page fault의 발생 빈도는 우리가 짜는 프로그램의 코드에 의해서도 좌우된다. 위의 슬라이드가 그 예시다. 우리가 프로그램을 잘 짜면 페이지 fault도 준다
integer 는 4byte 위 프로그램에서는 1024 1024사이즈 integer array이므로 각각의 row가 한 페이지에 할당한다.
두 프로그램 모두 array를 초기화 시키는데, program 1은 column major로, program 2는 row major로 초기화를 진행한다. program 1의 column major로 진행하게 된다면 매 루프마다 한번씩 page fault가 일어난다. 반면 row major로 짜면 첫번째 for문의 루프 수만큼만 page fault가 발생한다.(row 가 바뀔때만 page fault가 발생)
프로그래머가 하드웨어와 os의 메커니즘을 이해한다면 page fault를 줄일 수 있다. 사실은, 어떻게 짜든 위같은 상황의 문제는 발생하지 않는다. 현대에는 컴파일러가 똑똑하게 코드 변환을 효율적인 방향으로 해주기 때문임.
IO Interloc
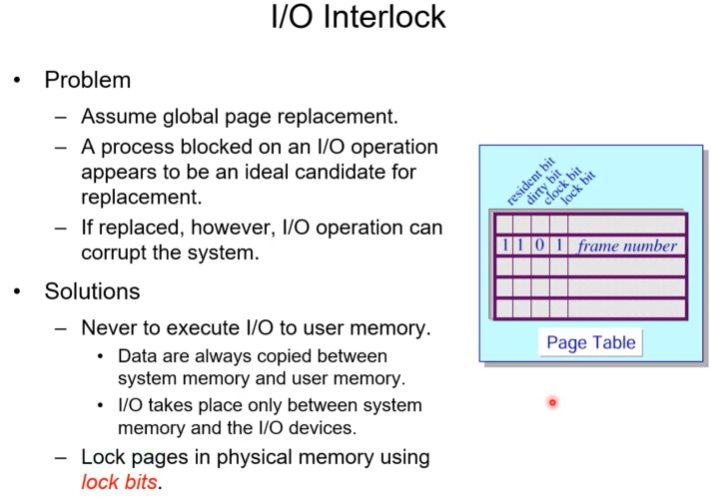
io가 발생하면 어떻게 되느냐의 이슈,
페이지 fault가 발생해서 특정 페이지를 victimize시키는데 victimize할 페이지가 io작업을 한다고 가정. 해당 페이지는 io작업이 끝날때까지 블록 상태, 즉 access가 이루어지지않을 것이기에 교체 대상으로 선정될 것이다. 하지만 만일 그 페이지가 쫓겨나면 io가 끝나고 돌아올때 문제가 된다.
가장 간단한 방법은 페이지에 lock bit를 주어 lock bit가 1이면 io작업을 담당하고 있는 부분이라는 의미이고 이 페이지를 절대 victimize하지 않게 구현하는 것이다.
좀더 근본적인 방법은 유저 메모리에서 io를 수행하는 게 아니라 system call 등으로 항상 커널이 io를 처리하게끔 구현하면 됨.
Benefits of Virtual Memory

가상메모리 상에서 프로세스를 생성 하면 fork operation을 더 효율적으로 할 수 있고 file을 다룰 때에도 효율적으로 access할 수 있는 이득이 있다.
copy on write
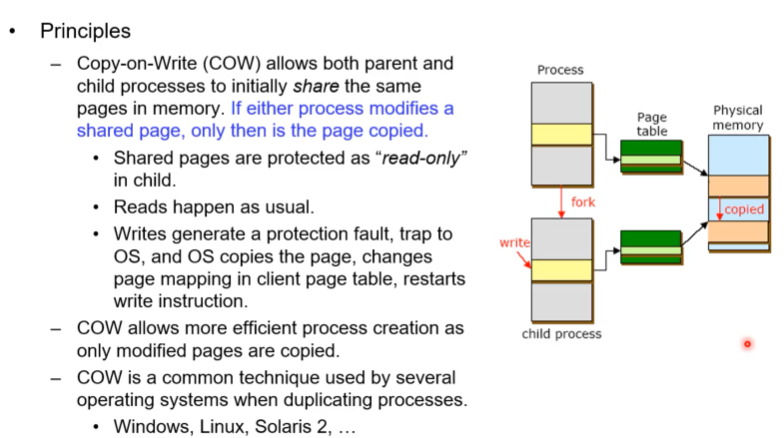
fork 관련해서 가상 메모리를 사용하면 얻을 수 있는 장점.
COW라는 semantic: copy on write. fork를 통해 child가 만들어지게 되는데 이떄 생성되는 child는 parent의 모든 이미지를 카피한다. 이러한 fork operation이 워낙 오버헤드가 크기 때문에 오버헤드를 줄이기 위한 여러가지 기법들이 만들어졌었음.
그런 기법중 하나가 copy on write라는 기법이다. fork하게 되면 그 즉시 child process를 모두 만드는 것이 아니라 child process에 대한 page table만 만들고, 실제 child process에 속하는 image copy는 아직 안하는 것이다.
언제까지 미루냐면 fork 후 parent 와 child의 process과정을 지켜보면서 결정한다. 만일 fork 후 parent-child process가 global data를 access하는데 둘 다 global data를 쓰지 않고 read만 하면, 실제로는 parent의 global data를 굳이 copy할 이유가 없는 것이다. 또한 code 도 마찬가지로 같은 맥락에서 read only이기 때문에 copy할 필요가 없다. read만 수행하면 시스템에서는 한 카피만 존재하면되고(parent) child process는 포인터만 유지하면 된다.
이러한 생각을 바탕으로 fork시 무작정 copy하는 것이 아니라 parent-child process 둘중 하나가 write 하는 순간에 그제서야 copy를 시작하는 것이다. copy on write. write하는 시점에 copy하자. 이렇게 하기 위해서는 기본적으로 global data에 대한 permmission을 read only로 두고 누가 쓰게(write) 되면 page fault가 발생하니 그제서야 copy하고 이전까지는 table만 유지하는 것이다.
이방법이 가능한 이유가 page table로 프로세스의 address를 공유할 수 있기 떄문이다. 이러한 기법은 윈도우 리눅스 등이 잘 활용중이다.
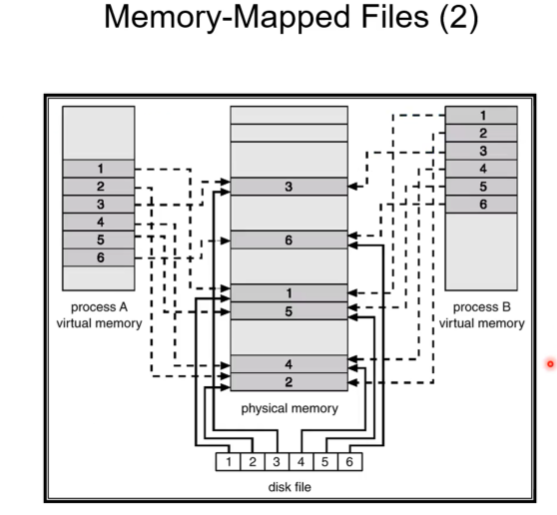
Memory Mapped File

또다른 장점은 file system에서 있다.
하드디스크의 file이 physical memory에 맵핑이 되어있다. 그래서 physical harddisk에 있는 파일의 일부분을 메인 메모리에 맵핑하고 cpu가 file에 access할때 실제 메인메모리의 내용으로 file에 access하겠다. mapping의 단위는 physical memory가 쓰고있는 현재 페이지의 크기가 될것이다. 파일을 페이지 단위로 쪼갠 후에 파일의 특정 부분을 피지컬 프레임에 맵핑해서 cpu가 file 내용에 access하는 방식인데 이러한 방식을 메모리 맵핑이라고 한다.
file io를 하면 system call을 사용한다. system call이 쓰여지면 커널모드로 가서 핸들러가 해당 파일을 access한다. blocking operation이기떄문에 현재 프로세스는 잠시 멈추고 커널에서 해당 sytstem call을 처리할때까지 기다리고 끝나면 다시 프로세스를 돌리게 된다. 이러한 시스템 콜 과정을 통한 상당히 오버헤드가 있는 파일 read operation을 해야함.
메모리 맵핑을 하면 파일이 ram에 있고 그말은 cpu가 곧바로 access할 수 있단 의미이다. 마치 instruction data를 load store하듯이 실제 메모리의 파일을 사용 가능한 것이다. 아주 빠르게 파일을 사용 가능
VM Data Structures in Linux
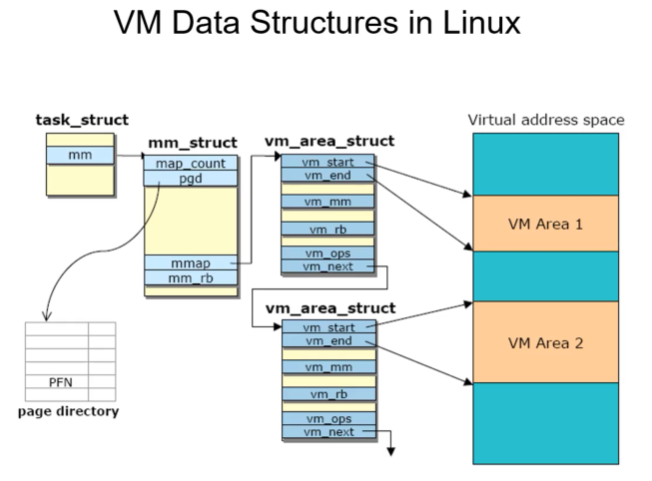
리눅스가 실제 가상메모리를 구현하는 법.
엄청 복잡하고 정교하게 구현되어있음 간단히 알아보자.
virtual address space는 4GB에 해당하는 linear address이다.(32비트 아키텍쳐) 그안에 VM area 1, 2가 있는데 이게 프로세스 이미지다.(코드일수도, 데이타 일수도 또는 스택일수도 등등.) 리눅스의 프로세스 이미지가 몇개의 virtual area로 정해져 있고 각각의 area가 vm_area_struct라는 커널 자료구조로 정해져있다. start, end point를 지니고 모두 연결리스트로 연결되어있다.(vm_next) 이 vm_area_struct를 mm_struct라는 자료구조가 reading한다. mm_struct의 추가정보는 pgd라는 것이 있는데 현재 내 프로세스의 base address가 어디인지를 가진다. 이외에도 많은 정보가 있고 mm_struct는 다시 task_struct(Process block)안에 mm 이라는 포인터에 저장되어있다. 리눅스 커널이 가상메모리 구현하기 위해 가진 자료구조이다.
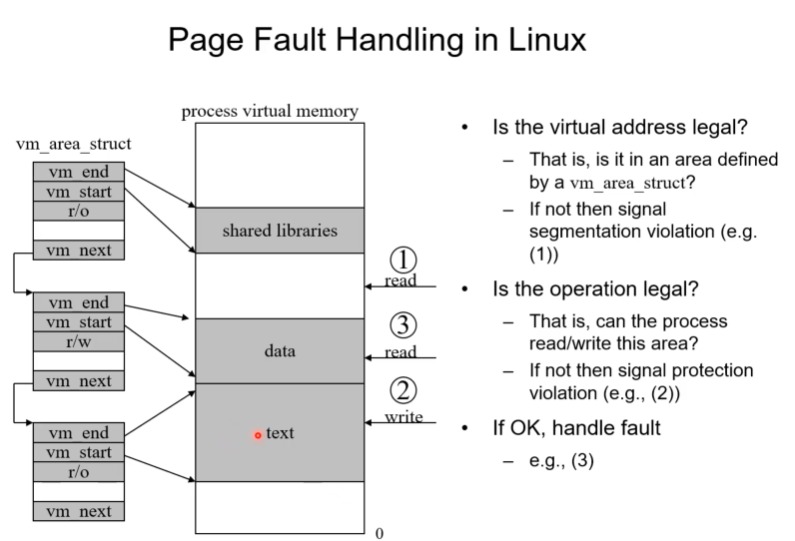
리눅스에서의 페이지 fault 핸들링을 간단히 설명해 보자
vm_area_struct는 각각 vm_area에 맵핑되어있고 추가적으로 permission같은 정보를 지님(read only, write 가능 등) 이런 상황에서 1,2,3의 경우 page fault가 발생하는 것을 보여준다. 1,2,3의경우 왜 페이지 fault가 발생했는가.
1번 상황은 프로그램이 어떠한 이유로 illegal 한 address에 접근한 경우이다. 전체 linear address중에 valid한 영역이 아니라 pc가 이상한곳에 접근한 것이다. exception을 발생시킴. 발생한 이유는 프로그래머 잘못임. 해당 프로세스는 종료된다.(sementation fault)
2번 상황은 valid한 공간을 access하는 중이긴 하다. mmu가 page fault를 콜한 이유는 access write violation이다. readonly인 text area에 write을 시도했기 때문. 이경우에도 프로세스는 커널에 의해 permission이 deny된다.
3번 상황은 정상적인 page fault이다.해당 페이지가 physical frame에 없는 상황으로, 우리가 공부한 demanding paging에서의 page fault상황인 것이다. Excpetion handler가 해당 페이지를 업데이트 해줌.
위 모든 상황을 커널이 관리함.

리눅스의 페이지 교체 정책.
다른 운체와 마찬가지로 LRU를 사용한다. 기술적으로는 inactive list, active_list를 두어 빈번히 쓰는페이지를 정해놓음 구체적인 것은 생략.
실제 os에서는 page fualt시 빈 프레임을 확보하는 것이 아니라 항상 일정량의 빈 프레임을 미리 확보한다. 이를 위한 여러가지 커널 스레드가 백그라운드에서 돌고 있다.
아주 구체적인 것은 생략.
댓글남기기